上册
1 作用域是什么
1.1 编译原理
js与传统的编译语言不同,它不是提前编译的,即编译过程不是发生在构建之前的,而是在执行前几微秒钟内的,编译结果也不能在分布式系统中进行移植。
JavaScript 引擎用尽了各种办法(比如 JIT,可以延迟编译甚至实施重编译)来保证性能最佳。
三个步骤。统称为编译
- 分词/词法分析
var a = 2;
被分解为下面这些词法单元
var、a、=、2、; - 解析/语法分析
将词法单元(数组)转换成一个代表了程序语法结构的树,称为“抽象语法树(AST)”
var a = 2; 的语法树
顶级节点-VariableDeclaration
子节点-Identifier //a
子节点-AssignmentmentExpression //=
子节点NumericLiteral //2 (AssignmentmentExpression的子节点) - 代码生成
将 AST 转换为可执行代码的过程称被称为代码生成。
将var a = 2;的 AST 转化为一组机器指令,用来创建一个叫作 a 的变量(包括分配内存等),并将一个值储存在 a 中。
1.2 理解作用域
引擎:负责整个 JavaScript 程序的编译及执行过程。
编译器:负责语法分析及代码生成等脏活累活。 //我觉得编译器是包含在引擎内的
作用域:负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限
过程:
编译→(询问有无作用域)→无→声明新变量(var a)→为引擎生成运行时所需的代码(处理a = 2)→引擎→(询问当前作用域集合中有无作用域)→无→报错
LHS查询:当变量出现在赋值操作的左侧时进行LHS查询。
RHS查询:出现在右侧时进行RHS查询1
2
3
4
5
6
7console.log(a) //a为RHS查询
a = 2 //a 为LHS查询
function foo(a) { //这里进行了一次 隐式分配值,进行的是LHS查询
console.log( a ); // 这里是RHS查询
}
foo( 2 );
为什么区分?区分意义何在?
如果 RHS 查询在所有嵌套的作用域中遍寻不到所需的变量,引擎就会抛出 ReferenceError异常。
值得注意的是, ReferenceError 是非常重要的异常类型。
如果 LHS 查询不到的话,则会声明(var)一个,前提非严格模式
严格模式禁止自动或隐式的创建全局变量!!
ReferenceError 同作用域判别失败相关,而 TypeError 则代表作用域判别成功了,但是对结果的操作是非法或不合理的。
对 undefined 值进行函数调用而导致非法操作,会抛出 TypeError 异常。
2. 词法作用域
作用域分为:词法作用域和动态作用域
词法作用域取决于你写代码时将变量和块作用域写在哪里决定的。(函数嵌套)
如果有同名变量,其中一个在全局作用域上,可以通过window.a的形式来访问全局作用域上的同名变量
欺诈词法:eval、with
JavaScript 中 还 有 其 他 一 些 功 能 效 果 和 eval(..) 很 相 似。 setTimeout(..) 和setInterval(..) 的第一个参数可以是字符串,字符串的内容可以被解释为一段动态生成的
函数代码。这些功能已经过时且并不被提倡。不要使用它们!
3.函数作用域和块作用域
3.2 规避冲突
3.2.1 全局命名空间
声明一个独特名字的变量,通常是一个对象,这个对象被用作库的命名空间,所有需要暴露给外界的功能都会成为这个对象(命名空间)的属性,而不是将自己的标识符暴漏在顶级的词法作用域中。
3.2.2 模块化
第五章详细介绍。
3.3 函数作用域
区分函数声明和表达式最简单的方法:
是看 function 关键字出现在声明中的位置(不仅仅是一行代码,而是整个声明中的位置) 。
如果 function 是声明中的第一个词,那么就是一个函数声明,否则就是一个函数表达式。
函数声明和函数表达式之间最重要的区别是它们的名称标识符将会绑定在何处。
自执行函数-绑定在自身函数上
3.3.1 匿名和具名
匿名函数表达式: function().. 没有名称标识符
具名函数表达式: function().. 有名称标识符
匿名缺点:
- 调试困难
- 引用自身只能用过时的arguments.callee
- 事件监听需要解绑的时候
- 可读性变差
3.3.2 立即执行函数表达式
IIFE:立即执行函数表达式
(function(){})() 和(function(){}()) 功能一样,推荐第一种
通常用法就不说了,解决 undefined 标识符的默认值被错误覆盖导致的异常 (虽然不常见) 。将一个参数命名为 undefined ,但是在对应的位置不传入任何值,这样就可以保证在代码块中 undefined 标识符的值真的是 undefined
还有另外一种是当作参数传入,传入值可以是一个函数
3.4 块作用域
1 | for (var i=0; i<10; i++) { |
3.4.1 with、try/catch 拥有作用域的特殊语法
try / catch 的 catch 分句会创建一个块作
用域,其中声明的变量仅在 catch 内部有效, err 仅存在 catch 分句内部,当试图从别处引用它时会抛出错误
3.3.3 let
let 关键字可以将变量绑定到所在的任意作用域中(通常是 { .. } 内部) 。
换句话说, let为其声明的变量隐式地劫持了所在的块作用域。
隐式 let是隐式的
显式 ES6的{} 是显式的
通过{}为let创建一个用于绑定的块,且一般let都放在{}内部的顶部,那样你的块作用域就更健壮很容易辨识和维护。
let声明不会作用域中进行提升
if(..) { let a = 2; }
let会声明一个劫持了 if 的 { .. } 块的变量,并且将变量添加到这个块中。
for(let i=0;..){}也是一样
3.3.3.1 垃圾回收
1 | function process(data) { |
3.3.3.2 let循环
1 | for (let i=0; i<10; i++) { |
for 循环头部的 let 不仅将 i 绑定到了 for 循环的块中,事实上它将其重新绑定到了循环的每一个迭代中,确保使用上一个循环迭代结束时的值重新进行赋值。
let 声明附属于一个新的作用域而不是当前的函数作用域(也不属于全局作用域)
3.4.4 const
同样可以用来创建块作用域变量,但其值是固定的常量。1
2
3
4
5
6
7
8
9var foo = true;
if (foo) {
var a = 2;
const b = 3; // 包含在 if 中的块作用域常量
a = 3; // 正常 !
b = 4; // 错误 ! 因为是 常量
}
console.log( a ); // 3
console.log( b ); // ReferenceError! 创建了块级作用域,所以外部访问不到
4 提升
4.2 编译器
包括变量和函数在内的所有声明都会在任何代码被执行前首先被处理。
表达式不会被提升!!
var a = 2;
实际上会将其看成两个声明: var a; 和 a = 2; 。
第一个定义声明是在编译阶段进行的。
第二个赋值声明会被留在原地等待执行阶段。
4.3 函数优先
函数声明和变量声明都会被提升。
但是一个值得注意的细节(这个细节可以出现在有多个重复声明的代码中)是函数会首先被提升,然后才是变量。1
2
3
4
5
6
7var foo = function(){
console.log( 2 );
};
foo(); // 2 函数声明先提升上去,然后才是变量声明的,变量声明的foo覆盖了函数声明的,所以是2
function foo() {
console.log( 1 );
}
避免在if或者for语句的{}中声明,因为这样会提升到顶部,导致一些不可预测的问题
引擎将 var a 和 a = 2 当作两个单独的声明,第一个是编译阶段的任务,而第二个则是执行阶段的任务。
5.作用域闭包
定义:当函数可以记住并访问所在的词法作用域,即使函数是在当前词法作用域之外执行,这时就产生了闭包。
网上搜集的定义:
闭包就是能够读取其他函数内部变量的函数。
在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
5.2 实质问题
1 | //第一种传递 |
5.3
当将函数作为参数到处传递的时候,就已经产生了闭包!
在定时器、事件监听器、Ajax 请求、跨窗口通信、Web Workers 或者任何其他的异步(或者同步)任务中,只要使用了回调函数,实际上就是在使用闭包!
IIFE就是典型的闭包例子,但是严格来讲并不是闭包
因为函数并不是在它本身的词法作用域以外执行的
5.4 循环和闭包
循环中的i都被封闭在一个共享的全局作用域中,因此实际上只有一个 i 。
主要原因:回调函数或者setTimeout,他们是在for循环结束后才执行的。
所以需要闭包来创建作用域1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//方法一
for (var i=1; i<=5; i++) {
(function() { //可以没有参数,因为里边的j可以直接访问外边的i
var j = i; //j的作用域赋值为当时的i
setTimeout( function timer() {
console.log( j );
}, j*1000 );
})();
}
//方法二
for (var i=1; i<=5; i++) {
(function(j) { //这里必须有参数,因为外边要传i进来给这个,归根结底都是j=i
setTimeout( function timer() {
console.log( j );
}, j*1000 );
})( i ); //改良版,将i作为参数传进入
}
let可以劫持作用域,相当于IIFE,所以上边可以这么写1
2
3
4
5
6
7
8
9
10
11
12for (var i=1; i<=5; i++) {
let j = i; // 是的,闭包的块作用域!
setTimeout( function timer() {
console.log( j );
}, j*1000 );
}
//上边那个变量在循环过程中会声明不止一次,所以进行了调整
for (let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
5.5 模块
模块暴露来实现模块1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function CoolModule() {
var something = "cool";
var another = [1, 2, 3];
function doSomething() {
console.log( something );
}
function doAnother() {
console.log( another.join( " ! " ) );
}
//这里不一定返回一个对象,也可以返回一个函数,jquery就是一个很好的例子
return { //这里进行了模块暴露
doSomething: doSomething,
doAnother: doAnother
};
}
var foo = CoolModule(); //每次使用都需要创建一个新的实例 需要加new
foo.doSomething(); // cool
foo.doAnother(); // 1 ! 2 ! 3
返回的不一定是一个对象,也可以返回一个函数,jquery就是一个很好的例子,返回的这个函数,他自身也可以带有一些属性
模块需要具备的两个必要条件:
- 必须有外部的封闭函数
- 封闭函数必须返回至少一个内部函数
上边这个每次使用都需要创建一个新的实例,当只需要一个实例的时候,可以创建单例模式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var foo = (function CoolModule() {
var something = "cool";
var another = [1, 2, 3];
function doSomething() {
console.log( something );
}
function doAnother() {
console.log( another.join( " ! " ) );
}
return {
doSomething: doSomething,
doAnother: doAnother
};
})(); //自执行
foo.doSomething(); // cool
foo.doAnother(); // 1 ! 2 ! 3
模块也是函数,可以传入参数
返回命名空间方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var foo = (function CoolModule(id) {
function change() {
// 通过内部变量publicAPI来修改公共 API
publicAPI.identify = identify2;
}
function identify1() {
console.log( id );
}
function identify2() {
console.log( id.toUpperCase() );
}
var publicAPI = {
change: change,
identify: identify1
};
return publicAPI;
})( "foo module" );
foo.identify(); // foo module
foo.change();
foo.identify(); // FOO MODULE
这样的好处是:可以从内部对模块实例进行修改,包括添加或删除方法和属性,以及修改它们的值。
5.5.1 现代的模块机制
核心方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var MyModules = (function Manager() {
var modules = {};
function define(name, deps, impl) { //name 是模块名,deps,是依赖项,impl是模块程序
for (var i=0; i<deps.length; i++) {
deps[i] = modules[deps[i]];
}
modules[name] = impl.apply( impl, deps ); //核心:为了模块的定义引入了包装函数(可以传入任何依赖) ,并且将返回值,也就是模块的 API,储存在一个根据名字来管理的模块列表中。
}
function get(name) {
return modules[name];
}
return {
define: define,
get: get
};
})();
核心是 modules[name] = impl.apply(impl, deps) 。为了模块的定义引入了包装函数(可以传入任何依赖) ,并且将返回值,也就是模块的 API,储存在一个根据名字来管理的模块列表中。
使用方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23MyModules.define( "bar", [], function() {
function hello(who) {
return "Let me introduce: " + who;
}
return {
hello: hello
};
} );
MyModules.define( "foo", ["bar"], function(bar) {
var hungry = "hippo";
function awesome() {
console.log( bar.hello( hungry ).toUpperCase() );
}
return {
awesome: awesome
};
} );
var bar = MyModules.get( "bar" );
var foo = MyModules.get( "foo" );
console.log(
bar.hello( "hippo" )
); // Let me introduce: hippo
foo.awesome(); // LET ME INTRODUCE: HIPPO
5.5.2 未来的模块机制
ES6模块API是静态的更加稳定(API 不会在运行时改变)。
ES6的模块没有“行内”格式,必须被定义在独立的文件中(一个文件一个模块)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//bar.js-文件
function hello(who) {
return "Let me introduce: " + who;
}
export hello;
//foo.js-文件
import hello from "bar"; //导入部分模块,仅从 "bar" 模块导入 hello()
var hungry = "hippo";
function awesome() {
console.log(
hello( hungry ).toUpperCase()
);
}
export awesome;
//baz.js-文件
module foo from "foo"; //导入完整的模块
module bar from "bar"; //导入完整的模块
console.log(
bar.hello( "rhino" )
); // Let me introduce: rhino
foo.awesome(); // LET ME INTRODUCE: HIPPO
附录A 动态作用域
主要区别:词法作用域是在写代码或者说定义时确定的,而动态作用域是在运行时确定的。( this 也是!)
词法作用域关注函数在何处声明,而动态作用域关注函数从何处调用。
一定要注意有没有传参数,函数声明没有传参的话,里边变量访问的是全局变量
附录B 块作用于的替代方案
ES6 之前的环境中如何才能实现这个效果?
答案是使用 catch 。
向下兼容都是通过catch来完成的
性能
try/catch 的性能的确很糟糕!!
为什么不直接使用 IIFE 来创建作用域?
因为如果将一段代码中的任意一部分拿出来用函数进行包裹,会改变这段代码的含义,其中的 this 、 return 、 break 和 contine 都会发生变化。
附录C this 词法
ES6 添加了一个特殊的语法形式用于函数声明,叫作箭头函数。1
2
3
4var foo = a => {
console.log( a );
};
foo( 2 ); // 2
常见this丢失问题:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//一般方法
var obj = {
count: 0,
cool: function coolFn() {
var self = this; //重新定义
if (self.count < 1) {
setTimeout( function timer(){ //setTimeout会让内部timer丢失this
self.count++;
console.log( "awesome?" );
}, 100 );
}
}
};
obj.cool(); // 酷吧?
//箭头函数
var obj = {
count: 0,
cool: function coolFn() {
if (this.count < 1) {
setTimeout( () => { // 箭头函数用当前词法作用域覆盖了this的取值
this.count++;
console.log( "awesome?" );
}, 100 );
}
}
};
obj.cool(); // 很酷吧 ?
箭头函数不够理想的原因:匿名而非具名的!!!
推荐方法:1
2
3
4
5
6
7
8
9
10
11
12
13var obj = {
count: 0,
cool: function coolFn() {
if (this.count < 1) {
setTimeout( function timer(){
this.count++; // this 是安全的
// 因为 bind(..)
console.log( "more awesome" );
}.bind( this ), 100 ); // look,用了 bind()!
}
}
};
obj.cool(); // 更酷了。
1. 关于this
this 实际上是在函数被调用时发生的绑定,它指向什么完全取决于函数在哪里被调用。(谁调用指向谁)
显示传递(类似参数的一个上下文对象)可以用this取代,因为显示传递会让代码变得越来越混乱。
1.2 误解
1.2.1 指向自身
没有声明过,值为NAN
声明过没赋值,值为undefined
this绑定到指定的对象上的方法
查看 2.2
1.2.2 它的作用域
this 在任何情况下都不指向函数的词法作用域!!!
因为作用域“对象”无法通过 JavaScript代码访问,它存在于 JavaScript 引擎内部。
1 | function foo(){ |
1.3 this到底是什么
当一个函数被调用时,会创建一个活动记录(有时候也称为执行上下文) 。这个记录会包含函数在哪里被调用(调用栈) 、函数的调用方法、传入的参数等信息。 this 就是记录的其中一个属性,会在函数执行的过程中用到。
2 this全面解析
this完全取决于函数的调用位置(也就是函数的调用方法)
调用位置:函数被调用的位置
调用栈:当前执行位置所调用的所有函数
1 | function baz() { |
把调用栈想象成一个函数调用链
Chrome 可以通过打断点 在Call Stack里查看
2.2 绑定规则
2.2.1 默认绑定
默认绑定到window
严格模式下(strict mode),不能将全局对象用于默认绑定,因为this会绑定到undefined
但是只有在运行在非严格模式下,才能绑定到全局对象,在严格模式下调用则不影响默认绑定。1
2
3
4
5
6
7
8function foo() {
console.log( this.a );
}
var a = 2;
(function(){
"use strict";
foo(); // 2 //在严格模式下 调用 不影响
})();
2.2.2 隐式绑定
隐式绑定会把 this 绑定到这个上下文对象。1
2
3
4
5
6
7
8function foo() {
console.log( this.a );
}
var obj = {
a: 2,
foo: foo
};
obj.foo(); // 2
严格来说这个函数不属于obj对象。
对象属性引用链中,只有上一层或者最后一层在调用位置中起作用
隐式丢失也就是说它会应用默认绑定,从而把 this 绑定到全局对象或者 undefined 上,取决于是否是严格模式。
情况1 -调用的是函数名
1
2
3
4
5
6
7
8
9
10function foo() {
console.log( this.a );
}
var obj = {
a: 2,
foo: foo
};
var bar = obj.foo; // 函数别名!
var a = "oops, global"; // a 是全局对象的属性
bar(); // "oops, global" 调用的是函数本身,他本身丢失了调用位置,所以应用了默认绑定情况2 -参数
参数传递其实就是一种隐式赋值,因此我们传入函数时也会被隐式赋值,所以结果和上一个例子一样。
因为参数引入的都是函数名,不是一个执行函数情况3 -setTimeout
把函数传入到内置的函数,而不是你自己声明的函数,也是一样
2.2.3 显示绑定
call/apply
它们的第一个参数是一个对象,它们会把这个对象绑定到this ,接着在调用函数时指定这个 this 。因为你可以直接指定 this 的绑定对象,因此我们称之为显式绑定。
如果你传入了一个原始值(字符串类型、布尔类型或者数字类型)来当作 this 的绑定对象,这个原始值会被转换成它的对象形式(也就是 new String(..) 、 new Boolean(..) 或者new Number(..) ) 。这通常被称为“装箱” 。
注意:这个只能继承这个对象的属性和方法,但是不能继承这个对象原型上的属性和方法
2.2.3.1 硬绑定
硬绑定一次后就不能再通过硬绑定来修改了!1
2
3
4
5
6
7
8
9
10
11
12
13function foo() {
console.log( this.a );
}
var obj = {
a:2
};
var bar = function() {
foo.call( obj );
};
bar(); // 2
setTimeout( bar, 100 ); // 2
// 硬绑定的 bar 不可能再修改它的 this
bar.call( window ); // 2
应用场景一般就是创建一个包裹函数1
2
3
4var bar = function() {
return foo.apply( obj, arguments );
};
var b = bar( 3 ); // 2 3 这个3是传给arugment
可重复使用的辅助函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function foo(something) {
console.log( this.a, something );
return this.a + something;
}
// 简单的辅助绑定函数
function bind(fn, obj) {
return function() { //这里有个函数,是因为要给下边传入argument用的
return fn.apply( obj, arguments );
};
}
var obj = {
a:2
};
var bar = bind( foo, obj );
var b = bar( 3 ); // 2 3
console.log( b ); // 5
ES5提供了内置的方法Function.prototype.bind()
2.2.3.2 API调用的“上下文”
第三方库的许多函数,以及 JavaScript 语言和宿主环境中许多新的内置函数,都提供了一个可选的参数,通常被称为“上下文” (context) ,其作用和 bind(..) 一样,确保你的回调函数使用指定的 this 。
例如:forEach1
2
3
4
5
6
7
8
9function foo(el) {
console.log( el, this.id );
}
var obj = {
id: "awesome"
};
// 调用 foo(..) 时把 this 绑定到 obj
[1, 2, 3].forEach( foo, obj ); //forEach 就是其中一种
// 1 awesome 2 awesome 3 awesome
2.2.4 new绑定
JavaScript 中 new 的机制实际上和面向类的语言完全不同。
在 JavaScript 中,构造函数只是一些使用 new 操作符时被调用的函数。它们并不会属于某个类,也不会实例化一个类。实际上,它们甚至都不能说是一种特殊的函数类型,它们只是被 new 操作符调用的普通函数而已。
包括内置对象函数(比如 Number(..))在内的所有函数都可以用 new 来调用,这种函数调用被称为构造函数调用。这里有一个重要但是非常细微的区别:实际上并不存在所谓的“构造函数” ,只有对于函数的“构造调用” 。
使用 new 来调用函数,或者说发生构造函数调用时,会自动执行下面的操作:
- 创建(或者说构造)一个全新的对象。 //{}
- 这个新对象会被执行 [[ Prototype ]] 连接。 //第五章会详细介绍
- 这个新对象会绑定到函数调用的 this 。
- 如果函数没有返回其他对象,那么 new 表达式中的函数调用会自动返回这个新对象。
1
2
3
4
5function foo(a) {
this.a = a;
}
var bar = new foo(2);
console.log( bar.a ); // 2
使用 new 来调用 foo(..) 时,我们会构造一个新对象并把它绑定到 foo(..) 调用中的 this上。并没有创建实例!!
