概述从浏览器地址栏输入url到显示页面的步骤(以HTTP为例)
- 在浏览器地址栏输入URL
- 浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
- 如果资源未缓存,发起新请求
- 如果已缓存,检验是否足够新鲜,足够新鲜直接提供给客户端,否则与服务器进行验证。
- 检验新鲜通常有两个HTTP头进行控制
Expires和Cache-Control:- HTTP1.0提供Expires,值为一个绝对时间表示缓存新鲜日期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大新鲜时间
- 浏览器解析URL获取协议,主机,端口,path
- 浏览器组装一个HTTP(GET)请求报文
- 浏览器获取主机ip地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
- 打开一个socket与目标IP地址,端口建立TCP链接,三次握手如下:
- 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
- TCP链接建立后发送HTTP请求
- 服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
- 服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
- 处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
- 服务器将响应报文通过TCP连接发送回浏览器
- 浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次握手如下:
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y, Seq=X报文
- 浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
- 如果资源可缓存,进行缓存
- 对响应进行解码(例如gzip压缩)
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none - 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
- js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本禁止使用document.write(),它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readyState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readyState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
1.TCP HTTP UDP三者的关系
都是通信协议,也就是通信时所遵守的规则,只有双方按照这个规则“说话”,对方才能理解或为之服务。
TCP/IP是个协议组,可分为四个层次:网络接口层、网络层、传输层和应用层。
在网络层有IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
在传输层中有TCP协议与UDP协议。
在应用层有FTP、HTTP、TELNET、SMTP、DNS等协议。
因此,HTTP本身就是一个协议,是从Web服务器传输超文本到本地浏览器的传送协议。
2.socket
套接字(socket)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
socket只是一种连接模式,不是协议,tcp,udp,简单的说(虽然不准确)是两个最基本的协议,很多其它协议都是基于这两个协议如,http就是基于tcp的,用socket可以创建tcp连接,也可以创建udp连接,这意味着,用socket可以创建任何协议的连接,因为其它协议都是基于此的。
由于通常情况下Socket连接就是TCP连接,因此Socket连接一旦建立,通信双方即可开始相互发送数据内容,直到双方连接断开。
3.建立TCP连接-三次握手
位码即tcp标志位,有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急)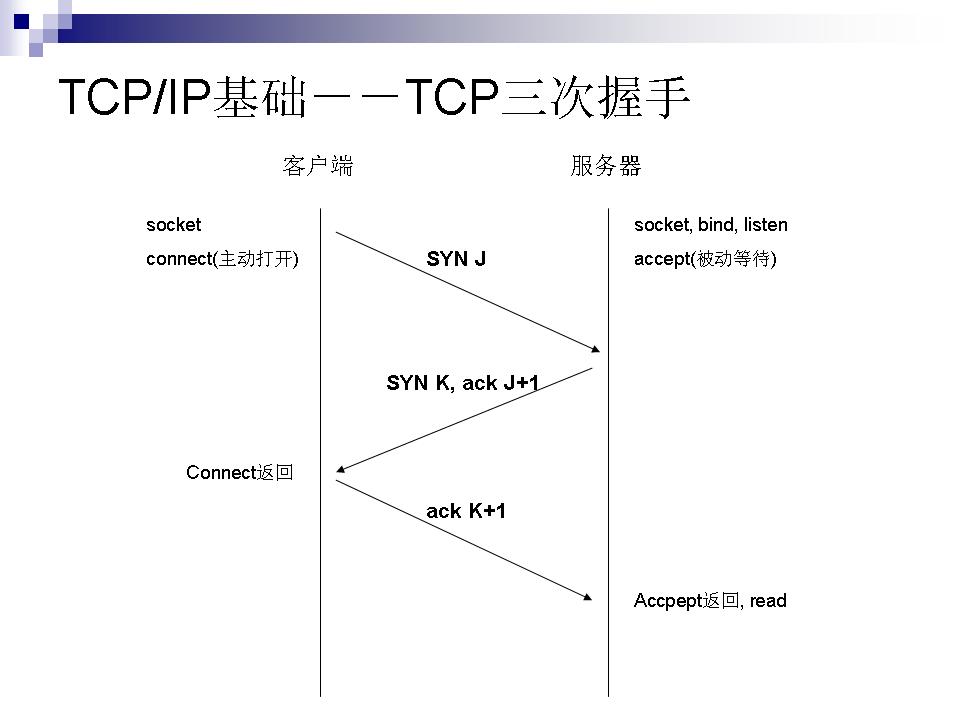
Sequence number(顺序号码) Acknowledge number(确认号码)
第一次握手:主机A发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),syn=1,ack=1,随机产生seq=7654321的包
第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值与ack=1则连接建立成功。完成三次握手,主机A与主机B开始传送数据。
4.什么是Http协议
HTTP全称是HyperText Transfer Protocal,即:超文本传输协议,从1990年开始就在WWW上广泛应用,是现今在WWW上应用最多的协议, Http是应用层协议,当你上网浏览网页的时候,浏览器和Web服务器之间就会通过HTTP在Internet上进行数据的发送和接收。Http是一个基于请求/响应模式的、无状态的协议。
5.HTTP传输全过程
(1)建立TCP连接-三次握手
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80
(2) Web浏览器向Web服务器发送请求命令
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令
例如:GET/sample/hello.jsp HTTP/1.1
(3) Web浏览器发送请求头信息
浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,表示它已经结束了该头信息的发送。
(4) Web服务器应答
客户机向服务器发出请求后,服务器会客户机回送应答,
HTTP/1.1 200 OK
应答的第一部分是协议的版本号和应答状态码
(5) Web服务器发送应答头信息
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
(6) Web服务器向浏览器发送数据
Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
(7) Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
6.HTTP请求报文
(1)请求报文结构
HTTP的请求报文由3部分组成(请求行+请求头+请求体):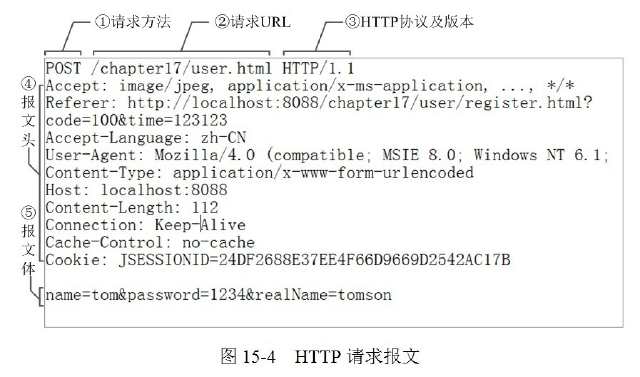
① 是请求方法,GET和POST是最常见的HTTP方法,除此以外还包括DELETE、HEAD、OPTIONS、PUT、TRACE。不过,当前的大多数 浏览器只支持GET和POST,Spring 3.0提供了一个HiddenHttpMethodFilter,允许你通过“_method”的表单参数指定这些特殊的HTTP方法(实际上还是通过 POST提交表单)。服务端配置了HiddenHttpMethodFilter后,Spring会根据_method参数指定的值模拟出相应的HTTP 方法,这样,就可以使用这些HTTP方法对处理方法进行映射了。
②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL
③是协议名称及版本号。
④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。
⑤ 是报文体,它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个 请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“/chapter15/user.html? param1=value1¶m2=value2”的方式传递请求参数。