2.3 优先级
显示绑定优先级最高!
new绑定比隐式绑定优先级高
new绑定会高于原生bind产生的绑定1
2
3
4
5
6
7
8
9
10function foo(something) {
this.a = something;
}
var obj1 = {};
var bar = foo.bind( obj1 );
bar( 2 );
console.log( obj1.a ); // 2
var baz = new bar(3);
console.log( obj1.a ); // 2 硬绑定
console.log( baz.a ); // 3 new绑定
之所以要在 new 中使用硬绑定函数,主要目的是预先设置函数的一些参数,这样在使用new 进行初始化时就可以只传入其余的参数。 bind(..) 的功能之一就是可以把除了第一个参数(第一个参数用于绑定 this )之外的其他参数都传给下层的函数(这种技术称为“部分应用” ,是“柯里化”的一种) 。举例来说:1
2
3
4
5
6
7
8function foo(p1,p2) {
this.val = p1 + p2;
}
// 之所以使用 null 是因为在本例中我们并不关心硬绑定的 this 是什么
// 反正使用 new 时 this 会被修改
var bar = foo.bind( null, "p1" ); //这一步只是为了传公共/固定参数p1用的
var baz = new bar( "p2" );
baz.val; // p1p2
2.4 绑定例外
2.4.1 被忽略的this
如果你把 null 或者 undefined 作为 this 的绑定对象传入 call 、 apply 或者 bind ,这些值在调用时会被忽略,实际应用的是默认绑定规则:1
2
3
4
5function foo() {
console.log( this.a );
}
var a = 2;
foo.call( null ); // 2 忽略后指向window的a
一种非常常见的做法是使用 apply(..) 来展开一个数组,并当作参数传入一个函数。
类似地, bind(..) 可以对参数进行柯里化(预先设置一些参数) ,这种方法有时非常有用:1
2
3
4
5
6
7
8function foo(a,b) {
console.log( "a:" + a + ", b:" + b );
}
// 把数组“展开”成参数
foo.apply( null, [2, 3] ); // a:2, b:3
// 使用 bind(..) 进行柯里化
var bar = foo.bind( null, 2 ); //预置一个参数
bar( 3 ); // a:2, b:3
在 ES6 中,可以用 … 操作符代替 apply(..) 来“展开”数组, foo(…[1,2]) 和 foo(1,2) 是一样的,这样可以避免不必要的this 绑定。可惜,在 ES6 中没有柯里化的相关语法,因此还是需要使用bind(..) 。
总是传null来忽略this绑定可能产生一些副作用。会存在一些不可预计的后果,所以有更安全的this
更安全的this
创建一个“DMZ”对象,它就是一个空的非委托的对象(委托在第 5 章和第 6 章介绍)
如果我们在忽略 this 绑定时总是传入一个 DMZ 对象,那就什么都不用担心了,因为任何对于 this 的使用都会被限制在这个空对象中,不会对全局对象产生任何影响。
由于这个对象完全是一个空对象,我自己喜欢用变量名 ø(这是数学中表示空集合符号的小写形式)来表示它。
在 JavaScript 中创建一个空对象最简单的方法都是 Object.create(null)(详细介绍请看第 5 章) 。
Object.create(null) 和 {} 很像,但是并不会创建 Object.prototype 这个委托,所以它比 {} “更空”
上边的代码就可以修改为:1
2
3
4
5
6
7
8
9
10function foo(a,b) {
console.log( "a:" + a + ", b:" + b );
}
// 我们的 DMZ 空对象
var ø = Object.create( null );
// 把数组展开成参数
foo.apply( ø, [2, 3] ); // a:2, b:3
// 使用 bind(..) 进行柯里化
var bar = foo.bind( ø, 2 );
bar( 3 ); // a:2, b:3
2.4.2 间接引用
最后会应用到默认绑定。
间接引用最容易在赋值时发生:1
2
3
4
5
6
7
8function foo() {
console.log( this.a );
}
var a = 2;
var o = { a: 3, foo: foo };
var p = { a: 4 };
o.foo(); // 3
(p.foo = o.foo)(); // 2
赋值表达式 p.foo = o.foo 的返回值是目标函数的引用,因此调用位置是 foo() 而不是p.foo() 或者 o.foo() 。根据我们之前说过的,这里会应用默认绑定。
之前this丢失的时候说过:
对于默认绑定来说,决定 this 绑定对象的并不是调用位置是否处于严格模式,而是函数体是否处于严格模式。如果函数体处于严格模式, this 会被绑定到 undefined ,否则this 会被绑定到全局对象。
2.4.3 软绑定
硬绑定会大大降低函数的灵活性,使用硬绑定后就无法使用隐式和显式绑定来修改this了
软绑定:实现和硬绑定相同的效果,同时保留隐式绑定或者显式绑定修改 this 的能力。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if (!Function.prototype.softBind) {
Function.prototype.softBind = function(obj) {
var fn = this;
// 捕获所有 curried 参数
var curried = [].slice.call( arguments, 1 );
var bound = function() {
return fn.apply(
(!this || this === (window || global)) ?
obj : this
curried.concat.apply( curried, arguments )
);
};
bound.prototype = Object.create( fn.prototype );
return bound;
};
}
验证:1
2
3
4
5
6
7
8
9
10
11
12
13function foo() {
console.log("name: " + this.name);
}
var obj = { name: "obj" },
obj2 = { name: "obj2" },
obj3 = { name: "obj3" };
var fooOBJ = foo.softBind( obj );
fooOBJ(); // name: obj
obj2.foo = foo.softBind(obj);
obj2.foo(); // name: obj2 <---- 看!!!
fooOBJ.call( obj3 ); // name: obj3 <---- 看!
setTimeout( obj2.foo, 10 );
// name: obj <---- 应用了软绑定
可以看到,软绑定版本的 foo() 可以手动将 this 绑定到 obj2 或者 obj3 上,但如果应用默认绑定,则会将 this 绑定到 obj 。
2.5 this 词法
箭头函数并不是使用function关键字定义的,而是使用被称为“胖箭头”的操作符 =>定义的。箭头函数不使用 this 的四种标准规则,而是根据外层(函数或者全局)作用域来决定 this 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function foo() {
// 返回一个箭头函数
return (a) => {
//this 继承自 foo()
console.log( this.a );
};
}
var obj1 = {
a:2
};
var obj2 = {
a:3
};
var bar = foo.call( obj1 );
bar.call( obj2 ); // 2, 不是 3 !
foo() 内部创建的箭头函数会捕获调用时 foo() 的 this 。由于 foo() 的 this 绑定到 obj1 ,bar (引用箭头函数)的 this 也会绑定到 obj1 ,箭头函数的绑定无法被修改。 ( new 也不行!)
箭头函数最常用于回调函数中,例如事件处理器或者定时器:1
2
3
4
5
6
7
8
9
10function foo() {
setTimeout(() => {
// 这里的 this 在此法上继承自 foo()
console.log( this.a );
},100);
}
var obj = {
a:2
};
foo.call( obj ); // 2
在以前用的其实和胖头函数原理是一样的1
var self = this
编程风格
- 丢弃this,用 self来代替
- 完全用this和箭头函数和
bind协作
3 对象
3.1 语法
可以通过两种形式定义: 声明(文字)形式和构造形式
声明/文字语法: 大多数的选择1
2
3
4var myObj = {
key: value
// ...
};
构造语法:1
2var myObj = new Object();
myObj.key = value;
3.2 类型
主要类型:string、number、boolean、null、undefined、object
简单基本类型( string 、 boolean 、 number 、 null 和 undefined )本身并不是对象。
null 有时会被当作一种对象类型,但是这其实只是语言本身的一个 bug,即对 null 执行typeof null 时会返回字符串 “object” 。 1 实际上, null 本身是基本类型。
原理是这样的,不同的对象在底层都表示为二进制,在 JavaScript 中二进制前三位都为 0 的话会被判断为 object 类型, null 的二进制表示是全 0, 自然前三位也是 0, 所以执行 typeof 时会返回“ object ” 。
JavaScript 中有许多特殊的对象子类型,我们可以称之为复杂基本类型。
函数就是对象的一个子类型(从技术角度来说就是可调用的对象 ) 。JavaScript 中的函数是“一等公民” ,因为它们本质上和普通的对象一样(只是可以调用) ,所以可以像操作其他对象一样操作函数(比如当作另一个函数的参数) 。
内置对象:JavaScript 中还有一些对象子类型,通常被称为内置对象。有些内置对象的名字看起来和简单基础类型一样,不过实际上它们的关系更复杂,我们稍后会详细介绍。String、Number、Boolean、Object、Function、Array、Date、RegExp、Error
他们很想其他语言中的类
但在js中他们只是一个内置函数,可以当作构造函数来使用(new),从而构造一个新对象1
2
3
4
5
6
7
8
9
10var strPrimitive = "I am a string"; //基本类型
typeof strPrimitive; // "string"
strPrimitive instanceof String; // false
var strObject = new String( "I am a string" ); //内置对象
typeof strObject; // "object"
strObject instanceof String; // true
// 检查 sub-type 对象
Object.prototype.toString.call( strObject ); // [object String]
原始值 “I am a string” 并不是一个对象,它只是一个字面量,并且是一个不可变的值。如果要在这个字面量上执行一些操作,比如获取长度、访问其中某个字符等,那需要将其转换为 String 对象。
不过语言会自动把字符串字面量转换成一个 String 对象,其实数字和布尔字面量也是一样的!null 和 undefined 没有对应的构造形式,它们只有文字形式。相反, Date 只有构造,没有文字形式。
对于 Object 、 Array 、 Function 和 RegExp (正则表达式)来说,无论使用文字形式还是构造形式,它们都是对象,不是字面量。
Error 对象很少在代码中显式创建,一般是在抛出异常时被自动创建。也可以使用 newError(..) 这种构造形式来创建,不过一般来说用不着。
3.3 内容
存储在对象容器内部的是这些属性的名称,它们就像指针(从技术角度来说就是引用)一样,指向这些值真正的存储位置。
属性访问: .
键访问: []
主要区别在于 . 操作符要求属性名满足标识符的命名规范,而 [“..”] 语法可以接受任意 UTF-8/Unicode 字符串作为属性名。
属性名永远都是字符串,如果使用string以外的值作为属性名,都会被转换为一个字符串
3.3.1 可计算属性名
如:myObject[prefix+name]
但是文字形式来声明对象时这样做就不行了
ES6增加了可计算属性名,就可以用[]包裹一个表达式来当作属性名了
3.3.2 属性和方法
如果访问的对象属性是一个函数,就叫做方法。
但是这么叫并不准确,因为函数只是一个引用,并不是属于的关系
ES6 增加了 super 引用,一般来说会被用在 class 中(参见附录 A) 。 super的行为似乎更有理由把 super 绑定的函数称为“方法” 。
3.3.3 数组
通过添加命名属性,数组的length并不会改变
但是如果属性名看起来像一个数字,那就会变成一个数组下标1
2
3
4
5
6
7
8
9
10var myArray = [ "foo", 42, "bar" ];
myArray.baz = "baz";
myArray.length; // 3 并不会改变
myArray.baz; // "baz"
//属性名为数字的情况
var myArray = [ "foo", 42, "bar" ];
myArray["3"] = "baz";
myArray.length; // 4 这里变化了,因为属性名是一个像数字的值
myArray[3]; // "baz"
可以当键值对来使用,但是并不好,因为有对象的存在,更清晰易懂
3.3.4 复制对象
ES6 定义了 Object.assign(..) 方法来实现浅复制。
Object.assign(..) 方法的第一个参数是目标对象,之后还可以跟一个或多个源对象。
它会遍历一个或多个源对象的所有可枚举(enumerable,参见下面的代码)的自有键(owned key,很快会介绍)并把它们复制(使用 = 操作符赋值)到目标对象,最后返回目标对象,就像这样
下一节会介绍“属性描述符”以及 Object.defineProperty(..) 的用法。但是需要注意的一点是,由于 Object.assign(..) 就是使用 = 操作符来赋值,所以源对象属性的一些特性(比如 writable )不会被复制到目标对象。
ES3实现深复制和浅复制可以搜索高级程序设计笔记查看
3.3.5 属性描述符
ES5开始所有属性都具备了属性描述符
属性描述符包含三个特性:writable(可写)、enumerable(可枚举)、configurable(可配置)
查看可以通过:Object.getOwnPropertyDescriptor(obj,属性名)
设置可以通过:Object.defineProperty(obj,属性名,{})来添加和修改属性1
2
3
4
5
6
7
8var myObject = {};
Object.defineProperty( myObject, "a", {
value: 2,
writable: true,
configurable: true,
enumerable: true
} );
myObject.a; // 2
3.3.5.1 Writable -不可修改
writable:false //不可写
但是在严格模式“use strict”下,是不允许修改的,会报TyperError错误
3.3.5.2 Configurable -不可修改他的属性描述符
不管是不是处于严格模式,尝
试修改一个不可配置的属性描述符都会出错。注意:把 configurable 修改成false 是单向操作,无法撤销!
试图在将configurable再设置成true的时候,会报TypeError错误
要注意有一个小小的例外:即便属性是 configurable:false , 我们还是可以把 writable 的状态由 true 改为 false ,但是无法由 false 改为 true 。
除了无法修改, configurable:false 还会禁止删除这个属性:
delete myObject.a //不可以删除,静默失败,不会报错
3.3.5.3 Enumerable -不可枚举
描述符控制的是属性是否会出现在对象的属性枚举中
例如:for...in
虽然不可以枚举,但是仍然可以访问到他
3.3.6 不变性
ES5通过很多种方法实现不变性,但是所有的方法创建的都是浅不变形,也就是说,它们只会影响目标对象和它的直接属性。
如果目标对象引用了其他对象(数组、对象、函数,等) ,其他对象的内容不受影响,仍然是可变的:
js程序很少需要深不可变性,如果发现需要密封或冻结等操作,我想你应该重新思考一下程序的设计!
3.3.6.1 对象常量
结合 writable:false 和 configurable:false 就可以创建一个真正的常量属性(不可修改、重定义或者删除)
3.3.6.2 禁止扩展 -可以修改属性的值和配置(属性描述符)和删除
Object.preventExtensions(obj)禁止一个对象添加新属性并且保留已有属性
非严格模式下,试图创建属性会静默失败,而严格模式下,将抛出TypeError错误
3.3.6.3 密封 -可以修改属性的值
Object.seal(obj)方法实际上就是调用Object.preventExtensions(obj)+把所有属性标记为configurable:false
所以不仅不能添加属性,也不能重新配置或者删除任何现有属性(虽然可以修改属性的值)
3.3.6.4 冻结 -都不可以
Object.freeze(obj)方法实际上就是调用Object.seal(obj),并把所有属性标为writable:false(不可修改)
级别最高但是它引用的对象不受影响。
深度冻结:将遍历它引用的所有对象,对这些对象调用Object.freeze(..)。
但是一定要小心,因为这样有可能会无意中冻结其他共享对象
3.3.7 [[Get]]
在语言规范中, myObject.a 在 myObject 上实际上是实现了 [[Get]] 操作(有点像函数调用: [[Get]]() ) 。
对象默认内置的[[Get]]会逐级在[[Prototype]]上查找属性名,如果没有找到就会返回undefined
3.3.8 [[Put]]
对象的属性赋值会触发 [[Put]]来设置或者创建这个属性.[[Put]] 被触发时,实际的行为取决于许多因素,包括对象中是否已经存在这个属性(这是最重要的因素) 。
如果存在,则执行下列操作:
- 属性是否是访问描述符(参见 3.3.9 节)?如果是并且存在 setter 就调用
setter。 - 属性的数据描述符中
writable是否是 false ?如果是,在非严格模式下静默失败,在严格模式下抛出 TypeError 异常。 - 如果都不是,将该值设置为属性的值。
3.3.9 Getter和Setter -访问描述符
ES5 中可以使用 getter 和 setter 部分改写默认操作。getter 是一个隐藏函数,会在获取属性值时调用。setter 也是一个隐藏函数,会在设置属性值时调用。
当你给一个属性定义 getter、setter 或者两者都有时,这个属性会被定义为“访问描述符” (和“数据描述符”相对) 。
对于访问描述符来说,JavaScript 会忽略它们的 value 和writable 特性,取而代之的是关心 set 和 get (还有 configurable 和 enumerable )特性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var myObject = {
// 给 a 定义一个 getter
get a() { //好像是es6的新语法 文字语法定义getter
return 2;
}
};
Object.defineProperty( //显示定义
myObject, // 目标对象
"b", // 属性名
{ // 描述符
// 给 b 设置一个 getter
get: function(){ return this.a * 2 },
// 确保 b 会出现在对象的属性列表中
enumerable: true
}
);
myObject.a; // 2
myObject.b; // 4
如果设置了getter值,哪怕再设置setter,返回的仍然是getter的值1
2
3
4
5
6
7
8var myObject = {
// 给 a 定义一个 getter
get a() {
return 2;
}
};
myObject.a = 3;
myObject.a; // 2
setter 会覆盖单个属性默认的[[Put]] (也被称为赋值)操作。
通常来说 getter 和 setter 是成对出现的(只定义一个的话通常会产生意料之外的行为)1
2
3
4
5
6
7
8
9
10
11
12var myObject = {
// 给 a 定义一个 getter
get a() {
return this._a_;
},
// 给 a 定义一个 setter
set a(val) {
this._a_ = val * 2;
}
};
myObject.a = 2;
myObject.a; // 4
3.3.10 存在性
如果区分 myObject.a 的属性返回值的 undefined,是设置的还是因为不存在所返回的!
通过不访问属性值来判断,是否存在这个属性1
2
3
4
5
6
7var myObject = {
a:2
};
("a" in myObject); // true
("b" in myObject); // false
myObject.hasOwnProperty( "a" ); // true
myObject.hasOwnProperty( "b" ); // false
in:判断属性名而不是属性值是否存在的时候包含了[[Prototype]]原型链中obj.hasOwnProperty("属性名"):不检查[[Prototype]]obj.propertyIsEnumerable("属性名"):不检查[[Prototype]]的同时,还要满足enumerable:true
没有链接到Object.prototype上的对象也存在,例如Object.create(null)就不存在,查询hasOwnProperty的时候就会失败!
下边是强硬的方法判断:Object.prototype.hasOwnProperty.call(obj,"a") 这样就不会失败了!!
3.3.10.1 枚举
for...in:用来枚举-通常只用来枚举对象,不要枚举数组,因为除了会枚举角标,还会同时枚举属性Object.keys():返回所有可枚举属性的键值的数组 –不检查[[Prototype]]Object.getOwnPropertyNames(..):返回所有属性的键值的数组-不管是否可枚举 –不检查[[Prototype]]
不可枚举,但是有可能存在
3.4 遍历
对于数组来说,遍历的是数组下标:
ES3:for
ES5:forEach、every、some -区别在于毁掉函数返回值处理方式不同
forEach(..) 会遍历数组中的所有值并忽略回调函数的返回值。
every(..) 会一直运行直到回调函数返回 false (或者“假”值)
some(..) 会一直运行直到回调函数返回 true (或者“真”值) 。
every和some类似for循环中的break语句,提前终止语句!!!