对照上面的请求报文,我们把它进一步分解,你可以看到一幅更详细的结构图: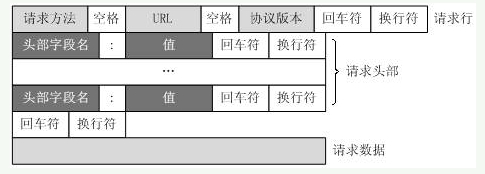
(2)请求报文头属性
举例:
快到中午了,张三丰不想去食堂吃饭,于是打电话叫外卖:老板,我要一份[鱼香肉丝],要12:30之前给我送过来哦,我在江湖湖公司研发部,叫张三丰。
这里,你要[鱼香肉丝]相当于HTTP报文体,而“12:30之前送过来”,你叫“张三丰”等信息就相当于HTTP的报文头。它们是一些附属信息,帮忙你和饭店老板顺利完成这次交易。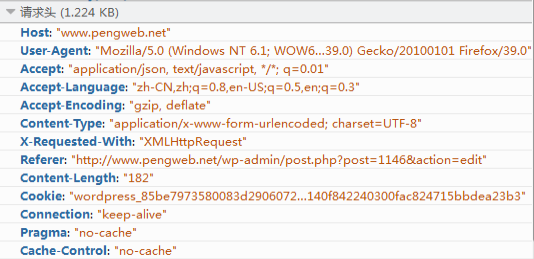
1 | Host: //访问的域名 |
7.HTTP响应报文
(1)响应报文结构
HTTP的响应报文也由三部分组成(响应行+响应头+响应体):
①报文协议及版本;
②状态码及状态描述;
③响应报文头,也是由多个属性组成;
④响应报文体,即我们真正要的“干货”。
(2)响应报文头属性
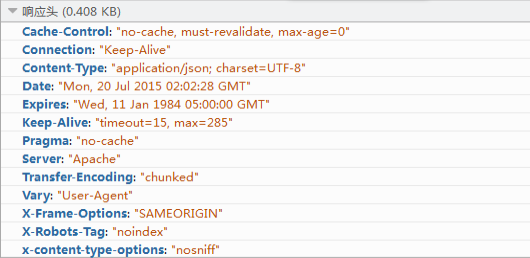
1 | Date: //服务端响应客户端的时间 |
更多请求报文头属性
参见:http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
8.状态码
1 | * 1xx:代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行 结束。 |
更多状态码参考:http://tool.oschina.net/commons?type=5
9.HTTP事务全过程
域名解析 → 发起TCP的3次握手 → 建立TCP连接后发起http请求 → 服务器响应http请求,浏览器得到html代码 → 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) → 浏览器对页面进行渲染呈现给用户
(1)域名解析
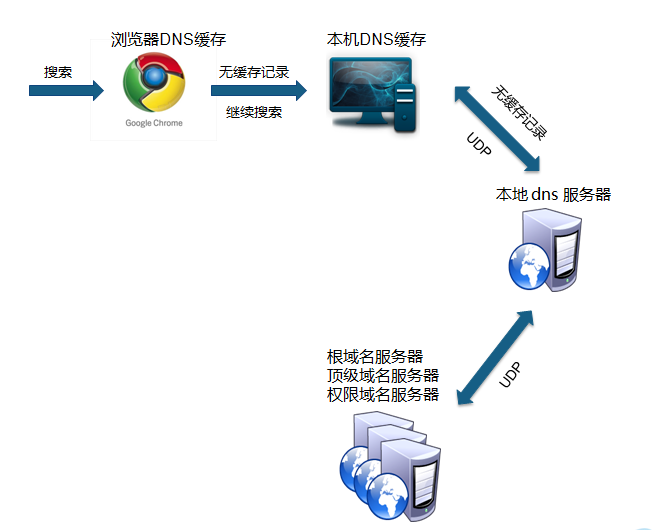
- Chrome浏览器 会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有www.pengweb.net 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
查看Chrome自身的缓存1
chrome://net-internals/#dns
- 如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
Windows系统查看操作系统自身的DNS缓存,命令行下使用1
ipconfig /displaydns
如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
host
→ 向本地配置的首选DNS服务器(电信)发起域名请求
→ (通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求)运营商本的DNS服务器查找自身缓存,如果没有
→ 运营商代替我们,查找根域的NDS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地 址)
→不知道这个域名IP地址,但是知道com域的IP地址,去找它
→ 域名的DNS地址(万网)
→ 找到的结果发送给运营商的DNS服务器
→ window系统
→ 浏览器
2.发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过 TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。主要目的是证明两个协议相同,这样才能进行通信。
如下图: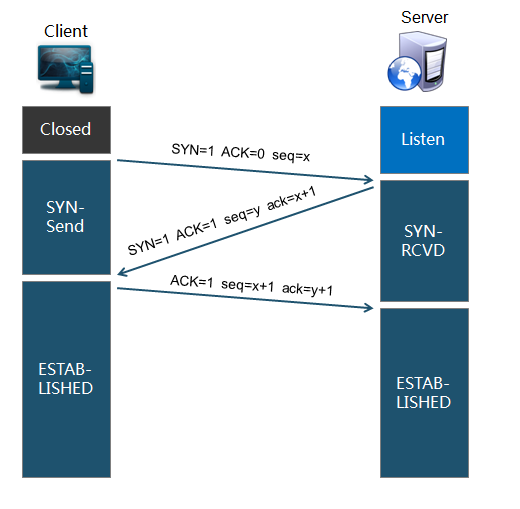
1) Client首先发送一个连接试探,ACK=0 表示确认号无效,SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据,seq = x 表示Client自己的初始序号(seq = 0 就代表这是第0号包),这时候Client进入syn_sent状态,表示客户端等待服务器的回复