遍历数组下标时采用的是数字顺序(for 循环或者其他迭代器),
但是遍历对象属性时的顺序是不确定的,在不同的 JavaScript 引擎中可能不一样。
直接遍历数组的值而不是数组下标的方法:
ES6 增加了一种用来遍历数组的 for..of 循环语法1
2
3
4
5
6
7var myArray = [ 1, 2, 3 ];
for (var v of myArray) {
console.log( v );
}
// 1
// 2
// 3
for..of 循环首先会向被访问对象请求一个迭代器对象,然后通过调用迭代器对象的next() 方法来遍历所有返回值。
数组有内置的 @@iterator(迭代器) ,因此 for..of 可以直接应用在数组上。
我们使用内置的 @@iterator 来手动遍历数组,看看它是怎么工作的:1
2
3
4
5
6var myArray = [ 1, 2, 3 ];
var it = myArray[Symbol.iterator]();
it.next(); // { value:1, done:false }
it.next(); // { value:2, done:false }
it.next(); // { value:3, done:false }
it.next(); // { done:true } //这最后一次调用是为了确认已完成遍历
使用 ES6 中的符号 Symbol.iterator 来获取对象的 @@iterator 内部属性 。Symbol.iterator 只是一个符号名,而不是Symbol的iterator属性的值!@@iterator 本身并不是一个迭代器对象,而是一个返回迭代器对象的函数value 是当前的遍历值, done 是一个布尔值,表示是否还有可以遍历的值。
普通的对象没有内置的 @@iterator ,所以无法自动完成 for..of 遍历,不过可以手动进行遍历,同数组!有兴趣参考P1231
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33var myObject = {
a: 2,
b: 3
};
Object.defineProperty( myObject, Symbol.iterator, {
enumerable: false,
writable: false,
configurable: true,
value: function() {
var o = this;
var idx = 0;
var ks = Object.keys( o );
return {
next: function() {
return {
value: o[ks[idx++]],
done: (idx > ks.length)
};
}
};
}
} );
// 手动遍历 myObject
var it = myObject[Symbol.iterator]();
it.next(); // { value:2, done:false }
it.next(); // { value:3, done:false }
it.next(); // { value:undefined, done:true }
// 用 for..of 遍历 myObject
for (var v of myObject) {
console.log( v );
}
// 2
// 3
对于用户定义的对象来说,结合 for..of 循环和自定义迭代器可以组成非常强大的对象操作工具。
比如说,一个 Pixel 对象(有 x 和 y 坐标值)列表可以按照距离原点的直线距离来决定遍历顺序,也可以过滤掉“太远”的点,等等。只要迭代器的 next() 调用会返回 { value:.. } 和 { done: true } ,ES6 中的 for..of 就可以遍历它。
4. 混合对象“类”
4.1 类理论
面向对象编程强调的是数据和操作数据的行为本质上是互相关联的
因此好的设计就是把数据以及和它相关的行为打包(或者说封装)起来,被称为数据结构。
所有字符串都是 String 类的一个实例,也就是说它是一个包裹,包含字符数据和我们可以应用在数据上的函数。
例如: “汽车”可以被看作“交通工具”的一种特例,后者是更广泛的类。
类:交通工具公有的—引擎
继承:汽车继承了这个公有的引擎,还进行了扩展
实例化:每一辆汽车又分别有着不同的车辆识别码
类的另一个核心概念是多态,这个概念是说父类的通用行为可以被子类用更特殊的行为重写。
编程风格分很多种,类只是其中一种,还有像PHP的过程化。
js中有一些近似类的元素,比如new和instanceof,ES6还新增了class
但是js实际上是没有类的,只是js通过近似类的语法实现了近似类的功能
4.2 类的机制
4.2.1 建造
类可以理解为一张蓝图
实例化可以理解为通过蓝图来创建不同的房子
实例化只是类的一个副本。
按理说实力对象是不能操作类的,但是可以判断是来自哪个类
4.2.2 构造函数
类构造函数属于类,而且通常和类同名,它的任务就是初始化实例所需要的所有信息。
构造函数要通过new来构造一个新的类的实例。
4.3 类的继承
先定义一个类,然后定义一个继承前者的类。
后者通常被称为子类 ,前者通常被称为父类。
父类和子类并不是实例。
下边是ES6的class来实现的关于类继承的伪代码
如果用ES3实现,请看4.4.1 显示引入1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Vehicle { //类:大家都有的引擎属性
engines = 1
ignition() {
output( "Turning on my engine." );
}
drive() {
ignition();
output( "Steering and moving forward!" )
}
}
class Car inherits Vehicle { //子类:car继承类的引擎,并做了相应的修改和扩展
wheels = 4
drive() {
inherited:drive() //注:继承原始drive()--相对多态
output( "Rolling on all ", wheels, " wheels!" )
}
}
class SpeedBoat inherits Vehicle { //子类:快艇继承了类的引擎,并做了相应的修改和扩展
engines = 2
ignition() {
output( "Turning on my ", engines, " engines." )
}
pilot() {
inherited:drive() //注:继承原始drive()--相对多态
output( "Speeding through the water with ease!" )
}
}
4.3.1 多态
上例中的两个注被称为多态或者虚拟多态。在本例中,更恰当的说法是相对多态。
超类=父类:在许多语言中可以使用 super 来代替本例中的inherited: ,它的含义是 超类(superclass),表示当前类的父类 / 祖先类。
在传统的面向类的语言中 super 还有一个功能,就是从子类的构造函数中通过super 可以直接调用父类的构造函数。通常来说这没什么问题,因为对于真正的类来说,构造函数是属于类的。然而,在 JavaScript 中恰好相反——实际上“类”是属于构造函数的(类似 Foo.prototype… 这样的类型引用) 。由于JavaScript 中父类和子类的关系只存在于两者构造函数对应的 .prototype 对象中,因此它们的构造函数之间并不存在直接联系,从而无法简单地实现两者的相对引用(在 ES6 的类中可以通过 super 来“解决”这个问题,参见附录 A) 。
在子类(而不是它们创建的实例对象!)中也可以相对引用它继承的父类,这种相对引用通常被称为 super 。
子类得到的仅仅是继承自父类行为的一份副本。子类对继承到的一个方法进行“重写” ,不会影响父类中的方法,这两个方法互不影响,因此才能使用相对多态引用访问父类中的方法(如果重写会影响父类的方法,那重写之后父类中的原始方法就不存在了,自然也无法引用) 。
类的继承其实就是复制
4.3.2 多重继承
继承多个父类,叫多重继承。
这种机制会带来很多复杂的问题,不推荐使用!!
4.4 混入
js的new方法其实是将类绑定在实例的prototype上
但是真正的类的实例化,是复制。
JavaScript 开发者也想出了一个方法来模拟类的复制行为,这个方法就是混入。
两种类型的混入:显式和隐式。
不管是怎么混入,原理都是深浅复制和绑定,我都不推荐用,太不好维护,不直观
4.4.1 显示混入
许多框架的extend方法,其实就是浅复制1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 非常简单的 mixin(..) 例子 :
function mixin( sourceObj, targetObj ) {
for (var key in sourceObj) {
// 只会在不存在的情况下复制 这里其实也是个重点!!关系到显式伪多态call的原因
if (!(key in targetObj)) {
targetObj[key] = sourceObj[key]; //浅复制
}
}
return targetObj;
}
var Vehicle = {
engines: 1,
ignition: function() {
console.log( "Turning on my engine." );
},
drive: function() {
this.ignition();
console.log( "Steering and moving forward!" );
}
};
var Car = mixin( Vehicle, {
wheels: 4,
drive: function() {
Vehicle.drive.call( this ); //显式多态
console.log(
"Rolling on all " + this.wheels + " wheels!"
);
}
} );
此时我们处理的已经不再是类了,因为js中部存在类,Vehicle和Car都是对象,供我们复制和粘贴。
本质上说:函数实际上没有被复制,复制的只是函数的引用。
4.4.1.1 再说多态
Vehicle.drive.call( this )是显式伪多态,而在ES6实现相同功能的时候inherited:drive()叫相对多态
在 JavaScript 中由于屏蔽使用显式伪多态会在所有需要使用(伪)多态引用的地方创建一个函数关联,这会极大地增加维护成本。
此外,由于显式伪多态可以模拟多重继承,所以它会进一步增加代码的复杂度和维护难度。
所以避免使用伪多态!!!
4.4.1.2 混合复制
重点在之前的浅复制时在没有这个属性的时候进行复制,但是这个确是不管是否存在,都进行复制,所以存在的也会进行复制替换!!!
所以叫混合复制!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 另一种混入函数,可能有重写风险
function mixin( sourceObj, targetObj ) {
for (var key in sourceObj) { //重点在这里,他没有进行判断
targetObj[key] = sourceObj[key];
}
return targetObj;
}
var Vehicle = {
// ...
};
// 首先创建一个空对象并把 Vehicle 的内容复制进去
var Car = mixin( Vehicle, { } );
// 然后把新内容复制到 Car 中
mixin( {
wheels: 4,
drive: function() {
// ...
}
}, Car );
因为函数对象是引用关系,所以当混入复制的时候,会关联到很多变动。
一些库提出了晚绑定这种技术,但是会降低性能,得不偿失!
我觉得不推荐使用!!
4.4.1.3 寄生继承
显式混入模式的一种变体被称为“寄生继承” ,它既是显式的又是隐式的。
工作原理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// “传统的 JavaScript 类”Vehicle
function Vehicle() {
this.engines = 1;
}
Vehicle.prototype.ignition = function() {
console.log( "Turning on my engine." );
};
Vehicle.prototype.drive = function() {
this.ignition();
console.log( "Steering and moving forward!" );
};
// “寄生类” Car
function Car() {
// 首先,car 是一个 Vehicle
var car = new Vehicle(); //创建了一个子类
// 接着我们对 car 进行定制
car.wheels = 4;
// 保存到 Vehicle::drive() 的特殊引用
var vehDrive = car.drive;
// 重写 Vehicle::drive()
car.drive = function () { //进行重写
vehDrive.call(this); //回归绑定
console.log(
"Rolling on all " + this.wheels + " wheels!"
);
return car; //返回了自己的对象,没有使用Car(),所以调用Car()的时候可以不用加new
}
}
var myCar = new Car();
myCar.drive();
// 发动引擎。
// 手握方向盘!
// 全速前进!
调用 new Car() 时会创建一个新对象并绑定到 Car 的 this 上(参见第 2章) 。但是因为我们没有使用这个对象而是返回了我们自己的 car 对象,所以最初被创建的这个对象会被丢弃,因此可以不使用 new 关键字调用 Car()。这样做得到的结果是一样的,但是可以避免创建并丢弃多余的对象。
4.4.2 隐式混入
隐式混入和之前提到的显式伪多态很像,因此也具备同样的问题。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var Something = {
cool: function() {
this.greeting = "Hello World";
this.count = this.count ? this.count + 1 : 1;
}
};
Something.cool();
Something.greeting; // "Hello World"
Something.count; // 1
var Another = {
cool: function() {
// 隐式把 Something 混入 Another
Something.cool.call( this ); //重点在这里绑定到Something.cool上了
}
};
Another.cool();
Another.greeting; // "Hello World"
Another.count; // 1 (count 不是共享状态)
缺点: Something.cool.call( this ) 仍然无法变成相对(而且更灵活的)引用,所以使用时千万要小心。
通常来说,尽量避免使用这样的结构,以保证代码的整洁和可维护性。
5 原型
5.1 [[Prototype]]
JavaScript 中的对象有一个特殊的 [[Prototype]] 内置属性,其实就是对于其他对象的引用。
对象的 [[Prototype]] 链接可以为空,虽然很少见,例如Object.create(null)Object.create(..)会创建一个对象并把这个对象的 [[Prototype]] 关联到指定的对象。
查找完整条[[Prototype]]链,没有的话[[Get]]操作返回值是undefined
5.1.1 Object.prototype
所有普通的 [[Prototype]] 链最终都会指向内置的 Object.prototype 。
所有的“普通”对象都“源于”Object.prototype 对象,所以它包含 JavaScript 中许多通用的功能。
比如: .toString() 和 .valueOf() 和 .hasOwnProperty(..) 和 .isPrototypeOf(..)
5.1.2 属性设置和屏蔽
myObject.foo = "bar";
如果 foo 不直接存在于 myObject 中而是存在于原型链上层时 myObject.foo = “bar” 会出现的三种情况。
- 如果在
[[Prototype]]链上层存在名为 foo 的普通数据访问属性(参见第 3 章)并且没
有被标记为只读( writable:false ) ,那就会直接在 myObject 中添加一个名为 foo 的新
属性,它是屏蔽属性。 - 如果在
[[Prototype]]链上层存在 foo ,但是它被标记为只读( writable:false ) ,那么
无法修改已有属性或者在 myObject 上创建屏蔽属性。如果运行在严格模式下,代码会
抛出一个错误。否则,这条赋值语句会被忽略。总之,不会发生屏蔽。 - 如果在
[[Prototype]]链上层存在 foo 并且它是一个 setter(参见第 3 章) ,那就一定会
调用这个 setter。 foo 不会被添加到(或者说屏蔽于) myObject ,也不会重新定义 foo 这
个 setter。
总计:只有在原型链上没有标记writable:false的时候,才会对myObject添加屏蔽属性,剩下的都不能添加和修改
如果你希望在第二种和第三种情况下也屏蔽 foo ,那就不能使用 = 操作符来赋值,而是使用 Object.defineProperty(..) (参见第 3 章)来向 myObject 添加 foo 。
第二种情况可能是最令人意外的, 只读 属性会阻止 [[Prototype]] 链下层隐式创建(屏蔽)同名属性。这样做主要是为了模拟类属性的继承。你可以把原型链上层的 foo 看作是父类中的属性,它会被 myObject 继承(复制) ,这样一来 myObject 中的 foo 属性也是只读,所以无法创建。但是一定要注意, 实际上并不会发生类似的继承复制(参见第 4 章和第 5 章) 。这看起来有点奇怪, myObject 对象竟然会因为其他对象中有一个只读 foo 就不能包含 foo 属性。更奇怪的是,这个限制只存在于 = 赋值中,使用 Object.defineProperty(..) 并不会受到影响。
使用屏蔽一般多伴随多态,所以并不推荐!
隐式屏蔽:1
2
3
4
5
6
7
8
9
10
11
12var anotherObject = {
a:2
};
var myObject = Object.create( anotherObject );
anotherObject.a; // 2
myObject.a; // 2
anotherObject.hasOwnProperty( "a" ); // true
myObject.hasOwnProperty( "a" ); // false
myObject.a++; // 隐式屏蔽!
anotherObject.a; // 2
myObject.a; // 3
myObject.hasOwnProperty( "a" ); // true
隐式屏蔽, ++ 操作首先会通过 [[Prototype]]查找属性 a 并从 anotherObject.a 获取当前属性值 2,然后给这个值加 1,接着用 [[Put]]将值 3 赋给 myObject 中新建的屏蔽属性 a
5.2 类
JavaScript 和面向类的语言不同,它并没有类来作为对象的抽象模式 或者说蓝图。
实际上,JavaScript 才是真正应该被称为面向对象的语言,因为它是少有的可以不通过类,直接创建对象的语言。
在 JavaScript 中,类无法描述对象的行 , (因为根本就不存在类!)对象直接定义自己的行为。再说一遍,JavaScript 中只有对象。
5.2.1 类函数
JavaScript 中有一种奇怪的行为一直在被无耻地滥用,那就是模仿类。
这种奇怪的“类似类”的行为利用了函数的一种特殊特性:所有的函数默认都会拥有一个名为 prototype 的公有并且不可枚举(参见第 3 章)的属性,它会指向另一个对象:1
2
3
4function Foo() {
// ...
}
Foo.prototype; // { }
Foo.prototype其实就是new Foo(),(其实Object.create()也是一样的)下边验证一下1
2
3
4
5function Foo() {
// ...
}
var a = new Foo();
Object.getPrototypeOf( a ) === Foo.prototype; // true
Object.getPrototypeOf("a")方法是获取某个对象的原型的方法!Object.setPrototypeOf(obj,proto)方法是设置对象的原型的方法!
所以实例化,只是创建多个对象,他们 [[Prototype]] 关联的是同一个对象。
继承意味着复制操作,JavaScript(默认)并不会复制对象属性。
相反,JavaScript 会在两个对象之间创建一个关联,这样一个对象就可以通过委托访问另一个对象的属性和函数。
5.2.2 构造函数
1 | function Foo() { |
Foo.prototype 默认有一个公有并且不可枚举(参见第 3 章)的属性 .constructor
new Foo()构造函数 创建的对象也有一个 .constructor 属性
实际上 a 本身并没有
.constructor属性。而且,虽然 a.constructor 确实指向 Foo 函数,但是这个属性并不是表示 a 由 Foo “构造”
对于JavaScript 引擎来说首字母大写没有任何意义。
5.2.2.1 构造函数还是调用
普通的函数调用前面加上 new 关键字之后,就会把这个函数调用变成一个“构造函数调用” 。
当且仅当使用 new 时,函数调用会变成“构造函数调用” 。
实际上, new 会劫持所有普通函数并用构造对象的形式来调用它。1
2
3
4
5
6function NothingSpecial() {
console.log( "Don't mind me!" );
}
var a = new NothingSpecial(); 构造一个空对象,赋值给a
// "Don't mind me!"
a; // {}
5.2.3 技术
回顾构造函数
5.2.2的代码中 a.constructor === Foo 中.constructor 引用同样被委托给了 Foo.prototype ,而Foo.prototype.constructor 默认指向 Foo 。a.constructor 只是通过默认的 [[Prototype]] 委托指向 Foo ,这和“构造”毫无关系。
如果修改了Foo.prototype的指向,那new Foo就会丢失.constructor1
2
3
4
5function Foo() { /* .. */ }
Foo.prototype = { /* .. */ }; // 创建一个新原型对象
var a1 = new Foo();
a1.constructor === Foo; // false! 因为Foo.prototype的重新赋值,导致丢失constructor,所以会向委托链顶端的Object.prototype查找,所以指向了Object(..)
a1.constructor === Object; // true!
详细解释: a1 并没有 .constructor 属性,所以它会委托 [[Prototype]] 链上的 Foo.prototype 。但是这个对象也没有 .constructor 属性(不过默认的 Foo.prototype 对象有这个属性!) ,所以它会继续委托,这次会委托给委托链顶端的 Object.prototype 。这个对象有 .constructor 属性,指向内置的 Object(..) 函数。
但是可以手动添加一个.constructor 属性1
2
3
4
5
6
7
8
9
10
11function Foo() { /* .. */ }
Foo.prototype = { /* .. */ }; // 创建一个新原型对象
// 需要在 Foo.prototype 上“修复”丢失的 .constructor 属性
// 新对象属性起到 Foo.prototype 的作用
// 关于 defineProperty(..),参见第 3 章
Object.defineProperty( Foo.prototype, "constructor" , { //手动添加
enumerable: false,
writable: true,
configurable: true,
value: Foo // 让 .constructor 指向 Foo
} );
a1.constructor 是一个非常不可靠并且不安全的引用。通常来说要尽量避免使用这些引用。
5.3 (原型)继承 call+Object.create()
典型原型风格:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20function Foo(name) {
this.name = name;
}
Foo.prototype.myName = function() {
return this.name;
};
function Bar(name,label) {
Foo.call( this, name ); //Foo.prototype不会一起绑定到this,只绑定了Foo
this.label = label;
}
// 我们创建了一个新的 Bar.prototype 对象并关联到 Foo.prototype
Bar.prototype = Object.create( Foo.prototype ); //重点在这里
// 注意!现在没有 Bar.prototype.constructor 了
// 如果你需要这个属性的话可能需要手动修复一下它
Bar.prototype.myLabel = function() {
return this.label;
};
var a = new Bar( "a", "obj a" );
a.myName(); // "a"
a.myLabel(); // "obj a"
这段代码的核心部分就是语句 Bar.prototype = Object.create( Foo.prototype ) 。
展开就是:Bar.prototype.prototype = Foo.prototype
Object.create(..) 会凭空创建一个“新”对象并把新对象内部的 [[Prototype]] 关联到你指定的对象(本例中是 Foo.prototype ) 。
下边两种赋值是不可取的:1
2
3
4// 和你想要的机制不一样!
Bar.prototype = Foo.prototype;
// 基本上满足你的需求,但是可能会产生一些副作用 :(
Bar.prototype = new Foo();
- Bar.prototype = Foo.prototype 并不会创建一个关联到 Bar.prototype 的新对象,它只是让 Bar.prototype 直接引用 Foo.prototype 对象。因此当你执行类似 Bar.prototype.myLabel = … 的赋值语句时会直接修改 Foo.prototype 对象本身。
- Bar.prototype = new Foo() 的确会创建一个关联到 Bar.prototype 的新对象。但是它使用了 Foo(..) 的“构造函数调用” ,如果函数 Foo 有一些副作用(比如写日志、修改状态、注册到其他对象、给 this 添加数据属性,等等)的话,就会影响到 Bar() 的“后代” ,后果不堪设想。
Object.create()也是有缺点的,缺点在于:需要创建一个新对象然后把旧对象抛弃掉,不能直接修改已有的默认对象。
但是ES6添加了辅助函数 Object.setPrototypeOf(..) ,可以用标准并且可靠的方法来修改关联。
比较一下这两种写法:1
2
3
4// ES6 之前需要抛弃默认的 Bar.prototype --轻微性能损失,但是可读性更高,更简短
Bar.ptototype = Object.create( Foo.prototype );
// ES6 开始可以直接修改现有的 Bar.prototype
Object.setPrototypeOf( Bar.prototype, Foo.prototype );
5.3.x 补充 Object.create和New的区别
你不知道的javascript之Object.create 和new区别
1. new
1.只针对函数对象
2.复制函数本身的属性及原型链上的属性,但是不能复制函数的静态方法6
2
3
4
5
6
7
this.prop = 2; // 这个不是函数的静态属性,所以会被复制
}
Fun.method = 2; // 静态属性不能被复制
let newFun = new Fun();
console.log(newFun.method); // 这样是访问不到的
console.log(Fun.method); // 必须这样才能访问到
2.Object.create
1.当复制对象时,会复制对象里的所有属性及方法
2.当复制函数对象时,只能复制proto上的属性,※自定义※的prototype也不能复制6
2
3
4
5
6
7
this.a = 2
}
var o1 = new Base();
var o2 = Object.create(Base);
console.log(o1.a); // 2
console.log(o2.a); // undefined 失去了原来对象的属性的访问
5.3.1 检查类的关系
检查一个实例的继承祖先通常被称为内省(或者反射) 。
第一种判断:instanceof回答的问题是:在 a 的整条 [[Prototype]] 链中是否有指向 Foo.prototype 的对象?
这种方法只能处理对象(左边)和函数(右边)的关系,不能处理对象和对象的关系!
第二种判断:b.isPrototypeOf( a ); // true回答的问题是:在 a 的整条 [[Prototype]] 链中是否出现过 b ?
可以判断对象和对象之间的关系!