2) Server监听到连接请求报文后,如同意建立连接,则向Client发送确认。TCP报文首部中的SYN 和 ACK都置1 ,ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到(ack=1其实是ack=0+1,也就是期望客户 端的第1个包),seq = y 表示Server 自己的初始序号(seq=0就代表这是服务器这边发出的第0号包)。这时服务器进入syn_rcvd,表示服务器已经收到Client的连接请求,等待 client的确认。
3) Client收到确认后还需再次发送确认,同时携带要发送给Server的数据。ACK 置1 表示确认号ack= y + 1 有效(代表期望收到服务器的第1个包),Client自己的序号seq= x + 1(表示这就是我的第1个包,相对于第0个包来说的),一旦收到Client的确认之后,这个TCP连接就进入Established状态,就可以发起 http请求了。
看抓包截图:
9 号包 这个就是对应上面的步骤 1)
10 号包 这个对应的上面的步骤 2)
11 号包 这个对应的上面的步骤 3)
3.建立TCP连接后发起http请求
进过TCP3次握手之后,浏览器发起了http的请求(看第包),使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0
下面是第12号包的详细内容: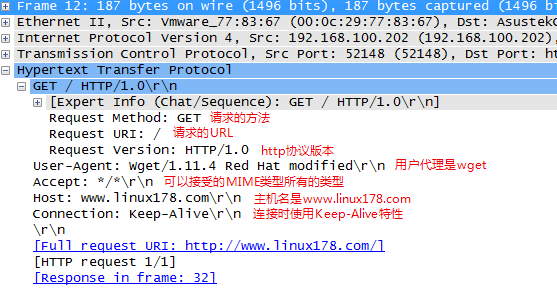
1.请求方法:
用来定义操作资源的方式,HTTP/1.1 协议中定义了八种请求方法:
- GET:读取资源数据
- POST:新建资源数据
- PUT:更新资源数据
- DELETE:删除资源数据
- HEAD:读取资源的元数据
- OPTIONS:读取该资源所支持的所有请求方法
- TRACE:回显服务器收到的请求,主要用于测试或诊断
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经
由非加密的HTTP代理服务器)
此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。
资源标示符URI、URL和URN是用来识别、定位和命名互联网上的资源。
因为要通过多样的方式识别资源(人的名字可能相同,然而计算机文件只能通过唯一的路径名称组合访问),所以需要标准的识别WWW资源的途径。为了满足这种需要,Tim Berners-Lee 引入了标准的识别、定位和命名的途径:URI、URL和URN。
- URI:Uniform Resource Identifier,统一资源标识符
URL:Uniform Resource Locator,统一资源定位符
1
2
3//格式如下
scheme://[username:password@]HOST:port/path/to/source
http://www.magedu.com/downloads/nginx-1.5.tar.gzURN:Uniform Resource Name,统一资源名称
URL 和 URN 都属于 URI。
URI 和 URL 的区别是:URL 更具体。URI 和 URL 都定义了什么是资源。但 URL 还定义了如何获得资源。
2.请求协议
有以下几种:
http/0.9: stateless
http/1.0: MIME, keep-alive (保持连接), 缓存
http/1.1: 更多的请求方法,更精细的缓存控制,持久连接(persistent connection) 比较常用
3.请求头上边已经介绍过了,下边做一些补充
条件请求首部:
If-Modified-Since 是浏览器向服务器端询问某个资源文件如果自从什么时间修改过,那么重新发给我,这样就保证服务器端资源文件更新时,浏览器再次去请求,而不是使用缓存中的文件
安全请求首部:
Authorization: 客户端提供给服务器的认证信息;
4.什么是MIME?