第三种方法:
ES5提供了获取一个对象的 [[Prototype]] 链的方法Object.getPrototypeOf( a );
所以就产生了第三种方法1
2
3Object.getPrototypeOf( a ) === Foo.prototype; // true
//浏览器在以前就有这个功能,像下边这样
a.__proto__ === Foo.prototype; // true
.__proto__ 实际上并不存在于你正在使用的对象中(本例中是 a ) 它和其他的常用函数( .toString() 、 .isPrototypeOf(..) ,等等)一样,存在于内置的 Object.prototype 中。
实现原理:1
2
3
4
5
6
7
8
9
10Object.defineProperty( Object.prototype, "__proto__", {
get: function() {
return Object.getPrototypeOf( this );
},
set: function(o) {
// ES6 中的 setPrototypeOf(..)
Object.setPrototypeOf( this, o );
return o;
}
} );
.__proto__一般被叫做“笨蛋(dunder)proto”
最好把 [[Prototype]] 对象关联看作是只读特性不要进行修改,从而增加代码的可读性。
补充:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//情况1
function Person(name) {
this.name = name
}
// 修改原型
Person.prototype.getName = function() {}
var p = new Person('jack')
console.log(p.__proto__ === Person.prototype) // true
console.log(p.__proto__ === p.constructor.prototype) // true
//情况2
function Person(name) {
this.name = name
}
// 重写原型
Person.prototype = { //prototype被重写,所以p.constructor指向了别处
getName: function() {}
}
var p = new Person('jack')
console.log(p.__proto__ === Person.prototype) // true
console.log(p.__proto__ === p.constructor.prototype) // false
5.4 对象关联
5.4.1 创建关联
Object.create(..) 会创建一个新对象( bar )并把它关联到我们指定的对象( foo ) ,这样我们就可以充分发挥 [[Prototype]] 机制的威力(委托)并且避免不必要的麻烦(比如使用 new 的构造函数调用会生成 .prototype 和 .constructor 引用) 。Object.create(null) 会 创 建 一 个 拥 有 空( 或 者 说 null ) [[Prototype]]
链接的对象,这个对象无法进行委托。由于这个对象没有原型链,所以
instanceof 操作符(之前解释过)无法进行判断,因此总是会返回 false 。
这些特殊的空 [[Prototype]] 对象通常被称作字典 ,它们完全不会受到原
型链的干扰,因此非常适合用来存储数据。
Object.create(..)是ES5新增函数,为了向下兼容,创建polyfill(腻子)代码1
2
3
4
5
6
7if (!Object.create) {
Object.create = function(o) {
function F(){}
F.prototype = o;
return new F();
};
}
ES5提供的这个函数其实还支持第二参数,这第二个参数指定了需要添加到新对象中的属性名以及这些属性的属性描述符,但是这个polyfill却不支持,并且无法实现
使用方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14var myObject = Object.create( anotherObject, {
b: {
enumerable: false,
writable: true,
configurable: false,
value: 3
},
c: {
enumerable: true,
writable: false,
configurable: false,
value: 4
}
});
5.4.2 关联关系是备用
1 | var myObject = Object.create( anotherObject ); |
如果你这样写只是为了让myObject 在无法处理属性或者方法时使用备用的 anotherObject ,那么你的软件就会变得有点“神奇” ,(myObject上明明没有这个属性,却被访问到了),而且很难理解和维护。
ES6 中有一个被称为代理 (Proxy)的高端功能,它实现的就是方法无法找到时的行为。
修改方案:直接委托改为内部委托1
2
3
4
5
6
7
8
9
10var anotherObject = {
cool: function() {
console.log( "cool!" );
}
};
var myObject = Object.create( anotherObject );
myObject.doCool = function() {
this.cool(); // 内部委托! 重点呦
};
myObject.doCool(); // "cool!"
内部委托比起直接委托可以让 API 接口设计更加清晰
6 行为委托
JavaScript 中这个机制的本质就是对象之间的关联关系。
6.1 面向委托的设计
像封装或者其他时候,也还是需要面向类的思想的,保留一小部分即可!
6.1.1 类理论 ★
类设计模式鼓励你在继承时使用方法重写(和多态)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Task {
id;
// 构造函数 Task()
Task(ID) { id = ID; }
outputTask() { output( id ); }
}
class XYZ inherits Task {
label;
// 构造函数 XYZ()
XYZ(ID,Label) { super( ID ); label = Label; }
outputTask() { super(); output( label ); }
}
class ABC inherits Task {
// ...
}
6.1.2 委托理论
充分利用原型链1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Task = {
setID: function(ID) { this.id = ID; },
outputID: function() { console.log( this.id ); }
};
// 让 XYZ 委托 Task
XYZ = Object.create( Task );
XYZ.prepareTask = function(ID,Label) { //隐藏API
this.setID( ID );
this.label = Label;
};
XYZ.outputTaskDetails = function() {
this.outputID();
console.log( this.label );
};
// ABC = Object.create( Task );
// ABC ... = ...
关联风格代码应该注意:
- 在上面的代码中, id 和 label 数据成员都是直接存储在 XYZ 上(而不是 Task ) 。通常
来说,在[[Prototype]]委托中最好把状态保存在委托者( XYZ 、 ABC )而不是委托目标
( Task )上。 - 在类设计模式中,我们故意让父类( Task )和子类( XYZ )中都有 outputTask 方法,这
样就可以利用重写(多态)的优势。在委托行为中则恰好相反:我们会尽量避免在[[Prototype]]链的不同级别中使用相同的命名,否则就需要使用笨拙并且脆弱的语法
来消除引用歧义(参见第 4 章) 。 - this.setID(ID) ; XYZ 中的方法首先会寻找 XYZ 自身是否有 setID(..) ,但是 XYZ 中并没
有这个方法名,因此会通过[[Prototype]]委托关联到 Task 继续寻找,这时就可以找到
setID(..) 方法。此外,由于调用位置触发了 this 的隐式绑定规则(参见第 2 章) ,因
此虽然 setID(..) 方法在 Task 中,运行时 this 仍然会绑定到 XYZ ,这正是我们想要的。
在之后的代码中我们还会看到 this.outputID() ,原理相同。在 API 接口的设计中,委托最好在内部实现,不要直接暴露出去。在之前的例子中我们并没有让开发者通过 API 直接调用 XYZ.setID()。 相反我们把委托 隐藏 在了 API 的内部, XYZ.prepareTask(..) 会委托 Task.setID(..) 。
6.1.2.1 互相委托(禁止)
你无法在两个或两个以上互相(双向)委托的对象之间创建循环委托。
如果你把 B 关联到A 然后试着把 A 关联到 B ,就会出错。
如果你引用了一个两边都不存在的属性或者方法,那就会在 [[Prototype]] 链上产生一个无限递归的循环。
6.1.2.2 调试
1 | function Foo() {} |
6.1.2.3 比较思维模式
原型面向对象风格:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function Foo(who) {
this.me = who;
}
Foo.prototype.identify = function() {
return "I am " + this.me;
};
function Bar(who) {
Foo.call( this, who );
}
Bar.prototype = Object.create( Foo.prototype ); //原型继承
Bar.prototype.speak = function() {
alert( "Hello, " + this.identify() + "." );
};
var b1 = new Bar( "b1" );
var b2 = new Bar( "b2" );
b1.speak();
b2.speak();
对象关联风格;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Foo = {
init: function(who) {
this.me = who;
},
identify: function() {
return "I am " + this.me;
}
};
Bar = Object.create( Foo );
Bar.speak = function() {
alert( "Hello, " + this.identify() + "." );
};
var b1 = Object.create( Bar );
b1.init( "b1" );
var b2 = Object.create( Bar );
b2.init( "b2" );
b1.speak();
b2.speak();
不需要那些既复杂又令人困惑的模仿类的行为(构造函数、原型以及 new ) 。
6.2 类与对象
场景:创建 UI 控件(按钮、下拉列表,等等)
6.2.1 控件 “类”
思路:很快会想到一个包含所有通用控件行为的父类(可能叫作 Widget )和继承父类的特殊控件子类(比如 Button ) 。
方法1 -类风格1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// 父类
function Widget(width,height) {
this.width = width || 50;
this.height = height || 50;
this.$elem = null;
}
Widget.prototype.render = function($where){
if (this.$elem) {
this.$elem.css( {
width: this.width + "px",
height: this.height + "px"
} ).appendTo( $where );
}
};
// 子类
function Button(width,height,label) {
// 调用“super”构造函数
Widget.call( this, width, height );
this.label = label || "Default";
this.$elem = $( "<button>" ).text( this.label );
}
// 让 Button“继承”Widget
Button.prototype = Object.create( Widget.prototype );
// 重写 render(..)
Button.prototype.render = function($where) {
// “super”调用
Widget.prototype.render.call( this, $where );
this.$elem.click( this.onClick.bind( this ) );
};
Button.prototype.onClick = function(evt) {
console.log( "Button '" + this.label + "' clicked!" );
};
$( document ).ready( function(){
var $body = $( document.body );
var btn1 = new Button( 125, 30, "Hello" );
var btn2 = new Button( 150, 40, "World" );
btn1.render( $body );
btn2.render( $body );
} );
方法二-ES6的class语法糖1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Widget {
constructor(width,height) {
this.width = width || 50;
this.height = height || 50;
this.$elem = null;
}
render($where){
if (this.$elem) {
this.$elem.css( {
width: this.width + "px",
height: this.height + "px"
} ).appendTo( $where );
}
}
}
class Button extends Widget {
constructor(width,height,label) {
super( width, height );
this.label = label || "Default";
this.$elem = $( "<button>" ).text( this.label );
}
render($where) {
super( $where );
this.$elem.click( this.onClick.bind( this ) );
}
onClick(evt) {
console.log( "Button '" + this.label + "' clicked!" );
}
}
$( document ).ready( function(){
var $body = $( document.body );
var btn1 = new Button( 125, 30, "Hello" );
var btn2 = new Button( 150, 40, "World" );
btn1.render( $body );
btn2.render( $body );
} );
实际上这里并没有真正的类, class 仍然是通过 [[Prototype]]机制实现的,因此我们仍然面临第 4 章至第 6 章提到的思维模式不匹配问题。
方法三-委托控件对象 ★1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39var Widget = {
init: function(width,height){
this.width = width || 50;
this.height = height || 50;
this.$elem = null;
},
insert: function($where){
if (this.$elem) {
this.$elem.css( {
width: this.width + "px",
height: this.height + "px"
} ).appendTo( $where );
}
}
};
var Button = Object.create( Widget );
Button.setup = function(width,height,label){
// 委托调用
this.init( width, height );
this.label = label || "Default";
this.$elem = $( "<button>" ).text( this.label );
};
Button.build = function($where) {
// 委托调用
this.insert( $where );
this.$elem.click( this.onClick.bind( this ) ); //拆开理解:click触发this.onClick这个函数,将这个函数绑定到this
};
Button.onClick = function(evt) {
console.log( "Button '" + this.label + "' clicked!" );
};
$( document ).ready( function(){
var $body = $( document.body );
var btn1 = Object.create( Button );
btn1.setup( 125, 30, "Hello" );
var btn2 = Object.create( Button );
btn2.setup( 150, 40, "World" );
btn1.build( $body );
btn2.build( $body );
} );
对象关联可以更好地支持关注分离(separation of concerns)原则,创建和初始化并不需要合并为一个步骤。
6.3 更简洁的设计
场景:有两个控制器对象,一个用来操作网页中的登录表单,另一个用来与服务器进行验证(通信) 。
方法一:类
传统的类设计模式中,我们会把基础的函数定义在名为 Controller 的类中,然后派生两个子类 LoginController 和 AuthController ,它们都继承自 Controller 并且重写了一些基础行为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96// 父类
function Controller() {
this.errors = [];
}
Controller.prototype.showDialog(title,msg) {
// 给用户显示标题和消息
};
Controller.prototype.success = function(msg) {
this.showDialog( "Success", msg );
};
Controller.prototype.failure = function(err) {
this.errors.push( err );
this.showDialog( "Error", err );
};
// 子类
function LoginController() {
Controller.call( this );
}
// 把子类关联到父类
LoginController.prototype =
Object.create( Controller.prototype );
LoginController.prototype.getUser = function() {
return document.getElementById( "login_username" ).value;
};
LoginController.prototype.getPassword = function() {
return document.getElementById( "login_password" ).value;
};
LoginController.prototype.validateEntry = function(user,pw) {
user = user || this.getUser();
pw = pw || this.getPassword();
if (!(user && pw)) {
return this.failure(
"Please enter a username & password!"
);
}
else if (user.length < 5) {
return this.failure(
"Password must be 5+ characters!"
);
}
// 如果执行到这里说明通过验证
return true;
};
// 重写基础的 failure()
LoginController.prototype.failure = function(err) {
// “super”调用
Controller.prototype.failure.call(
this,
"Login invalid: " + err
);
};
// 子类
function AuthController(login) { //这里传入LoginController
Controller.call( this );
// 合成
this.login = login; //这样this.login就有了LoginController的所有数据
} //【继承另外一个实例的方法】
// 把子类关联到父类
AuthController.prototype =
Object.create( Controller.prototype );
AuthController.prototype.server = function(url,data) {
return $.ajax( {
url: url,
data: data
} );
};
AuthController.prototype.checkAuth = function() {
var user = this.login.getUser();
var pw = this.login.getPassword();
if (this.login.validateEntry( user, pw )) {
this.server( "/check-auth",{
user: user,
pw: pw
} )
.then( this.success.bind( this ) )
.fail( this.failure.bind( this ) );
}
};
// 重写基础的 success()
AuthController.prototype.success = function() {
// “super”调用
Controller.prototype.success.call( this, "Authenticated!" );
};
// 重写基础的 failure()
AuthController.prototype.failure = function(err) {
// “super”调用
Controller.prototype.failure.call(
this,
"Auth Failed: " + err
);
};
var auth = new AuthController();
auth.checkAuth(
// 除了继承,我们还需要合成
new LoginController() //这里还是用到了类的集成(所以需要改进) 实例化后的LoginController以参数的形式传给AuthController
);
注意 AuthController 需要一个 LoginController 的实例来和登录表单进行交互,因此这个实例变成了一个数据属性。
另一个需要注意的是我们在继承的基础上进行了一些合成。 AuthController 需要使用LoginController ,因此我们实例化后者( new LoginController() )并用一个类成员属性this.login 来引用它,这样 AuthController 就可以调用 LoginController 的行为。
你 可能 想让 AuthController 继承 LoginController 或者相反,这样我们就通过继承链实现了 真正的合成 。但是这就是类继承在问题领域建模时会产生的问题,因为 AuthController 和 LoginController 都不具备对方的基础行为,所以这种继承关系是不恰当的。我们的解决办法是进行一些简单的合成从而让它们既不必互相继承又可以互相合作。
**方法二:反类 ★
对象关联风格1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63var LoginController = {
errors: [],
getUser: function() {
return document.getElementById(
"login_username"
).value;
},
getPassword: function() {
return document.getElementById(
"login_password"
).value;
},
validateEntry: function(user,pw) {
user = user || this.getUser();
pw = pw || this.getPassword();
if (!(user && pw)) {
return this.failure(
"Please enter a username & password!"
);
}
else if (user.length < 5) {
return this.failure(
"Password must be 5+ characters!"
);
}
// 如果执行到这里说明通过验证
return true;
},
showDialog: function(title,msg) {
// 给用户显示标题和消息
},
failure: function(err) {
this.errors.push( err );
this.showDialog( "Error", "Login invalid: " + err );
}
};
// 让 AuthController 委托 LoginController //这里很重要
var AuthController = Object.create( LoginController );
AuthController.errors = [];
AuthController.checkAuth = function() {
var user = this.getUser();
var pw = this.getPassword();
if (this.validateEntry( user, pw )) {
this.server( "/check-auth",{
user: user,
pw: pw
} )
.then( this.accepted.bind( this ) )
.fail( this.rejected.bind( this ) );
}
};
AuthController.server = function(url,data) {
return $.ajax( {
url: url,
data: data
} );
};
AuthController.accepted = function() {
this.showDialog( "Success", "Authenticated!" )
};
AuthController.rejected = function(err) {
this.failure( "Auth Failed: " + err );
};
由于 AuthController 只是一个对象( LoginController 也一样) ,因此我们不需要实例化(比如 new AuthController() ) ,只需要一行代码就行:1
AuthController.checkAuth();
借助对象关联,你可以简单地向委托链上添加一个或多个对象,而且同样不需要实例化:1
2var controller1 = Object.create( AuthController );
var controller2 = Object.create( AuthController );
这种模式的重点在于只需要两个实体( LoginController 和 AuthController ) ,而之前的模式需要三个。
最后,我们避免了面向类设计模式中的多态。我们在不同的对象中没有使用相同的函
数名 success(..) 和 failure(..) ,这样就不需要使用丑陋的显示伪多态。相反,在
AuthController 中它们的名字是 accepted(..) 和 rejected(..) ——可以更好地描述它们的
行为。
6.4 更好的语法 –并不推荐
ES6 的 class 语法可以简洁地定义类方法,这个特性让class 乍看起来更有吸引力(附录A 会介绍为什么要避免使用这个特性) :1
2
3class Foo {
methodName() { /* .. */ }
}
简洁方法声明:1
2
3
4
5
6
7
8
9
10
11var LoginController = {
errors: [],
// 并不好使,反词法会介绍
getUser() { // 妈妈再也不用担心代码里有 function 了!,但是仍然要使用,分隔,但是不需要class语法了
// ...
},
getPassword() {
// ...
}
// ...
};
改进之前的 AuthController 的 定 义
用 Object.setPrototypeOf(..) 来修改它的 [[Prototype]],即代替Object.create()1
2
3
4
5
6
7
8
9
10
11
12
13// 使用更好的对象字面形式语法和简洁方法
var AuthController = {
errors: [],
checkAuth() {
// ...
},
server(url,data) {
// ...
}
// ...
};
// 现在把 AuthController 关联到 LoginController
Object.setPrototypeOf( AuthController, LoginController ); //代替Object.create()
6.4.1 反词法
简洁方法的非常重要的缺点:它是匿名表达式1
2
3
4
5
6
7
8
9var Foo = {
bar() { /*..*/ },
baz: function baz() { /*..*/ }
};
//去掉语法糖后
var Foo = {
bar: function() { /*..*/ }, //缺少函数名
baz: function baz() { /*..*/ }
};
匿名函数表达式的三大主要缺点:
- 调试栈更难追踪;
- 自我引用(递归、事件(解除)绑定,等等)更难;
- 代码(稍微)更难理解。
简洁方法没有1和3的缺点,却无法避免第2个缺点
所以还是不推荐简洁写法。
6.5 内省
自省就是检查实例的类型。
从语法角度来说, instanceof 似乎是检查 a1 和 Foo 的关系,但是实际上它想说的是 a1 和 Foo.prototype (引用的对象)是互相关联的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function Foo() { /* .. */ }
Foo.prototype...
function Bar() { /* .. */ }
Bar.prototype = Object.create( Foo.prototype );
var b1 = new Bar( "b1" );
// 让 Foo 和 Bar 互相关联
Bar.prototype instanceof Foo; // true
Object.getPrototypeOf( Bar.prototype )=== Foo.prototype; // true
Foo.prototype.isPrototypeOf( Bar.prototype ); // true
// 让 b1 关联到 Foo 和 Bar
b1 instanceof Foo; // true
b1 instanceof Bar; // true
Object.getPrototypeOf( b1 ) === Bar.prototype; // true
Foo.prototype.isPrototypeOf( b1 ); // true
Bar.prototype.isPrototypeOf( b1 ); // true
还有鸭子类型 -这个术语源自这句格言“如果看起来像鸭子,叫起来像鸭子,那就一定是鸭子。 ”
1 | if (a1.something) { |
假设如果 a1 通过了测试 a1.something 的话,那 a1 就一定能调用 .something() (无论这个方法存在于 a1 自身还是委托到其他对象) 。这个假设的风险其实并不算很高。
ES6 的 Promise 就是典型的“鸭子类型”
出于各种各样的原因,我们需要判断一个对象引用是否是 Promise,但是判断的方法是检查对象是否有 then() 方法。换句话说,如果对象有 then() 方法,ES6 的 Promise 就会认为这个对象是“可持续” (thenable)的,因此会期望它具有 Promise 的所有标准行为。
如果有一个不是 Promise 但是具有 then() 方法的对象,那你千万不要把它用在 ES6 的Promise 机制中,否则会出错。
所以证明了鸭子类型很危险应该避免
使用对象关联时,所有的对象都是通过 [[Prototype]] 委托互相关联,下面是内省的方法,非常简单:1
2
3
4
5
6
7
8
9
10
11
12
13var Foo = { /* .. */ };
var Bar = Object.create( Foo );
Bar...
var b1 = Object.create( Bar );
// 让 Foo 和 Bar 互相关联
Foo.isPrototypeOf( Bar ); // true
Object.getPrototypeOf( Bar ) === Foo; // true
// 让 b1 关联到 Foo 和 Bar
Foo.isPrototypeOf( b1 ); // true
Bar.isPrototypeOf( b1 ); // true
Object.getPrototypeOf( b1 ) === Bar; // true
现在我们想问的问题是“你是我的原型吗?”就可以判断了!