MIME(Multipurpose Internet Mail Extesions 多用途互联网邮件扩展)是一个互联网标准,它扩展了电子邮件标准,使其能够支持非ASCII字符、二进制格式附件等多种格式的邮件消息,这个标准被定义在 RFC 2045、RFC 2046、RFC 2047、RFC 2048、RFC 2049等RFC中。 由RFC 822转变而来的RFC 2822,规定电子邮件标准并不允许在邮件消息中使用7位ASCII字符集以外的字符。正因如此,一些非英语字符消息和二进制文件,图像,声音等非文字消 息都不能在电子邮件中传输。MIME规定了用于表示各种各样的数据类型的符号化方法。 此外,在万维网中使用的HTTP协议中也使用了MIME的框架,标准被扩展为互联网媒体类型。
MIME 遵循以下格式:major/minor 主类型/次类型 例如:
1.image/jpg
2.image/gif
3.text/html
4.video/quicktime
5.appliation/x-httpd-php
4.服务器端响应http请求,浏览器得到html代码
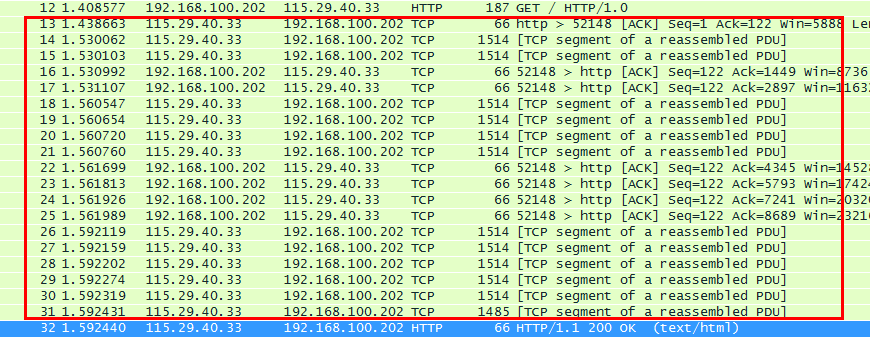
看上图 第12号包是http请求包,第32包是http响应包
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
第32号包 是服务器返回给客户端http响应包(200 ok 响应的MIME类型是text/html),代表这一次客户端发起的http请求已成功响应。200 代表是的 响应成功的状态码。
那到底服务器端接收到http请求后是怎么样生成html文件?
假设服务器端使用nginx+php(fastcgi)架构提供服务
- nginx读取配置文件
我们在浏览器的地址栏里面输入的是 http://www.pengweb.net(http://可以不用输入,浏览器会自动帮我们添加),其实完整的应该是http://www.linux178.com./ 后面还有个点(这个点代表就是根域,一般情况下我们不用输入,也不显示),后面的/也是不用添加,浏览器会自动帮我们添加(且看第3部那个图里面的 URL),那么实际请求的URL是http://www.pengweb.net/,那么好了Nginx在收到 浏览器 GET / 请求时,会读取http请求里面的头部信息,根据Host来匹配 自己的所有的虚拟主机的配置文件的server_name,看看有没有匹配的,有匹配那么就读取该虚拟主机的配置,发现如下配置:
1 | root /web/echo |
通 过这个就知道所有网页文件的就在这个目录下 这个目录就是/ 当我们http://www.pengweb.net/时就是访问这个目录下面的文件,例如访问http://www.pengweb.net /index.html,那么代表/web/echo下面有个文件叫index.html1
index index.html index.htm index.php
通过这个就能得知网站的首页文件是那个文件,也就是我们在入http://www.pengweb.net/ ,nginx就会自动帮我们把index.html(假设首页是index.php 当然是会尝试的去找到该文件,如果没有找到该文件就依次往下找,如果这3个文件都没有找到,那么就抛出一个404错误)加到后面,那么添加之后的URL是 /index.php,然后根据后面的配置进行处理1
2
3
4
5
6
7location ~ .*\.php(\/.*)*$ {
root /web/echo;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
astcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
这一段配置指明凡是请求的URL中匹配(这里是启用了正则表达式进行匹配) *.php后缀的(后面跟的参数)都交给后端的fastcgi进程进行处理。
2.把php文件交给fastcgi进程去处理
于 是nginx把/index.php这个URL交给了后端的fastcgi进程处理,等待fastcgi处理完成后(结合数据库查询出数据,填充模板生成 html文件)返回给nginx一个index.html文档,Nginx再把这个index.html返回给浏览器,于是乎浏览器就拿到了首页的 html代码,同时nginx写一条访问日志到日志文件中去。
注1:nginx是怎么找index.php文件的?
当 nginx发现需要/web/echo/index.php文件时,就会向内核发起IO系统调用(因为要跟硬件打交道,这里的硬件是指硬盘,通常需要靠内 核来操作,而内核提供的这些功能是通过系统调用来实现的),告诉内核,我需要这个文件,内核从/开始找到web目录,再在web目录下找到echo目录, 最后在echo目录下找到index.php文件,于是把这个index.php从硬盘上读取到内核自身的内存空间,然后再把这个文件复制到nginx进 程所在的内存空间,于是乎nginx就得到了自己想要的文件了。
注2:寻找文件在文件系统层面是怎么操作的?
比如nginx需要得到/web/echo/index.php这个文件
每个分区(像ext3 ext3等文件系统,block块是文件存储的最小单元 默认是4096字节)都是包含元数据区和数据区,每一个文件在元数据区都有元数据条目(一般是128字节大小),每一个条目都有一个编号,我们称之为 inode(index node 索引节点),这个inode里面包含 文件类型、权限、连接次数、属主和数组的ID、时间戳、这个文件占据了那些磁盘块也就是块的编号(block,每个文件可以占用多个block,并且 block不一定是连续的,每个block是有编号的),如下图所示: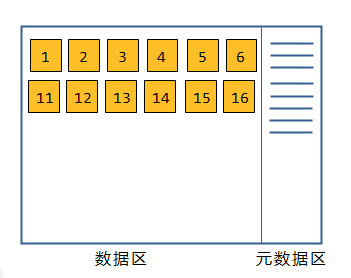
还有一个要点:目录其实也普通是文件,也需要占用磁盘块,目录不是一个容器。你看默认创建的目录就是4096字节,也就说只需要占用一个磁盘块,但这是不确定的。所以要找到目录也是需要到元数据区里面找到对应的条目,只有找到对应的inode就可找到目录所占用的磁盘块。
那到底目录里面存放着什么,难道不是文件或者其他目录吗?
其实目录存着这么一张表(姑且这么理解),里面放着 目录或者文件的名称和对应的inode号(暂时称之为映射表),如下图:
假设1
2
3
4/ 在数据区占据 1、2号block ,/其实也是一个目录 里面有3个目录 web 111
web 占据 5号block 是目录 里面有2个目录 echo data
echo 占据 11号 block 是目录 里面有1个文件 index.php
index.php 占据 15 16号 block 是文件
其在文件系统中分布如下图所示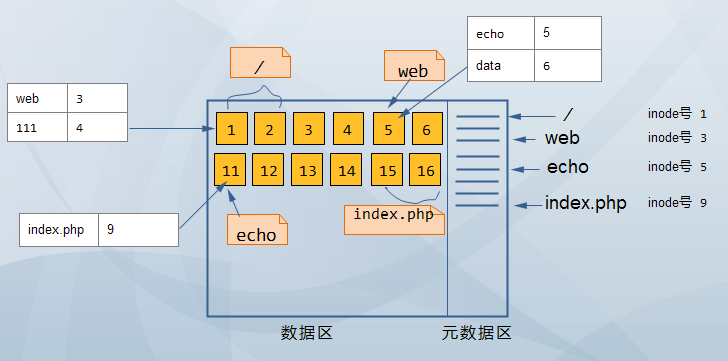
那么内核究竟是怎么找到index.php这个文件的呢?