附录 ES6中的Class
class
6.2.1的方法二,就是通过ES6的class来完成的
下边说一下他解决了什么问题:
- 不再引用杂乱的 .prototype 了
- 不再需要通过Object.create(..) 来替换 .prototype 对象
- 可以通过 super(..) 来实现相对多态,这样任何方法都可以引用原型链上层的同名方法。
- 不能声明属性(只能声明方法)
- 可以通过 extends 很自然地扩展对象(子)类型,甚至是内置的对象(子)类型
class的陷阱
class 基本上只是现有 [[Prototype]] (委托!)机制的一种语法糖。
也就是说,创建子类的时候,并不是复制操作
可以理解为1
class c == c.prototype
所以修改c.prototype就相当于直接修改c的属性
所以也可以通过c.prototype来实现实例共享属性
问题一:如果使用 this.count++ 的话,我们会很惊讶地发现在对象 c1 和 c2 上都创建了 .count 属性,而不是更新共享状态。
问题二:会出现意外屏蔽
问题三: super 并不是动态绑定的,它会在声明时“静态”绑定。
1 | //问题一 |
1 | //问题二 |
1 | //问题三 |
toMethod(..) 会复制方法并把 homeObject 当作第一个参数(也就是我们传入的 E ) ,第二个参数(可选)是新方法的名称(默认是原方法名) 。
静态大于动态吗
ES6 的 class 最大的问题在于, (像传统的类一样)它的语法有时会让你认为,定义了一个 class 后,它就变成了一个(未来会被实例化的)东西的静态定义(不可修改就叫静态-个人理解)。
传统面向类的语言中,类定义之后就不会进行修改,所以类的设计模式就不支持修改。但是 JavaScript 最强大的特性之一就是它的动态性,任何对象的定义都可以修改(除非你把它设置成不可变) 。
class 似乎不赞成这样做,所以强制让你使用丑陋的 .prototype 语法以及 super 问题,等等。而且对于这种动态产生的问题, class 基本上都没有提供解决方案。
class 似乎想告诉你: “动态太难实现了,所以这可能不是个好主意。这里有一种看起来像静态的语法,所以编写静态代码吧。 ”
中册
1. 类型
1.2 内置类型
JavaScript 有七种内置类型:
• 空值( null )
• 未定义( undefined )
• 布尔值( boolean )
• 数字( number )
• 字符串( string )
• 对象( object )
• 符号( symbol ,ES6 中新增)
1 | // ES6中新加入的类型 |
使用复合条件来检测 null 值的类型:1
2var a = null;
(!a && typeof a === "object"); // true
函数对象的 length 属性是其声明的参数的个数:1
2
3
4function a(b,c) {
/* .. */
}
a.length; // 2 参数个数
1.3 值和类型
JavaScript 中的变量是没有类型的,只有值才有。变量可以随时持有任何类型的值。
1.3.1 undefined 和 undeclared
1 | var a; |
typeof 有一个特殊的安全防范机制。
对于 undeclared(或者 not defined)变量, typeof 照样返回 “undefined” 。
1.3.2 typeof Undeclared
如果在 if 语句中使用 var atob ,声明会被提升。到作用域(即当前脚本或函数的作用域)的最顶层,即使 if 条件不成立也是如此。
对于一些特殊的内建全局变量(通常称为“宿主对象”,host object),这样的重复声明会报错。
去掉 var 则可以防止声明被提升。
访问不存在的对象属性(甚至是在全局对象 window 上)不会产生ReferenceError 错误。
设置全局变量注意:
方法一:检查你用到的变量是否已经在宿主程序中定义过1
typeof FeatureXYZ !== "undefined"
方法二:依赖注入,将依赖通过参数显式地传递到函数中
因为作为参数,所以存在或者不存在都不会报错1
2
3
4
5
6function doSomethingCool(FeatureXYZ) {
var helper = FeatureXYZ ||
function() { /*.. default feature ..*/ };
var val = helper();
// ..
}
2.值
2.1 数组
使用 delete 运算符可以将单元从数组中删除,但是请注意,单元删除后,数组的 length 属性并不会发生变化。
“稀疏”数组(sparse array):即含有空白或空缺单元的数组
数组也可以包含字符串键值和属性(但这些并不计算在数组长度内)1
2
3
4
5
6var a = [ ];
a[0] = 1;
a["foobar"] = 2;
a.length; // 1 不计算到数组长度
a["foobar"]; // 2 但是可以访问到通过键值
a.foobar; // 2 但是可以访问到通过键值
字符串键值能够被强制类型转换为十进制数字的话,它就会被当作数字索引来处理。1
2
3var a = [ ];
a["13"] = 42; // 被当做索引,而不是键值
a.length; // 14 长度发生改变
类数组
工具函数slice()来转换1
2
3
4
5
6function foo() {
var arr = Array.prototype.slice.call( arguments );
arr.push( "bam" );
console.log( arr );
}
foo( "bar", "baz" ); // ["bar","baz","bam"]
ES6内置工具函数Array.from(arguments)也能实现同样功能
稀疏数组1
2var a = [,1,,]; // 稀疏数组
var b = [undefined,1,undefined];
绝对相等是看不出区别的
1 | for(var i = 0; i < a.length; i++){ |
hasOwnProperty可以看出区别
1 | var hasOwnProp = Object.prototype.hasOwnProperty; |
forEach,map,filter等,函数会跳过那些稀疏的位置
2.2 字符串
字符串和字符串数组的区别:1
2var c = a.concat( "bar" ); // "foobar"
var d = b.concat( ["b","a","r"] ); // ["f","o","o","b","a","r"]
c是新字符串,不是a字符串的扩充
JavaScript 中字符串是不可变的,而数组是可变的。
字符串可以通过“借用”数组的方法来处理字符串。
例如借用join方法:1
var c = Array.prototype.join.call( a, "-" );
字符串反转方法:字符串无法借用数组的reverse方法,所以通过下边变通方法实现!1
2
3
4
5
6
7
8var c = a
// 将a的值转换为字符数组
.split( "" )
// 将数组中的字符进行倒转
.reverse()
// 将数组中的字符拼接回字符串
.join( "" );
c; // "oof"
但是:上述方法对于包含复杂字符(Unicode,如星号、多字节字符等)的字符串并不适用。这时则需要功能更加完备、能够处理 Unicode 的工具库。
参考高级程序设计5.2.5
2.3 数字
JavaScript 中的“整数”就是没有小数的十进制数。
所以 42.0 即等同于“整数” 42 。
所以JavaScript 没有真正意义上的整数。
JavaScript 中的数字类型是基于 IEEE 754 标准来实现的,该标准通常也被称为浮点数。
JavaScript 使用的是双精度格式(即 64 位二进制)。
2.3.1 数字的语法
数字前面的 0 可以省略:1
var b = .42;
小数点后小数部分最后面的 0 也可以省略:1
var b = 42.; // 42. 这种写法没问题
特别大和特别小的数字默认用指数格式显示,与 toExponential() 函数的输出结果相同。1
2
3var a = 5E10;
a; // 50000000000
a.toExponential(); // "5e+10"
tofixed(..)方法可指定小数部分的显示位数1
2
3var a = 42
a.toFixed( 0 ); // "43"
a.toFixed( 1 ); // "42.0" 自动补0
toPrecision(..)方法用来指定有效数位的显示位数:不是只有小数点后1
2
3
4
5
6var a = 42.59;
a.toPrecision( 1 ); // "4e+1"
a.toPrecision( 2 ); // "43"
a.toPrecision( 3 ); // "42.6"
a.toPrecision( 4 ); // "42.59"
a.toPrecision( 5 ); // "42.590"
. 运算符需要给予特别注意,因为它是一个有效的数字字符,会被优先识别为数字常量的一部分,然后才是对象属性访问运算符。1
2
3
4
5
6
7// 无效语法:
42.toFixed( 3 ); // SyntaxError
// 下面的语法都有效:
(42).toFixed( 3 ); // "42.000"
0.42.toFixed( 3 ); // "0.420"
42..toFixed( 3 ); // "42.000"
42 .toFixed(3); // "42.000" 空格也是有效的
数字常量还可以用其他格式来表示,如二进制、八进制和十六进制。1
2
30xf3; // 243的十六进制
0Xf3; // 同上
0363; // 243的八进制 从 ES6 开始,严格模式(strict mode)不再支持 0363 八进制格式,非严格模式中仍然受支持
2.3.2 较小的数值
二进制浮点数最大的问题,是会出现如下情况:
- 不仅 JavaScript,所有遵循 IEEE 754 规范的语言都是如此
1
0.1 + 0.2 === 0.3; // false 实际值为 0.30000000000000004
那么应该怎样来判断 0.1 + 0.2 和 0.3 是否相等呢?
最常见的方法是设置一个误差范围值,通常称为机器精度,对JavaScript 的数字来说,这个值通常是 2^-52 (2.220446049250313e-16) 。
从 ES6 开始,该值定义在 Number.EPSILON中,也可以为 ES6 之前的版本写 polyfill:1
2
3if (!Number.EPSILON) {
Number.EPSILON = Math.pow(2,-52);
}
可以使用 Number.EPSILON 来比较两个数字是否相等:1
2
3
4function numbersCloseEnoughToEqual(n1,n2) {
return Math.abs( n1 - n2 ) < Number.EPSILON;
}
numbersCloseEnoughToEqual( a, b );
最大浮点数大约是 1.798e+308,它定义在 Number.MAX_VALUE 中。
最小浮点数大约是 5e-324,它定义在 Number.MIN_VALUE 中
2.3.3 整数的安全范围
“整数”的安全值范围远远小于 Number.MAX_VALUENumber.MAX_SAFE_INTEGER表示最大整数是 2^53 - 1,即 9007199254740991Number.MIN_SAFE_INTEGER表示最小整数是 -(2^53 - 1),既 -9007199254740991
如果处理较大的数字!!
方法:将它们保存(转换)为字符串!!
推荐借助工具库
2.3.4 整数检测
ES6检测是否是整数通过Number.isInteger(..)1
2
3Number.isInteger( 42 ); // true
Number.isInteger( 42.000 ); // true
Number.isInteger( 42.3 ); // false
兼容 polyfill:1
2
3
4
5if (!Number.isInteger) {
Number.isInteger = function(num) {
return typeof num == "number" && num % 1 == 0;
};
}
ES6检测一个值是否是安全的整数通过Number.isSafeInteger(..)1
2Number.isSafeInteger( Number.MAX_SAFE_INTEGER ); // true
Number.isSafeInteger( Math.pow( 2, 53 ) ); // false
兼容 polyfill:1
2
3
4
5
6if (!Number.isSafeInteger) {
Number.isSafeInteger = function(num) {
return Number.isInteger( num ) &&
Math.abs( num ) <= Number.MAX_SAFE_INTEGER;
};
}
2.3.5 32 位有符号整数
虽然整数最大能够达到 53 位,但是有些数字操作(如数位操作)只适用于 32 位数字所以这些操作中数字的安全范围就要小很多,变成从 Math.pow(-2,31) ( -2147483648 ,约 - 21 亿)到 Math.pow(2,31) - 1 ( 2147483647 ,约 21 亿)。
a | 0 可以将变量 a 中的数值转换为 32 位有符号整数,因为数位运算符 | 只适用于 32 位整数(它只关心 32 位以内的值,其他的数位将被忽略)。
因此与 0 进行操作即可截取 a 中的 32 位数位。
NaN 和 Infinity ,此时会对它们执行虚拟操作ToInt32,以便转换为符合数位运算符要求的 +0 值。
2.4 特殊数值
2.4.1 不是值的值
undefined 类型是标识符且只有一个值,即 undefined 。null 类型是非标识符且也只有一个值,即 null 。
• null 指空值
• undefined 指没有值
或者:
• null 指曾赋过值,但是目前没有值
• undefined 指从未赋值
2.4.2 undefined
非严格模式和严格模式下,我们可以为 undefined 赋值
void 运算符
undefined 是一个内置标识符,它的值为 undefined ,通过 void 运算符即可得到该值。void ___ 没有返回值,因此返回结果是 undefined 。
void 并不改变表达式的结果,只是让表达式不返回值1
2var a = 42;
console.log( void a, a ); // undefined 42
用法:1
return void setTimeout( doSomething,100 ); // 只执行setTimeout 但是不返回值
2.4.3 特殊的数字
数字类型中有几个特殊的值
2.4.3.1. 不是数字的数字
NaN 意指不是一个数字(not a number),这个名字容易引起误会,后面将会提到。
将它理解为“无效数值”“失败数值”或者“坏数值”可能更准确些。
是数字类型,但是不是数字
NaN 是一个特殊值,它和自身不相等,是唯一一个非自反的值。
isNaN(..) 有一个严重的缺陷,它的检查方式过于死板,就是“检查参数是否不是 NaN ,也不是数字”。1
2var b = "foo";
window.isNaN( b ); // true——晕!
ES6可以使用工具函数 Number.isNaN(..) 。
ES6 之前的浏览器的 polyfill 如下:1
2
3
4
5
6
7
8
9
10
11
12if (!Number.isNaN) {
Number.isNaN = function(n) {
return (
typeof n === "number" &&
window.isNaN( n )
);
};
}
var a = 2 / "foo";
var b = "foo";
Number.isNaN( a ); // true
Number.isNaN( b ); // false——好!
更简单的方法!!!
利用 NaN 不等于自身这个特点!!1
2
3
4
5if (!Number.isNaN) {
Number.isNaN = function(n) {
return n !== n;
};
}
2.4.3.2 无穷数
JavaScript 的运算结果溢出,此时结果为Infinity 或者 -Infinity 。1
2var a = 1 / 0; // Infinity 即Number.POSITIVE_INfiNITY
var b = -1 / 0; // -Infinity 即 Number.NEGATIVE_INfiNITY
计算结果一旦溢出为无穷数(infinity)就无法再得到有穷数。
Infinity/Infinity 是一个未定义操作,结果为 NaN 。
有穷正数/Infinity ,结果是 0 。
有穷负数/Infinity ,结果是 -0 。
2.4.3.3 零值
JavaScript 有一个常规的 0 (也叫作 +0 )和一个 -0 。
加法和减法运算不会得到负零。
乘法和除法运算会得到负零。
对负零进行字符串化和JSON.stringify()和比较操作都会返回 “0”1
2
3
4
5var a = 0 / -3;
a.toString(); // "0" 而非 "-0"
JSON.stringify( a ); // "0"
-0 == 0; // true
0 > -0; // false
字符串转数字及JSON.parse()会返回”-0”1
2
3+"-0"; // -0
Number( "-0" ); // -0
JSON.parse( "-0" ); // -0
判断是0还是-0的函数1
2
3
4
5
6function isNegZero(n) {
n = Number( n );
return (n === 0) && (1 / n === -Infinity); // 取右侧
}
isNegZero( -0 ); // true
isNegZero( 0 ); // false
用途:
如动画帧的移动速度和移动的方向等等
2.4.4 特殊等式
ES6加入Object.is(..)来判断两个值是否绝对相等1
2
3
4
5var a = NaN;
var b = -0;
Object.is( a, NaN ); // true
Object.is( b, -0 ); // true
Object.is( b, 0 ); // false 用来判断 -0 === 0
兼容 polyfill:1
2
3
4
5
6
7
8
9
10
11
12
13
14if (!Object.is) {
Object.is = function(v1, v2) {
// 判断是否是-0
if (v1 === 0 && v2 === 0) {
return 1 / v1 === 1 / v2; // 实际比较的是 -Infinity === Infinity
}
// 判断是否是NaN
if (v1 !== v1) {
return v2 !== v2;
}
// 其他情况
return v1 === v2;
};
}
能使用 == 和 === 时就尽量不要使用 Object.is(..) ,因为前者效率更高、更为通用。
2.5 值和引用
简单值总是通过值复制的方式来赋值 / 传递,包括null 、 undefined 、字符串、数字、布尔和 ES6 中的 symbol 。
复合值总是通过引用复制的方式来赋值 / 传递,包括对象(数组和封装对象)和函数。
如果通过值复制的方式来传递复合值(如数组),就需要为其创建一个复本,这样传递的就不再是原始值。slice(..) 不带参数会返回当前数组的一个浅复本。
3.原生函数
常用的原生函数有:
• String()
• Number()
• Boolean()
• Array()
• Object()
• Function()
• RegExp()
• Date()
• Error()
• Symbol() ——ES6 中新加入的!
1 | String {0: "a", 1:"b", 2: "c", length: 3, [[PrimitiveValue]]: "abc"} |
注意:new String(“abc”) 创建的是字符串 “abc” 的封装对象,而非基本类型值 “abc” 。
3.1 内部属性 [[Class]]
无法直接访问,一般通过 Object.prototype.toString(..) 来查看1
2Object.prototype.toString.call( [1,2,3] );
// "[object Array]" 这个就是Class
3.2 封装对象包装
基本类型会自动被包装(box 或者 wrap)成封装对象:1
2var a = "abc";
a.length; // 3 基本类型本来是没有length方法的
注意:1
2
3
4var a = new Boolean( false ); // 返回true!!!!
if (!a) {
console.log( "Oops" ); // 执行不到这里
}
想要自行封装基本类型值,可以使用 Object(..) 函数(不带 new 关键字):1
2
3
4
5
6var a = "abc";
var b = new String( a );
var c = Object( a );
typeof a; // "string"
typeof b; // "object"
typeof c; // "object"
3.3 拆封
得到封装对象中的基本类型值,可以使用 valueOf() 函数。1
2
3
4
5
6
7var a = new String( "abc" );
var b = new Number( 42 );
var c = new Boolean( true );
// 以下是拆封
a.valueOf(); // "abc"
b.valueOf(); // 42
c.valueOf(); // true
3.4 原生函数作为构造函数
使用常量([]、{})和使用构造函数的效果是一样的(创建的值都是通过封装对象来包装)。
3.4.1 Array(..)
构造函数 Array(..) 不要求必须带 new 关键字。不带时,它会被自动补上。
Array 构造函数只带一个数字参数的时候,该参数会被作为数组的预设长度(length),而非只充当数组中的一个元素。
所以导致,有的数组含有长度但是却没有任何单元,这一切都归咎于已被废止的旧特性(类似 arguments 这样的类数组)。
我们将包含至少一个空单元的数组称为稀疏数组。
通过 delete 制造出一个空单元。
ES5 规范开始就允许在列表(数组值、属性列表等)末尾多加一个逗号。
所以如果你在代码或者调试控制台中输入 [ , , , ] ,实际得到的是 [ , , ] (包含三个空单元的数组)。
1 | var a = new Array( 3 ); // [ undefined x 3 ] |
a.map(..) 之所以执行失败,是因为数组中并不存在任何单元,所以 map(..) 无从遍历。
通过下述方式来创建包含 undefined 单元(而非“空单元”)的数组:1
2var a = Array.apply( null, { length: 3 } ); // 解释可以再细看下书
a; // [ undefined, undefined, undefined ]
3.4.2 Object(..) 、 Function(..) 和 RegExp(..)
构造函数 Function 只在极少数情况下很有用,比如动态定义函数参数和函数体的时候。
强烈建议使用常量形式(如 /^a*b+/g )来定义正则表达式,这样不仅语法简单,执行效率也更高,
因为 JavaScript 引擎在代码执行前会对它们进行预编译和缓存。
与前面的构造函数不同, RegExp(..) 有时还是很有用的,比如动态定义正则表达式时:1
2
3var name = "Kyle";
var namePattern = new RegExp( "\\b(?:" + name + ")+\\b", "ig" ); // 动态name 其实就是一个变量
var matches = someText.match( namePattern );
3.4.3 Date(..) 和 Error(..)
没有对应的常量形式来作为它们的替代。
Date(..) 主要用来获得当前的 Unix 时间戳,通过getTime()来获得(以秒为单位)
如果调用 Date() 时不带 new 关键字,则会得到当前日期的字符串值。 “Fri Jul 18 2014 00:31:02 GMT-0500 (CDT)”
ES5引入静态函数 Date.now()
兼容版本polyfill:1
2
3
4
5if (!Date.now) {
Date.now = function(){
return (new Date()).getTime();
};
}
构造函数 Error(..) (与前面的 Array() 类似)带不带 new 关键字都可。
错误对象通常与 throw 一起使用:1
2
3
4
5
6function foo(x) {
if (!x) {
throw new Error( "x wasn’t provided" );
}
// ..