内核拿到nginx的IO系统调用要获取/web/echo/index.php这个文件请求之后
1.内核读取元数据区 / 的inode,从inode里面读取/所对应的数据块的编号,然后在数据区找到其对应的块(1 2号块),读取1号块上的映射表找到web这个名称在元数据区对应的inode号
2.内核读取web对应的inode(3号),从中得知web在数据区对应的块是5号块,于是到数据区找到5号块,从中读取映射表,知道echo对应的inode是5号,于是到元数据区找到5号inode
3.内核读取5号inode,得到echo在数据区对应的是11号块,于是到数据区读取11号块得到映射表,得到index.php对应的inode是9号
4.内核到元数据区读取9号inode,得到index.php对应的是15和16号数据块,于是就到数据区域找到15 16号块,读取其中的内容,得到index.php的完整内容
5.浏览器解析html代码,并请求html代码中的资源
浏 览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程 下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里 的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。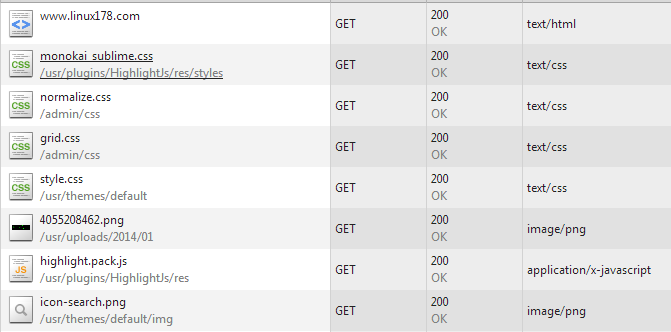
浏览器工作原理参考:http://kb.cnblogs.com/page/129756/
6.TCP连接释放
在正常情况下,服务器端的keep-alive过时了,就会主动发出请求释放这条TCP连接。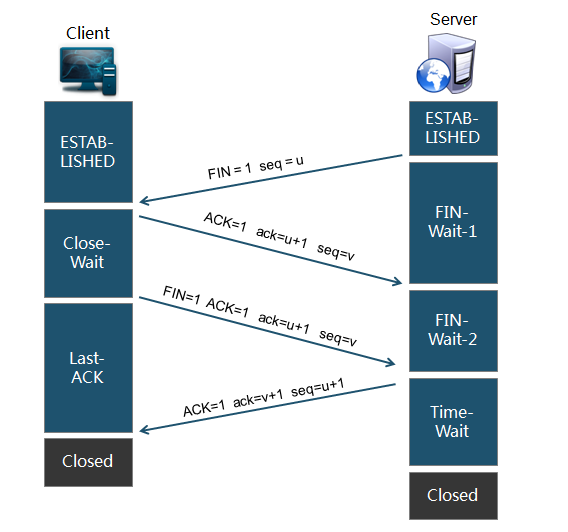
1.Server发送一个连接释放报文,FIN = 1 表示Server的数据已发送完毕,seq = v ,v等于前面已传送过的数据的最后一个字节加1。
2.Client收到Server的连接释放请求后,发送一个确认报文。ACK = 1 表示确认后ack有效,ack = u+1表示期望收到对方下一个报文段的第一个数据字节序号是u+1 ,seq = v , v等于前面Client已传送过的数据的最后一个字节加1。
3.由于HTTP协议是基于请求-响应模型,所以这时Client再发送请求数据给Server已经无效了,因为Server到Client的TCP连接已关闭,不会再发送响应了。这里的Close-Wait大概是等待主机通知关闭这次TCP连接。
4.接下来Client就发送一个连接释放给Server,FIN=1,ACK=1,ack = u + 1 与之前发送给Server的确认号一样。这里的seq = v 也与之前的一样。(个人认为Close-Wait期间Client不会再发送数据给Server,所有数据序号并没有发生改变,正确与否有待考证)
5.Server收到连接释放报文后,便发送一个确认报文。然后进入Time-Wait,而不是立即关闭连接,原因是不保证这个确认报文没有丢失,而Client收不到确认报文则执行超时重传FIN+ACK,这时Server还未关闭,就可以重传ACK。
7.浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
自此一次完整的HTTP事务宣告完成.