}
除 Error(..) 之外,还有一些针对特定错误类型的原生构造函数,如EvalError(..)、RangeError(..)、ReferenceError(..)、SyntaxError(..)、TypeError(..) 和 URIError(..) 。这些构造函数很少被直接使用,它们在程序发生异常(比如试图使用未声明的变量产生 ReferenceError 错误)时会被自动调用。
3.4.4 Symbol(..)
ES6 中新加入了一个基本数据类型 ——符号(Symbol)。
符号是具有唯一性的特殊值(并非绝对),用它来命名对象属性不容易导致重名
符号可以用作属性名,但无论是在代码还是开发控制台中都无法查看和访问它的值,
只会显示为诸如 Symbol(Symbol.create) 这样的值。
一些预定义符号,以 Symbol 的静态属性形式出现,
如 Symbol.create 、 Symbol.iterator 等,可以这样来使用:1
obj[Symbol.iterator] = function(){ /*..*/ };
使用 Symbol(..) 原生构造函数来自定义符号。
但它比较特殊,不能带 new 关键字,否则会出错:1
2
3
4
5
6
7var mysym = Symbol( "my own symbol" );
mysym; // Symbol(my own symbol)
mysym.toString(); // "Symbol(my own symbol)"
typeof mysym; // "symbol"
var a = { };
a[mysym] = "foobar";
Object.getOwnPropertySymbols( a ); // [ Symbol(my own symbol) ]
符号实际上并非私有属性(通过 Object.getOwnPropertySymbols(..) 便可以公开获得对象中的所有符号)
3.4.5 原生原型
原生构造函数有自己的 .prototype 对象,如 Array.prototype 、 String.prototype 等。
String的方法返回的都是一个新字符串
有些原生原型(native prototype)并非普通对象那么简单:1
2
3
4
5typeof Function.prototype; // "function"
Function.prototype(); // 空函数!
Array.prototype; // 空数组
RegExp.prototype.toString(); // "/(?:)/" —— 空正则表达式
"abc".match( RegExp.prototype ); // [""]
这些空对象可以很好的作为默认值
这种方法的一个好处是 .prototypes 已被创建并且仅创建一次。
相反,如果将 [] 、function(){} 和 /(?:)/ 作为默认值,则每次调用都会被创建一次
(具体创建与否取决于 JavaScript 引擎,稍后它们可能会被垃圾回收),这样无疑会造成内存和 CPU 资源的浪费。
注意:
如果默认值随后会被更改,那就不要使用 Array.prototype 。
4.强制类型转换
4.1 值类型转换
类型转换发生在静态类型语言的编译阶段,而强制类型转换则发生在动态类型语言的运行时(runtime)。
类型转换:String()
强制类型转换:+ 转换为字符串1
2
3
4
5
6
7
8
9var a = 42;
var b = a + "2"; // 隐式强制类型转换- 转为字符串
var c = String( a ); // 显式强制类型转换
console.log( 42 +'2') // 422
console.log('2'+ 42) // 242
console.log(2 + +'2') // 4 特殊
console.log(+'2'+2) // 4 特殊
console.log(typeof +'2') // number
结论: + 运算符的其中一个操作数是字符串,所以是字符串拼接操作。
4.2 抽象值操作
4.2.1 ToString
数字的字符串化则遵循通用规则,不过第 2 章中讲过的那些极小和极大的数字使用指数形式:1
2
3
4// 1.07 连续乘以七个 1000
var a = 1.07 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000;
// 七个1000一共21位数字
a.toString(); // "1.07e21"
对普通对象来说,除非自行定义,否则 toString() ( Object.prototype.toString() )返回内部属性 [[Class]] 的值(参见第 3 章),如 “[object Object]” 。
将对象强制类型转换为 string 是通过 ToPrimitive 抽象操作来完成的(ES5规范,9.1 节)
数组的默认 toString() 方法经过了重新定义,将所有单元字符串化以后再用 “,” 连接起来:1
2var a = [1,2,3];
a.toString(); // "1,2,3"
JSON 字符串化和 toString() 的效果基本相同,只不过序列化的结果总是字符串:1
2
3
4JSON.stringify( 42 ); // "42"
JSON.stringify( "42" ); // ""42"" (含有双引号的字符串)
JSON.stringify( null ); // "null"
JSON.stringify( true ); // "true"
不安全的 JSON 值: undefined 、 function 、 symbol(ES6+)和包含循环引用(对象之间相互引用,形成一个无限循环)的 对象 都不符合 JSON结构标准,支持 JSON 的语言无法处理它们。
JSON.stringify(..) 在对象中遇到 undefined 、 function 和 symbol 时会自动将其忽略,在数组中则会返回 null (以保证单元位置不变)。1
2
3
4
5
6
7
8JSON.stringify( undefined ); // undefined
JSON.stringify( function(){} ); // undefined
JSON.stringify(
[1,undefined,function(){},4]
); // "[1,null,null,4]"
JSON.stringify(
{ a:2, b:function(){} }
); // "{"a":2}"
对包含循环引用的对象执行 JSON.stringify(..) 会出错。
解决非法JSON字符串化,就需要定义 toJSON() 方法来返回一个安全的 JSON 值。toJSON() 应该“返回一个能够被字符串化的安全的 JSON 值”,而不是返回一个 JSON 字符串。1
2
3
4
5
6
7
8var a = {
val: [1,2,3],
// 可能是我们想要的结果!
toJSON: function(){
return this.val.slice( 1 );
}
};
JSON.stringify( a ); // "[2,3]"
如果对象中定义了 toJSON() 方法,JSON 字符串化时会首先调用该方法,然后用它的返回值来进行序列化。
不为人知的有用功能:
我们可以向 JSON.stringify(..) 传递一个可选参数 replacer,它可以是数组或者函数,
用来指定对象序列化过程中哪些属性应该被处理,哪些应该被排除,和 toJSON() 很像。
如果 replacer 是一个数组,那么它必须是一个字符串数组,其中包含序列化要处理的对象的属性名称,除此之外其他的属性则被忽略。
如果 replacer 是一个函数,它会对对象本身调用一次,然后对对象中的每个属性各调用一次,每次传递两个参数,键和值。如果要忽略某个键就返回 undefined ,否则返回指定的值。1
2
3
4
5
6
7
8
9
10var a = {
b: 42,
c: "42",
d: [1,2,3]
};
JSON.stringify( a, ["b","c"] ); // "{"b":42,"c":"42"}"
JSON.stringify( a, function(k,v){
if (k !== "c") return v;
} );
// "{"b":42,"d":[1,2,3]}"
解释:如果 replacer 是函数,它的参数 k 在第一次调用时为 undefined (就是对对象本身调用的那次)。
if 语句将属性 “c” 排除掉。
由于字符串化是递归的,因此数组 [1,2,3] 中的每个元素都会通过参数 v 传递给 replacer,即 1 、 2 和 3 ,参数 k 是它们的索引值,即 0 、 1 和 2 。
JSON.string 还有一个可选参数 space,用来指定输出的缩进格式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26var a = {
b: 42,
c: "42",
d: [1,2,3]
};
JSON.stringify( a, null, 3 );
// "{
// "b": 42,
// "c": "42",
// "d": [
// 1,
// 2,
// 3
// ]
// }"
JSON.stringify( a, null, "-----" );
// "{
// -----"b": 42,
// -----"c": "42",
// -----"d": [
// ----------1,
// ----------2,
// ----------3
// -----]
// }"
4.2.2 ToNumber
true 转换为 1 , false 转换为 0 。undefined 转换为 NaN , null 转换为 0 。
处理失败时返回 NaN
ToNumber 对以 0 开头的十六进制数并不按十六进制处理(而是按十进制,参见第 2 章)。
字符串的处理数字常量失败时会产生语法错误,返回 NaN
对象包括数组会首先被转换为相应的基本类型值,如果返回的是非数字的基本类型值,则再遵循以上规则将其强制转换为数字。
将值转换为相应的基本类型值,抽象操作 ToPrimitive会
首先检查该值是否有 valueOf() 方法。
1.如果有并且返回基本类型值
2.如果没有就使用 toString()的返回值来进行强制类型转换.
3.如果 valueOf() 和 toString() 均不返回基本类型值,会产生 TypeError 错误。
特例:Object.create(null) 创建的对象 [[Prototype]] 属性为 null ,并且没有 valueOf() 和 toString() 方法,因此无法进行强制类型转换。
1 | Number( "" ); // 0 空字符串也是0 |
4.2.3 ToBoolean
虽然我们可以将 1 强制类型转换为 true ,将 0 强制类型转换为 false ,但它们并不是一回事。
4.2.3.1 假值(falsy value)
以下这些是假值:
• undefined
• null
• false
• +0 、 -0 和 NaN
• “”
假值列表以外的值都是真值。
4.2.3.2 假值对象(falsy object)
1 | var a = new Boolean( false ); // 返回的是一个Objec而不是false |
常规 JavaScript 语法基础上自己创建了一些外来值,这些就是“假值对象”。
外来的像document.all由DOM(而不是 JavaScript 引擎)提供给 JavaScript 程序使用。
它以前曾是一个真正意义上的对象,布尔强制类型转换结果为 true ,不过现在它是一个假值对象。1
2Boolean(document.all) // false
new Boolean(document.all) // Object
4.2.3.3 真值(truthy value)
假值列表之外的值都是真值。""是假值列表中唯一的字符串。
4.3 显式强制类型转换
显式强制类型转换是那些显而易见的类型转换,很多类型转换都属于此列。
4.3.1 字符串和数字之间的显式转换
字符串和数字之间的转换是通过 String(..) 和 Number(..) 这两个内建函数来实现的,
请注意它们前面没有 new 关键字,并不创建封装对象。
其他转化方法:1
2
3
4
5
6var a = 42;
var b = a.toString(); // 42是基本类型是没有toString方法的,先用new Numner()来封装42为数字对象类型,之后调用这个toString
var c = "3.14";
var d = +c;
b; // "42"
d; // 3.14
42是基本类型是没有toString方法的,先用new Numner()来封装42为数字对象类型,之后调用这个toString+c 是 + 运算符的一元形式(即只有一个操作数)。+运算符显式地将 c 转换为数字,既不是数字加法运算,也不是字符串拼接。
当一元加法运算符对字符串进行操作时,它计算字符串的方式与 parseInt() 相似,主要的不同是只有对以 “0x” 开头的字符串(表示十六进制数字),一元运算符才能把它转换成十进制的值。因此,用一元加法转换 “010”,得到的总是 10,而 “0xB” 将被转换成 11。
注意:1
2
3var c = "3.14";
var d = 5+ +c;
d; // 8.14
一元运算符 - 和 + 一样,并且它还会反转数字的符号位。
由于 – 会被当作递减运算符来处理,所以我们不能使用 – 来撤销反转,而应该像 - -“3.14” 这样,在中间加一个空格,才能得到正确结果 3.14 。
一元运算符更多解释:
用途:
4.3.1.1 日期显式转换为数字
一元运算符 + 的另一个常见用途是将日期( Date )对象强制类型转换为数字,返回结果为 Unix 时间戳,以微秒为单位(从 1970 年 1 月 1 日 00:00:00 UTC 到当前时间):1
2var d = new Date( "Mon, 18 Aug 2014 08:53:06 CDT" );
+d; // 1408369986000 如果不用+则返回 Sat Feb 11 2017 11:26:25 GMT+0800 (中国标准时间) 这种UTC格式
平时用法:获得当前的时间戳1
2
3
4
5
6
7var timestamp = +new Date();
// 或
var timestamp = +new Date
// 或
var timestamp = new Date().getTime();
// 或
var timestamp = Date.now(); //ES6 语法
补充知识点:构造函数没有参数时可以不用带 ()
4.3.1.2 奇特的 ~ 运算符
~运算符:即字位操作“非”
在 2.3.5 节中,我们讲过字位运算符只适用于 32 位整数,运算符会强制操作数使用 32 位格式。
这是通过抽象操作 ToInt32 来实现的
ToInt32 首先执行 ToNumber 强制类型转换,比如 “123” 会先被转换为 123 ,然后再执行ToInt32 。
虽然严格说来并非强制类型转换(因为返回值类型并没有发生变化),
但字位运算符(如 | 和 ~ )和某些特殊数字一起使用时会产生类似强制类型转换的效果,返回另外一个数字。
例如 | 运算符(字位操作“或”)的空操作(no-op) 0 | x ,它仅执行 ToInt32 转换1
2
3
40 | -0; // 0
0 | NaN; // 0
0 | Infinity; // 0
0 | -Infinity; // 0
以上这些特殊数字无法以 32 位格式呈现,因此 ToInt32 返回 0 。
定义:~它首先将值强制类型转换为 32 位数字,然后执行字位操作“非”(对每一个字位进行反转)。
与 ! 很相像,不仅将值强制类型转换为布尔值 ,还对其做字位反转(参见 4.3.3 节)。
对 ~ 还可以有另外一种诠释,源自早期的计算机科学和离散数学: ~ 返回 2 的补码。
例如:
~x 大致等同于 -(x+1) 。
在 -(x+1) 中唯一能够得到 0 (或者严格说是 -0 )的 x 值是 -1 。
也就是说如果 x 为 -1 时, ~和一些数字值在一起会返回假值 0 ,其他情况则返回真值。
-1 是一个哨位值,哨位值是那些在各个类型中(这里是数字)被赋予了特殊含义的值。
>= 0 和 == -1 这样的写法不是很好,称为抽象渗漏,意思是在代码中暴露了底层的实现细节,
这里是指用 -1 作为失败时的返回值,这些细节应该被屏蔽掉。
可写成!=-1或<0
最好用~代替,来判断真假值
~ 和 indexOf() 一起可以将结果强制类型转换(实际上仅仅是转换)为真 / 假值1
2
3
4
5
6
7
8
9
10var a = "Hello World";
~a.indexOf( "lo" ); // -4 <-- 真值! 解释:a.indexOf( "lo" ) 结果为3 利用公式~x=(x+1) 得到 ~x = 3+1
if (~a.indexOf( "lo" )) { // true
// 找到匹配!
}
~a.indexOf( "ol" ); // 0 <-- 假值! 解释和上边一样操作转化
!~a.indexOf( "ol" ); // true
if (!~a.indexOf( "ol" )) { // true
// 没有找到匹配!
}
如果 indexOf(..) 返回 -1 , ~ 将其转换为假值 0 ,其他情况一律转换为真值。
由 -(x+1) 推断 ~-1 的结果应该是 -0 ,然而实际上结果是 0 ,因为它是字位操作而非数学运算。
4.3.1.3 字位截除
一些开发人员使用 ~~ 来截除数字值的小数部分,以为这和 Math.floor(..) 的效果一样,实际上并非如此。
~~ 中的第一个 ~ 执行 ToInt32 并反转字位,然后第二个 ~ 再进行一次字位反转,即将所有字位反转回原值,最后得到的仍然是 ToInt32 的结果。
~~ 它只适用于 32 位数字,更重要的是它对负数的处理与 Math.floor(..) 不同。1
2Math.floor( -49.6 ); // -50
~~-49.6; // -49
~~x 能将值截除为一个 32 位整数,
x | 0 (空操作,不需要两次取反)也可以,而且看起来还更简洁。
4.3.2 显式解析数字字符串
解析字符串中的数字和将字符串强制类型转换为数字的返回结果都是数字。
但解析和转换两者之间还是有明显的差别。1
2
3
4
5
6var a = "42";
var b = "42px";
Number( a ); // 42 转换
parseInt( a ); // 42 解析
Number( b ); // NaN
parseInt( b ); // 42
解析允许字符串中含有非数字字符,解析按从左到右的顺序,如果遇到非数字字符就停止。
而转换不允许出现非数字字符,否则会失败并返回 NaN 。
解析字符串中的浮点数可以使用 parseFloat(..) 函数。
parseInt(..) 针对的是字符串值。
向 parseInt(..) 传递数字和其他类型的参数是没有用的,比如 true 、 function(){…} 和 [1,2,3] 。
ES5 之前的 parseInt(..) 有一个坑导致了很多 bug。
即如果没有第二个参数来指定转换的基数(又称为 radix), parseInt(..) 会根据字符串的第一个字符来自行决定基数。
如果第一个字符是 x 或 X ,则转换为十六进制数字。
如果是 0 ,则转换为八进制数字。
例如:解析时间08和09时,会因为第一位是0,默认以8位解析,而第二位在八进制内是无效的,所以最后解析都为0
所以需要设置第二个参数才保险
ES5 开始 parseInt(..) 默认转换为十进制数,除非另外指定(检测到0也不会默认为八进制了)。
4.3.2.1 解析非字符串
1 | parseInt( 1/0, 19 ); // 18 |
正常(错误)思维:认为1/0结果为Infinity ,解析结果也应该是 Infinity ”,返回 18 也太无厘头了。
parseInt第一个参数应该是字符串
1 | var a = { |
第一步:先将参数强制类型转换为字符串
第二步:进行解析
回到第一个式子:
怎么来处理 Infinity ( 1/0 的结果)最合理呢?
有两个选择: “Infinity” 和 “∞” ,JavaScript选择的是 “Infinity” 。
所以:
实际上是 parseInt(“Infinity”, 19) 。
第一个字符是 “I” ,以 19 为基数时值为 18 。
第二个字符 “n” 不是一个有效的数字字符,解析到此为止,和 “42px” 中的 “p”一样。
个人思考:再识别第一个字符I设置基数的时候,如果不是ES5之前的版本,那结果是不是就不一样了呢!
其他例子:1
2
3
4
5
6parseInt( 0.000008 ); // 0 ("0" 来自于 "0.000008")
parseInt( 0.0000008 ); // 8 ("8" 来自于 "8e-7") 注意:会先被转换
parseInt( false, 16 ); // 250 ("fa" 来自于 "false")
parseInt( parseInt, 16 ); // 15 ("f" 来自于 "function..")
parseInt( "0x10" ); // 16
parseInt( "103", 2 ); // 2
4.3.3 显式转换为布尔值
Boolean(..) 是显式的,但并不常用。
和前面讲过的 + 类似,一元运算符 ! 显式地将值强制类型转换为布尔值。
但是它同时还将真值反转为假值(或者将假值反转为真值)。
所以最常用的方法是 !! ,因为第二个 ! 会将结果反转回原值:
穿插一下: 转化成0/1的话,看4.3.3
还有!1
2var a = 42;
var b = a ? true : false;
三元运算符? :涉及隐式强制类型转换
所以: a 要首先被强制类型转换为布尔值才能进行条件判断。
这种情况称为“显式的隐式”,有百害而无一益,我们应彻底杜绝。
建议使用 Boolean(a) 和 !!a 来进行显式强制类型转换。
4.4 隐式强制类型转换
隐式强制类型转换指的是那些隐蔽的强制类型转换,副作用也不是很明显。
不赞同“因噎废食”的做法。
4.4.2 字符串和数字之间的隐式强制类型转换
- 运算符,通常的理解是,因为某一个或者两个操作数都是字符串,所以 + 执行的是字符串拼接操作。
这样解释只对了一半,实际情况要复杂得多。
数组使用+运算符1
2
3var a = [1,2];
var b = [3,4];
a + b; // "1,23,4"
第一步:都被强制转换为字符串
第二步:进行拼接
下面两段是ES5规范定义:
根据 ES5 规范 11.6.1 节,如果某个操作数是字符串或者能够通过以下步骤转换为字符串
的话, + 将进行拼接操作。如果其中一个操作数是对象(包括数组),则首先对其调用
ToPrimitive 抽象操作(规范 9.1 节),该抽象操作再调用 [[DefaultValue]] (规范 8.12.8
节),以数字作为上下文。
你或许注意到这与 ToNumber 抽象操作处理对象的方式一样(参见 4.2.2 节)。因为数组的valueOf() 操作无法得到简单基本类型值,于是它转而调用 toString() 。因此上例中的两
个数组变成了 “1,2” 和 “3,4” 。 + 将它们拼接后返回 “1,23,4” 。
简单总结:如果 + 的其中一个操作数是字符串(或者通过以上步骤可以得到字符串),则执行字符串拼接;否则执行数字加法。
坑:我们将在 5.1.3 节详细介绍。[] + {}和{} + [],它们返回不同的结果,分别是"[object Object]" 和 0 。
用法技巧:可以将数字和空字符串 “” 相 + 来将其转换为字符串:1
2
3var a = 42;
var b = a + "";
b; // "42"
注意:
a + “” (隐式)和前面的 String(a) (显式)之间有一个细微的差别需要注意。
根据ToPrimitive 抽象操作规则, a + “” 会对 a 调用 valueOf() 方法,然后通过 ToString 抽象操作将返回值转换为字符串。
而 String(a) 则是直接调用 ToString() 。
从字符串强制类型转换为数字:1
2
3var a = "3.14";
var b = a - 0;
b; // 3.14
- 是数字减法运算符,因此 a - 0 会将 a 强制类型转换为数字。
也可以使用a * 1和a /1,因为这两个运算符也只适用于数字,只不过这样的用法不太常见。
对象的 - 操作与 + 类似:1
2
3var a = [3];
var b = [1];
a - b; // 2
为了执行减法运算, a 和 b 都需要被转换为数字
第一步:首先被转换为字符串(通过toString() )。
第二步:再转换为数字
4.4.3 布尔值到数字的隐式强制类型转换
用+和Boolean()来转化
当判断大量true和false的&&关系时,就需要转化为0、1来处理,这样就比较明了了!
下边这个公式很有用!!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 如果其中有且仅有一个参数为 true ,则 onlyOne(..) 返回 true
function onlyOne() {
var sum = 0;
for (var i=0; i < arguments.length; i++) {
// 跳过假值,和处理0一样,但是避免了NaN
if (arguments[i]) { // 这步是过滤用的
sum += arguments[i]; // + 会强制将true转换为1
}
}
return sum == 1; // 这步是比较而非赋值
}
var a = true;
var b = false;
onlyOne( b, a ); // true
onlyOne( b, a, b, b, b ); // true
onlyOne( b, b ); // false
onlyOne( b, a, b, b, b, a ); // false
一样的效果:1
2
3
4
5
6
7function onlyOne() {
var sum = 0;
for (var i=0; i < arguments.length; i++) {
sum += Number( !!arguments[i] ); // 同时具备了功率功能
}
return sum === 1;
}
4.4.4 隐式强制类型转换为布尔值
下面的情况会发生布尔值隐式强制类型转换。
(1) if (..) 语句中的条件判断表达式。
(2) for ( .. ; .. ; .. ) 语句中的条件判断表达式(第二个)。
(3) while (..) 和 do..while(..) 循环中的条件判断表达式。
(4) ? : 中的条件判断表达式。
(5) 逻辑运算符 || (逻辑或)和 && (逻辑与)左边的操作数(作为条件判断表达式)。
以上情况中,非布尔值会被隐式强制类型转换为布尔值,遵循前面介绍过的 ToBoolean 抽象操作规则。
4.4.5 || 和 &&
|| (或)和 && (与)
称为“逻辑运算符”太准确。
称它们为“选择器运算符”或者“操作数选择器运算符”更恰当些。
和其他语言不同,在 JavaScript 中它们返回的并不是布尔值。
它们的返回值是两个操作数中的一个(且仅一个)。
例如:1
2
3
4
5
6
7
8var a = 42;
var b = "abc";
var c = null;
a || b; // 42 // 前边数
a && b; // "abc" // 后边数
c || b; // "abc"
c && b; // null c执行ToBoolean 得到false
b && c; // null 返回的是从后边数第一个为false的值
|| 和 && 首先会对第一个操作数( a 和 c )执行条件判断,如果其不是布尔值(如上例)就先进行 ToBoolean 强制类型转换,然后再执行条件判断。|| 来说,如果条件判断结果为 true 就返回第一个操作数( a 和 c )的值,如果为false 就返回第二个操作数( b )的值。&& 则相反,如果条件判断结果为 true 就返回第二个操作数( b )的值,如果为 false 就返回第一个操作数( a 和 c )的值。
换一种理解方法:1
2
3
4
5
6a || b;
// 大致相当于(roughly equivalent to):
a ? a : b;
a && b;
// 大致相当于(roughly equivalent to):
a ? b : a;
区别:在 a ? a : b 中,如果 a 是一个复杂一些的表达式(比如有副作用的函数调用等),它有可能被执行两次(如果第一次结果为真)。
而在 a || b 中 a 只执行一次
用途:
||:预设值1
2
3
4
5
6
7
8function foo(a,b) {
a = a || "hello";
b = b || "world";
console.log( a + " " + b );
}
foo(); // "hello world"
foo( "yeah", "yeah!" ); // "yeah yeah!"
foo( "That’s it!", "" ); // "That’s it! world" <-- 晕! 第二个参数 "" 是一个假值
&&:压缩工具常用:“守护运算符”即前面的表达式为后面的表达式把关
利用的短路机制!1
2
3
4
5function foo() {
console.log( a );
}
var a = 42;
a && foo(); // 42
这样的用法对开发人员不太常见,开发人员通常使用1
if (a) { foo(); }
但 JavaScript代码压缩工具用的是 a && foo() ,因为更简洁。
4.4.6 符号的强制类型转换
ES6 允许从符号到字符串的显式强制类型转换,然而隐式强制类型转换会产生错误1
2
3
4var s1 = Symbol( "cool" );
String( s1 ); // "Symbol(cool)" // 显示
var s2 = Symbol( "not cool" );
s2 + ""; // TypeError 隐式
符号不能够被强制类型转换为数字(显式和隐式都会产生错误),
但可以被强制类型转换为布尔值(显式和隐式结果都是 true )。
4.5 宽松相等和严格相等
正确的解释是:“ == 允许在相等比较中进行强制类型转换,而 === 不允许。
== 和 === 都会检查操作数的类型。区别在于操作数类型不同时它们的处理方式不同
4.5.1 相等比较操作的性能
有人觉得 == 会比 === 慢,实际上虽然强制类型转换确实要多花点时间,但仅仅是微秒级(百万分之一秒)的差别而已。
4.5.2 抽象相等
ES5 规范 11.9.3 节的“抽象相等比较算法”定义了 == 运算符的行为。
其中第一段(11.9.3.1)规定如果两个值的类型相同,就仅比较它们是否相等。
例如, 42 等于 42 , “abc” 等于 “abc” 。
非常规情况:
• NaN 不等于 NaN (参见第 2 章)。
• +0 等于 -0 (参见第 2 章)。
11.9.3.1 的最后定义了对象(包括函数和数组)的宽松相等 == 。
两个对象指向同一个值时即视为相等,不发生强制类型转换。
11.9.3 节中还规定, == 在比较两个不同类型的值时会发生隐式强制类型转换,会将其中之一或两者都转换为相同的类型后再进行比较。
宽松不相等(loose not-equality) != 就是 == 的相反值, !== 同理。
以下比较时的转化顺序是:布尔值 > 字符串 → 数字
4.5.2.1 字符串和数字之间的相等比较
★★★★★
ES5 规范 11.9.3.4-5 这样定义:
(1) 如果 Type(x) 是数字, Type(y) 是字符串,则返回 x == ToNumber(y)的结果。
(2) 如果 Type(x) 是字符串, Type(y) 是数字,则返回 ToNumber(x) == y的结果。
总结:将字符串一侧转换成数字进行比较!
4.5.2.2 其他类型和布尔类型之间的相等比较
== 最容易出错的一个地方是 true 和 false 与其他类型之间的相等比较。1
2
3var a = "42";
var b = true;
a == b; // false
我们都知道 “42” 是一个真值(见本章前面部分),为什么 == 的结果不是 true 呢?
★★★★★
规范 11.9.3.6-7 是这样说的:
(1) 如果 Type(x) 是布尔类型,则返回 ToNumber(x) == y 的结果;
(2) 如果 Type(y) 是布尔类型,则返回 x == ToNumber(y) 的结果。
总结:将布尔值转化为数字形式后,和数字进行比较!!
但是上边的例子会产生下边这种想法:1
2
3var a = "42";
var b = false;
a == b; // false
这样看 “42” 即不等于true,也不等于false,那么问题来了,怎么可能出现即不等于true,也不等于false呢???
因为大脑被骗了,因为最后比较的并不是”42” == false/true, 而是42 == 1/0 !!
重点是我们要搞清楚 == 对不同的类型组合怎样处理。
== 两边的布尔值会被强制类型转换为数字。
所以:建议无论什么情况下都不要使用 == true 和 == false 。
注意: === true 和 === false 不允许强制类型转换,因为不发生类型转换,所以没有关系可以用。1
2
3
4
5
6
7
8
9// 不要这样用,条件判断不成立:
if (a == true) {} // a 其实是和 1 比较呢
// 这样的显式用法没问题:
if (a) {}
// 这样的显式用法更好:
if (!!a) {}
// 这样的显式用法也很好:
if (Boolean( a )) {}
4.5.2.3 null 和 undefined 之间的相等比较
1 | var a = null; |
所以只有三种情况正确1
2
3null == undefined
null == null
undefined == undefined
条件判断 a == null 仅在 a 返回 null 和 undefined 时才成立,
除此之外其他值都不成立,包括 0 、 false 和 “” 这样的假值。
4.5.2.4 对象和非对象之间的相等比较
对象(对象 / 函数 / 数组)和标量基本类型(字符串 / 数字 / 布尔值)之间的相等比较
★★★★★
ES5 规范 11.9.3.8-9 做如下规定:
(1) 如果 Type(x) 是字符串或数字, Type(y) 是对象,则返回 x == ToPrimitive(y)的结果;
(2) 如果 Type(x) 是对象, Type(y) 是字符串或数字,则返回 ToPromitive(x) == y的结果。
结论:将对象ToPromitive(先valueOf,在toString),然后再比较
注意:不包括布尔值,因为前边提到过了,布尔值会被先转化为number
我们可以自定义 valueOf() 以便从复杂的数据结构返回一个简单值进行相等比较,这些特性会很有帮助。
1 | var a = 42; |
在第 3 章中,我们介绍过拆封,即“打开”封装对象(如 new String(“abc”) ),返回其中的基本数据类型值( “abc” )。
== 中的 ToPromitive 强制类型转换也会发生这样的情况:1
2
3
4var a = "abc";
var b = Object( a ); // 和new String( a )一样 一会儿会被解封为"abc"
a === b; // false 不进行类型转换
a == b; // true
特殊情况:1
2
3
4
5
6
7
8
9var a = null;
var b = Object( a ); // 和Object()一样
a == b; // false
var c = undefined;
var d = Object( c ); // 和Object()一样
c == d; // false
var e = NaN;
var f = Object( e ); // 和new Number( e )一样
e == f; // false
1.null 和 undefined因为没有对应的封装对象,所以不能够被封装,Object(null)和 Object()均返回一个常规对象。
2.NaN 能够被封装为数字封装对象,但拆封之后 NaN == NaN 返回 false ,因为 NaN 不等于 NaN
4.5.3 比较少见的情况
4.5.3.1 返回其他数字
第一种:修改了Number的原型方法1
2
3
4Number.prototype.valueOf = function() {
return 3;
};
new Number( 2 ) == 3; // true
第二种:每次执行都修改i的值1
2
3
4
5
6
7
8var i = 2;
Number.prototype.valueOf = function() {
return i++;
};
var a = new Number( 42 );
if (a == 2 && a == 3) { // 成为可能
console.log( "Yep, this happened." );
}
4.5.3.2. 假值的相等比较
一般不会自动转换为Boolean(除了用+和强制用Boolean())
下面分别列出了常规和非常规的情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24"0" == null; // false
"0" == undefined; // false
"0" == false; // true -- 晕!
"0" == NaN; // false
"0" == 0; // true
"0" == ""; // false
false == null; // false 看Boolean比较的规则 会转化成0 而0 == null 肯定是false
false == undefined; // false
false == NaN; // false
false == 0; // true -- 晕!
false == ""; // true -- 晕!
false == []; // true -- 晕!
false == {}; // false
"" == null; // false
"" == undefined; // false
"" == NaN; // false
"" == 0; // true -- 晕!
"" == []; // true -- 晕!
"" == {}; // false
0 == null; // false
0 == undefined; // false
0 == NaN; // false
0 == []; // true -- 晕!
0 == {}; // false
4.5.3.3 极端情况
更极端的例子:
例子一:1
[] == ![] // true
因为:
![] 会转化为false
所以式子现在是判断 [] == false
前边那个表 又有 false == [] // true
所以最后答案是true
例子二:1
22 == [2]; // true
"" == [null]; // true
上边的式子会进行ToNumber转换
最后结果就是比较
2 == 2 和 “” == “” 。
例子三:1
0 == "\n"; // true
"" 、 "\n" (或者 “ “ 等其他空格组合)等空字符串被 ToNumber 强制类型转换为 0
上边(晕)的 7 种情况基本涵盖了所有我们可能遇到的坑
与前面 24 种情况列表相对应的是下面这个列表:1
2
3
4
542 == "43"; // false
"foo" == 42; // false
"true" == true; // false
42 == "42"; // true
"foo" == [ "foo" ]; // true
4.5.3.4. 完整性检查
前面列举了相等比较中的强制类型转换的 7 个坑,不过另外还有至少 17 种情况是绝对安全和容易理解的。
再来看看那些“短”的地方:1
2
3
4
5
6
7"0" == false; // true -- 晕!
false == 0; // true -- 晕!
false == ""; // true -- 晕!
false == []; // true -- 晕!
"" == 0; // true -- 晕!
"" == []; // true -- 晕!
0 == []; // true -- 晕!
其中有 4 种情况涉及 == false ,之前我们说过应该避免,应该不难掌握。
现在剩下 3 种:1
2
3"" == 0; // true -- 晕!
"" == []; // true -- 晕!
0 == []; // true -- 晕!
我们应该不太可能会用 == [] 来做条件判断,而是用 == "" 或者 == 0 ,如:1
2
3
4
5function doSomething(a) {
if (a == "") {
// ..
}
}
如果不小心碰到 doSomething(0) 和 doSomething([]) 这样的情况,结果会让你大吃一惊。
所以一定要注意上边三个晕的比较值!!!
还是推荐用 4.5.2.2 中介绍的那几个
4.5.3.5 安全运用隐式强制类型转换
两个原则:★★★★★
• 如果两边的值中有 true 或者 false ,千万不要使用 == 。
• 如果两边的值中有 [] 、 “” 或者 0 ,尽量不要使用 == 。
这时最好用 === 来避免不经意的强制类型转换。
有一种情况下强制类型转换是绝对安全的,那就是 typeof 操作。
图:JavaScript 中的相等比较
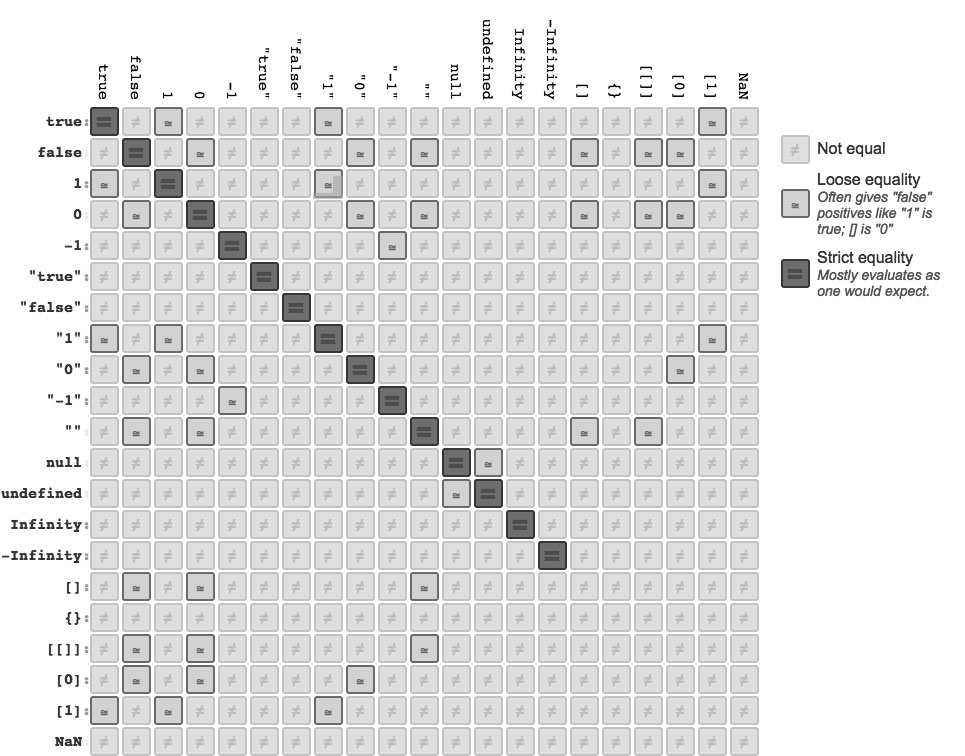
4.6 抽象关系比较
a < b 中涉及的隐式强制类型转换!!
比较双方首先调用 ToPrimitive ,如果结果出现非字符串,就根据 ToNumber 规则将双方强制类型转换为数字来进行比较。
1 | var a = [ 42 ]; |
如果比较双方都是字符串,则按字母顺序来进行比较:1
2
3var a = [ "42" ];
var b = [ "043" ];
a < b; // false
a 和 b 并没有被转换为数字,因为 ToPrimitive 返回的是字符串
对象比较1
2
3var a = { b: 42 };
var b = { b: 43 };
a < b; // false
因为 a 是 [object Object] , b 也是 [object Object] ,所以按照字母顺序a < b 并不成立。
下面就比较奇怪了1
2
3
4
5
6
7var a = { b: 42 };
var b = { b: 43 };
a < b; // false
a == b; // false
a > b; // false
a <= b; // true
a >= b; // true
因为根据规范 a <= b 被处理为 b < a ,然后将结果反转。
因为 b < a 的结果是 false ,所以 a <= b 的结果是 true 。
避免 a < b 中发生隐式强制类型转换,我们只能确保 a 和 b 为相同的类型,除此之外别无他法。
应该对关系比较中的值进行显式强制类型转换:1
2
3
4var a = [ 42 ];
var b = "043";
a < b; // false -- 字符串比较!
Number( a ) < Number( b ); // true -- 强制转换一下
5.语法
5.1 语句和表达式
“句子”(sentence)是完整表达某个意思的一组词,由一个或多个“短语”(phrase)组成,它们之间由标点符号或连接词and 和 or 等连接起来。
语句相当于句子,表达式相当于短语,运算符则相当于标点符号和连接词。
1 | var a = 3 * 6; |
第三行代码中只有一个表达式 b ,同时它也是一个语句(虽然没有太大意义)。
这样的情况通常叫作“表达式语句”(expression statement)。
5.1.1 语句的结果值
很多人不知道,语句都有一个结果值(statement completion value, undefined 也算)。
默认情况下控制台会显示所执行的最后一条语句的结果值。
但规范定义 var 的结果值是 undefined 。
原因:ES5规范12.2节中的变量声明( VariableDeclaration )算法实际上有一个返回值(是一个包含所声明变量名称的字符串,很奇特吧?),
但是这个值被变量语句( VariableStatement )算法屏蔽掉了( for..in 循环除外),最后返回结果为空( undefined )。
代码块 { .. } 的结果值是其最后一个语句 / 表达式的结果。1
2
3
4var b;
if (true) {
b = 4 + 38;
}
返回42
以下仅作演示1
2
3var a, b;
a = eval( "if (true) { b = 4 + 38; }" );
a; // 42
ES7 规范有一项do 表达式(do expression)提案,类似下面这样:1
2
3
4
5
6
7var a, b;
a = do {
if (true) {
b = 4 + 38;
}
};
a; // 42
上例中, do { .. } 表达式执行一个代码块(包含一个或多个语句),并且返回其中最后一个语句的结果值,然后赋值给变量 a 。
和上式eval()作用差不多,但是不要用eval而是用do
5.1.2 表达式的副作用
递增运算符 ++ 和递减运算符 – 都是一元运算符,它们既可以用在操作数的前面,也可以用在后面:1
2
3
4
5
6var a = 42;
a++; // 42
a; // 43
++a; // 44
a; // 44
可以使用 , 语句系列逗号运算符将多个独立的表达式语句串联成一个语句:1
2
3
4var a = 42, b;
b = ( a++, a );
a; // 43
b; // 43 这样b就是43了!!!
a++, a 中第二个表达式 a 在 a++ 之后执行,结果为 43 ,并被赋值给 b 。
delete 返回 true ,否则返回 false 。其副作用是属性被从对象中删除1
2
3
4
5
6var obj = {
a: 42
};
obj.a; // 42
delete obj.a; // true
obj.a; // undefined
另一个有趣的例子是 = 赋值运算符。1
2
3var a;
a = 42; // 42
a; // 42
a = 42 中的 = 运算符看起来没有副作用,实际上它的结果值是 42 ,它的副作用是将 42 赋值给 a 。
组合赋值运算符,如 += 和 -= 等也是如此。例如, a = b += 2 首先执行 b +=2 (即 b = b + 2 ),然后结果再被赋值给 a 。
1 | var a, b, c; |
如果变量 b 没有在作用域中象 var b 这样声明过,则 var a = b = 42 不会对变量 b 进行声明。
在严格模式中这样会产生错误,或者会无意中创建一个全局变量.
5.1.3 上下文规则
5.1.3.1 大括号
(1) 对象常量1
2
3
4// 假定函数bar()已经定义
var a = {
foo: bar()
};
(2) 标签1
2
3{
foo: bar()
}
很多开发人员以为这里的 { .. } 只是一个孤立的对象常量,没有赋值。事实上不是这样。
{ .. } 和 for / while 循环以及 if 条件语句中代码块的作用基本相同。
JavaScript 中一个不太为人知(也不建议使用)的特性,叫作标签语句
foo 是语句 bar() 的标签
JavaScript 通过标签跳转能够实现 goto 的部分功能。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 标签为foo的循环
foo: for (var i=0; i<4; i++) {
for (var j=0; j<4; j++) {
// 如果j和i相等,继续外层循环
if (j == i) {
// 跳转到foo的下一个循环
continue foo; // ★相当于goto功能
}
// 跳过奇数结果
if ((j * i) % 2 == 1) {
// 继续内层循环(没有标签的)
continue;
}
console.log( i, j );
}
}
// 1 0
// 2 0
// 2 1
// 3 0
// 3 2
contine foo 并不是指“跳转到标签 foo 所在位置继续执行”,而是“执行 foo 循环的下一轮循环”。所以这里的 foo 并非 goto 。
带标签的循环跳转一个更大的用处在于,和 break __ 一起使用可以实现从内层循环跳转到外层循环。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 标签为foo的循环
foo: for (var i=0; i<4; i++) {
for (var j=0; j<4; j++) {
if ((i * j) >= 3) {
console.log( "stopping!", i, j );
break foo; // 这里
}
console.log( i, j );
}
}
// 0 0
// 0 1
// 0 2
// 0 3
// 1 0
// 1 1
// 1 2
// 停止! 1 3
break foo 不是指“跳转到标签 foo 所在位置继续执行”,而是“跳出标签 foo 所在的循环 / 代码块,继续执行后面的代码”。
带标签的循环 / 代码块十分少见,也不建议使用。
JSON :
如果在控制台中输入 {“a”:42} 会报错。
因为标签不允许使用双引号,所以 “a” 并不是一个合法的标签,因此后面不能带 : 。
JSON 的确是 JavaScript 语法的一个子集,但是 JSON 本身并不是合法的 JavaScript 语法。
这里存在一个十分常见的误区,即如果通过 字符串,一旦出现即被视为代码块结束。
常用的变通方法是:1
"</sc" + "ript>";
另外需要注意的一点是,我们是根据代码文件的字符集属性(UTF-8、ISO-8859-8 等)来
解析外部文件中的代码(或者默认字符集),而内联代码则使用其所在页面文件的字符集(或者默认字符集)。
A.6 保留字
ES5 规范在 7.6.1 节中定义了一些“保留字”,我们不能将它们用作变量名。
这些保留字有四类:“关键字”“预留关键字”、 null 常量和 true / false 布尔常量。
1 | Let this long package float, |
这首诗中包含了 ES3 中的保留字( byte 、 long 等),它们在 ES5 中已经不再是保留字。
在 ES5 之前,保留字也不能用来作为对象常量中的属性名称或者键值,但是现在已经没有这个限制。
A.7 实现中的限制
javaScript 规范对于函数中参数的个数,以及字符串常量的长度等并没有限制;
但是不同浏览器不同,就会出现有些做了限制的现象
下面列出一些已知的限制:
• 字符串常量中允许的最大字符数(并非只是针对字符串值);
• 可以作为参数传递到函数中的数据大小(也称为栈大小,以字节为单位);
• 函数声明中的参数个数;
• 未经优化的调用栈(例如递归)的最大层数,即函数调用链的最大长度;
• JavaScript 程序以阻塞方式在浏览器中运行的最长时间(秒);
• 变量名的最大长度。
一般我们不会碰到这些限制。
1.异步:现在与将来
从现在到将来的等待,最简单的方法是使用回调函数:
ajax通过回调函数实现异步
setTime设置了一个事件在将来执行。
异步控制台
在开发者工具的控制台中输出的对象表示与期望有可能不一致的
浏览器可能会认为需要把控制台 I/O 延迟到后台
最好的选择是在 JavaScript 调试器中使用断点,而不要依赖控制台输出。
1.2 事件循环
什么是事件循环?
先通过一段伪代码了解一下这个概念 :(同时学到永远执行的方法while)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// eventLoop是一个用作队列的数组
// (先进,先出)
var eventLoop = [ ];
var event;
// “永远”执行
while (true) {
// 一次tick
if (eventLoop.length > 0) {
// 拿到队列中的下一个事件
event = eventLoop.shift();
// 现在,执行下一个事件
try {
event();
}
catch (err) {
reportError(err);
}
}
}
事件循环是一个紧接一个的(中间没有空闲,setTimeout可能会出现空闲)
setTimeout(..) 并没有把你的回调函数挂在事件循环队列中。它所做的是设定一个定时器。
大体说来,只能确保你的回调函数不会在指定的 时间间隔之前运行,但可能会在那个时刻运行,也可能在那之后运行,要根据事件队列的状态而定。
1.3 并行线程
异步是关于现在和将来的时间间隙,而并行是关于能够同时发生的事情。
并行计算最常见的工具就是进程和线程。
多线程编程是非常复杂的。
因为如果不通过特殊的步骤来防止这种中断和交错运行的话,可能会得到出乎意料的、不确定的行为,通常这很让人头疼。
由于 JavaScript 的单线程特性, foo() (以及 bar() )中的代码具有原子性。
也就是说,一旦 foo() 开始运行,它的所有代码(并不会将()内的程序拆开)都会在 bar() 中的任意代码运行之前完成,或者相反。
这称为完整运行特性。
函数顺序的不确定性就是通常所说的竞态条件, foo() 和 bar() 相互竞争,看谁先运行。
1.4 并发
可以把并发看作“进程”级(或者任务级)的并行,与运算级的并行(不同处理器上的线程)相对。
单线程事件循环是并发的一种形式。
例:滚动事件和ajax事件交替进行触发
1.4.1 非交互
如果进程间没有相互影响的话,不确定性是完全可以接受的。
ajax的回调函数如果不互相影响,先执行哪个回调都一样!
1.4.2 交互
通过 共享作用域+判断语句 来控制流程
条件判断if (a && b)传统上称为门
有时称为竞态(race),但是更精确的叫法是门闩(latch)
1.4.3 协作
1 | function response(data) { |
setTimeout(..0)进行异步调度,基本上它的意思就是把这个函数插入到当前事件循环队列的结尾处。
严格说来,setTimeout(..0) 并不直接把项目插入到事件循环队列。定时器会在有机会的时候插入事件。
举例来说,两个连续的 setTimeout(..0) 调用不能保证会严格按照调用顺序处理,所以各种情况都有可能出现,比如定时器漂移,在这种情况下,这些事件的顺序就不可预测。
在 Node.js 中,类似的方法是 process.nextTick(..)。
尽管它们使用方便(通常性能也更高),但并没有(至少到目前为止)直接的方法可以适应所有环境来确保异步事件的顺序。
1.5 任务
事件循环队列类似于一个游乐园游戏:玩过了一个游戏之后,你需要重新到队尾排队才能再玩一次。
而任务队列类似于玩过了游戏之后,插队接着继续玩。
任务和 setTimeout(..0) hack 的思路类似,但是其实现方式的定义更加良好,对顺序的保证性更强:尽可能早的将来。1
2
3
4
5
6
7// 理论上的"任务API"
schedule( function(){
console.log( "C" );
schedule( function(){
console.log( "D" );
} );
} );
1.6 语句顺序
JavaScript 是需要编译的1
2
3
4
5
6var a, b;
a = 10;
b = 30;
a = a + 1;
b = b + 1;
console.log( a + b ); // 42
JavaScript 引擎在编译之后,可能会发现通过(安全地)重新安排这些语句的顺序有可能提高执行速度。1
2
3
4
5
6var a, b;
a = 10;
a++;
b = 30;
b++;
console.log( a + b ); // 42
JavaScript 引擎在编译期间执行的都是安全的优化,最后可见的结果都是一样的。
编译器语句重排序几乎就是并发和交互的微型隐喻。
1.7 小结
一旦有事件需要运行,事件循环就会运行,直到队列清空。
事件循环的每一轮称为一个tick。用户交互、IO 和定时器会向事件队列中加入事件。
并发是指两个或多个事件链随时间发展交替执行,以至于从更高的层次来看,就像是同时在运行(尽管在任意时刻只处理一个事件)。
通常需要对这些并发执行的“进程”(有别于操作系统中的进程概念)进行某种形式的交互协调,
比如需要确保执行顺序或者需要防止竞态出现。这些“进程”也可以通过把自身分割为更小的块,以便其他“进程”插入进来。
2.回调
无数 JavaScript 程序,甚至包括一些最为高深和复杂的,所依赖的异步基础也仅限于回调(当然,它们使用了各种并发交互模式)。
很多开发者因为更好的异步模式 promise 而激动不已。
2.1 continuation
比较下边两组代码1
2
3
4
5
6
7
8
9
10
11
12
13// 第一组
// A
ajax( "..", function(..){
// C
} );
// B
// 第二组
// A
setTimeout( function(){
// C
}, 1000 );
// B
两组代码其实可以理解为是一样的。
但是又有细微的差别!
换句话说,回调函数包裹或者说封装了程序的延续(continuation)
2.2 顺序的大脑
大脑几乎是不停地切换到不同的上下文(即“进程”)中。
2.2.1 执行与计划
2.2.2 嵌套回调与链式回调
函数嵌套在一起构成的链,这种代码常常被称为回调地狱,有时也被称为毁灭金字塔
函数嵌套执行顺序按照 1、2、3、4……的顺序,这只是一个偶然。1
2
3
4
5
6
7
8doA( function(){
doB();
doC( function(){
doD();
} )
doE();
} );
doF();
实际运行顺序是这样的:
• doA()
• doF() // doA内的回调是将来执行,所以就先执行了doF
• doB()
• doC()
• doE()
• doD()
2.3 信任问题
我们把这称为控制反转,也就是把自己程序一部分的执行控制交给某个第三方。
2.3.1 五个回调的故事
调用你的回调时所有可能的出错情况:
• 调用回调过早(在追踪之前);
• 调用回调过晚(或没有调用);
• 调用回调的次数太少或太多(就像你遇到过的问题!);
• 没有把所需的环境 / 参数成功传给你的回调函数;
• 吞掉可能出现的错误或异常;
• ……
2.3.2 不只是别人的代码
针对不信任输入的防御性代码:1
2
3
4
5
6
7
8
9function addNumbers(x,y) {
// 确保输入为数字
x = Number( x ); // 这里做了信任输入
y = Number( y ); // 这里做了信任输入
// +安全进行数字相加
return x + y;
}
addNumbers( 21, 21 ); // 42
addNumbers( 21, "21" ); // 42
2.4 省点回调
试图从回调模式内部挽救它的意图是勇敢的,但却注定要失败。
例如,为了更优雅地处理错误,有些 API 设计提供了分离回调(一个用于成功通知,一个用于出错通知):1
ajax( "http://some.url.1", success, failure );
ES6 Promise API 使用的就是这种分离回调设计。
还有一种常见的回调模式叫作“error-first 风格”,
有时候也称为“Node 风格”,因为几乎所有 Node.js API 都采用这种风格
其中回调的第一个参数保留用作错误对象.
如果成功的话,这个参数就会被清空 / 置假(后续的参数就是成功数据)。
如果产生了错误结果,那么第一个参数就会被置起 / 置真(通常就不会再传递其他结果)1
2
3
4
5
6
7
8
9
10
11function response(err,data) {
// 出错?
if (err) {
console.error( err );
}
// 否则认为成功
else {
console.log( data );
}
}
ajax( "http://some.url.1", response );
缺点:
这并没有真正解决主要的信任问题!!
反而更糟了:
因为现在你可能同时得到成功或者失败的结果,或者都没有,并且你还是不得不编码处理所有这些情况。
第一个问题-不调用函数的解决方法:设置一个超时来取消事件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function timeoutify(fn,delay) {
var intv = setTimeout( function(){
intv = null;
fn( new Error( "Timeout!" ) );
}, delay )
;
return function() {
// 还没有超时?
if (intv) {
clearTimeout( intv );
fn.apply( this, arguments );
}
};
}
// 用法
ajax( "http://some.url.1", timeoutify( foo, 500 ) );
第二个问题-调用过早解决办法:创建“验证概念”版本的 asyncify(..) 工具(保证异步执行通过定时器):
永远异步调用回调,这样,所有回调就都是可预测的异步调用了。(永远要异步)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33function asyncify(fn) {
var orig_fn = fn,
intv = setTimeout( function(){
intv = null;
if (fn) fn();
}, 0 )
;
fn = null;
return function() {
// 触发太快,在定时器intv触发指示异步转换发生之前?
if (intv) {
fn = orig_fn.bind.apply(
orig_fn,
// 把封装器的this添加到bind(..)调用的参数中,
// 以及克里化(currying)所有传入参数
[this].concat( [].slice.call( arguments ) )
);
}
// 已经是异步
else {
// 调用原来的函数
orig_fn.apply( this, arguments );
}
};
}
// 使用方法
function result(data) {
console.log( a );
}
var a = 0;
ajax( "..pre-cached-url..", asyncify( result ) );
a++;
这段代码总是会输出 1 ,而不是 0 —— result(..) 只能异步调用,这意味着 a++ 有机会在 result(..) 之前运行。
2.5 小结
回调函数是 JavaScript 异步的基本单元。
3.Promise
回调表达程序异步和管理并发的两个主要缺陷:缺乏顺序性和可信任性。
如果我们不把自己程序的continuation 传给第三方,而是希望第三方给我们提供了解其任务何时结束的能力,然后由我们自己的代码来决定下一步做什么,这种范式就称为 Promise。
思考:
第三方自己那里,可以设置多次调用callback
而Promise则是告诉我们结束了的标志,不会再控制到本地的代码
3.1 什么是 Promise
3.1.1 未来值
未来值的一个重要特性:它可能成功,也可能失败。
例子:买汉堡交钱给我订单号,订单号相当于占位符,叫我号的时候,可能卖没了,也可能还有!
还有可能出现:永远没有被叫到的情况
就像芝士汉堡订单一样,Promise 的决议结果可能是拒绝而不是完成。
拒绝值和完成的 Promise 不一样:完成值总是编程给出的,而拒绝值,通常称为拒绝原因(rejectionreason),可能是程序逻辑直接设置的,也可能是从运行异常隐式得出的值。
Promise 决议后就是外部不可变的值,我们可以安全地把这个值传递给第三方,并确信它不会被有意无意地修改。
3.1.2 完成事件
假定要调用一个函数 foo(..) 执行某个任务。我们不知道也不关心它的任何细节。这个函数可能立即完成任务,也可能需要一段时间才能完成。
我们只需要知道 foo(..) 什么时候结束,这样就可以进行下一个任务。
换句话说,我们想要通过某种方式在 foo(..) 完成的时候得到通知,以便可以继续下一步。
以下伪代码实现了关注点分离1
2
3
4
5
6
7
8
9
10
11
12function foo(x) {
// 开始做点可能耗时的工作
// 构造一个listener 事件通知处理对象 来返回
return listener;
}
var evt = foo( 42 );
evt.on( "completion", function(){
// 可以进行下一步了!
} );
evt.on( "failure", function(err){
// 啊,foo(..)中出错了
} );
我们调用 foo(..) ,然后建立了两个事件侦听器,一个用于 “ completion” ,一个用于” error” —— foo(..) 调用的两种可能结果。
从本质上讲, foo(..) 并不需要了解调用代码订阅了这些事件,这样就很好地实现了关注点分离。
如果你回想一下第 2 章的话,应该还记得回调本身就表达了一种控制反转。
所以对回调模式的反转实际上是对反转的反转,或者称为反控制反转
关注点分离的好处: bar(..) 和 baz(..) 不需要牵扯到foo(..) 的调用细节。
表现为:
①foo(..) 不需要知道或关注 bar(..) 和 baz(..) 是否存在,
②是否在等待 foo(..) 的完成通知。
从本质上说, evt 对象就是分离的关注点之间一个中立的第三方协商机制。
Promise“事件”
事件侦听对象 evt 就是 Promise 的一个模拟
1 | function foo(x) { |
new Promise( function(..){ .. } ) 模式通常称为 revealing constructor。
传入的函数会立即执行(不会像 then(..) 中的回调一样异步延迟),
它有两个参数,在本例中我们将其分别称为 resolve 和 reject。
这些是 promise 的决议函数。
resolve(..) 通常标识完成,而 reject(..) 则标识拒绝。
3.2 具有 then 方法的鸭子类型
如何确定某个值是不是真正的 Promise?
不可行方法:
1.通过 p instanceof Promise 来检查
原因:
1.最主要的是,Promise 值可能是从其他浏览器窗口(iframe 等)接收到的。这个浏览器窗口自己的 Promise 可能和当前窗口 /frame 的不同,因此这样的检查无法识别 Promise实例。
2.有可能你是在早期根本没有 Promise 实现的浏览器中使用由库提供的 Promise
识别 Promise 就是定义某种称为 thenable 的东西,将其定义为任何具有 then(..) 方法的对象和函数。
对 thenable 值的鸭子类型检测就大致类似于:1
2
3
4
5
6
7
8
9
10
11
12
13if (
p !== null &&
(
typeof p === "object" ||
typeof p === "function"
) &&
typeof p.then === "function"
) {
// 假定这是一个thenable!
}
else {
// 不是thenable
}
缺陷:如果你使用的函数恰好有 then(..) 的方法就比较麻烦了!
3.3 Promise 信任问题
先回顾一下只用回调编码的信任问题。
• 调用回调过早;
• 调用回调过晚(或不被调用);
• 调用回调次数过少或过多;
• 未能传递所需的环境和参数;
• 吞掉可能出现的错误和异常。
3.3.1 调用过早
问题:一个任务有时同步完成,有时异步完成,这可能会导致竞态条件。
Promise 就不必担心这种问题,因为即使是立即完成的 Promise 也无法被同步观察到。
3.3.2 调用过晚
Promise 创建对象调用 resolve(..) 或 reject(..) 时,这个 Promise 的 then(..) 注册的观察回调就会被自动调度。
可以确信,这些被调度的回调在下一个异步事件点上一定会被触发。
一个 Promise 决议后,这个 Promise 上所有的通过 then(..) 注册的回调都会在下一个异步时机点上依次被立即调用
永远都不应该依赖于不同 Promise 间回调的顺序和调度。
3.3.3 回调未调用
如果 Promise 本身永远不被决议呢?
即使这样,Promise 也提供了解决方案,其使用了一种称为竞态的高级抽象机制:Promise.race()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 用于超时一个Promise的工具
function timeoutPromise(delay) {
return new Promise( function(resolve,reject){
setTimeout( function(){
reject( "Timeout!" );
}, delay );
} );
}
// 设置foo()超时
Promise.race( [
foo(), // 试着开始foo()
timeoutPromise( 3000 ) // 给它3秒钟
] )
.then(
function(){
// foo(..)及时完成!
},
function(err){
// 或者foo()被拒绝,或者只是没能按时完成
// 查看err来了解是哪种情况
}
);
很重要的一点是,我们可以保证一个 foo() 有一个输出信号,防止其永久挂住程序。
3.3.4 调用次数过少或过多
“过多”的情况很容易解释。Promise 的定义方式使得它只能被决议一次。
如果出于某种原因,Promise 创建代码试图调用 resolve(..) 或 reject(..) 多次,或者试图两者都调用,
那么这个 Promise 将只会接受第一次决议,并默默地忽略任何后续调用。
3.3.5 未能传递参数 / 环境值
Promise 至多只能有一个决议值(完成或拒绝)。
如果使用多个参数调用 resovle(..) 或者 reject(..) ,第一个参数之后的所有参数都会被默默忽略。
如果要传递多个值,可以通过一个数组或对象。
3.3.6 吞掉错误或异常
如果在 Promise 的创建过程中或在查看其决议结果过程中的任何时间点上出现了一个 JavaScript 异常错误,
比如一个 TypeError 或 ReferenceError ,那这个异常就会被捕捉,并且会使这个 Promise 被拒绝。
Promise 甚至把 JavaScript 异常也变成了异步行为,进而极大降低了竞态条件出现的可能。
如果 Promise 完成后在查看结果时( then(..) 注册的回调中)出现了 JavaScript 异常错误会怎样呢?1
2
3
4
5
6
7
8
9
10
11
12var p = new Promise( function(resolve,reject){
resolve( 42 );
} );
p.then(
function fulfilled(msg){
foo.bar();
console.log( msg ); // 永远不会到达这里 :(
},
function rejected(err){
// 永远也不会到达这里 :(
}
);
foo.bar() 产生的异常真的被吞掉了,实际上并不是这样。
p.then(..) 调用本身返回了另外一个 promise,正是这个 promise 将会因 TypeError 异常而被拒绝。
3.3.7 是可信任的 Promise 吗
它们只是改变了传递回调的位置。
我们并不是把回调传递给 foo(..) ,而是从 foo(..) 得到某个东西(外观上看是一个真正的Promise),然后把回调传给这个东西。
向 Promise.resolve(..) 传递一个非 Promise、非 thenable 的立即值,就会得到一个用这个值填充的 promise。
下面这种情况下,promise p1 和 promise p2 的行为是完全一样的:1
2
3
4var p1 = new Promise( function(resolve,reject){
resolve( 42 );
} );
var p2 = Promise.resolve( 42 );
而如果向 Promise.resolve(..) 传递一个真正的 Promise,就只会返回同一个 promise:1
2
3var p1 = Promise.resolve( 42 );
var p2 = Promise.resolve( p1 );
p1 === p2; // true
更重要的是,如果向 Promise.resolve(..) 传递了一个非 Promise 的 thenable 值,前者就会试图展开这个值,而且展开过程会持续到提取出一个具体的非类 Promise 的最终值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var p = {
then: function(cb,errcb) {
cb( 42 );
errcb( "evil laugh" );
}
};
p
.then(
function fulfilled(val){
console.log( val ); // 42
},
function rejected(err){
// 啊,不应该运行!
console.log( err ); // evil laugh
}
);
这个 p 是一个 thenable,但是其行为和 promise 并不完全一致。是不可信任的。
我们可以把这些版本的 p 传给 Promise.resolve(..) ,然后就会得到期望中的规范化后的安全结果:1
2
3
4
5
6
7
8
9Promise.resolve( p )
.then(
function fulfilled(val){
console.log( val ); // 42
},
function rejected(err){
// 永远不会到达这里
}
);
Promise.resolve(..) 可以接受任何 thenable,将其解封为它的非 thenable 值。从 Promise.
resolve(..) 得到的是一个真正的 Promise,是一个可以信任的值。
假设我们要调用一个工具 foo(..) ,且并不确定得到的返回值是否是一个可信任的行为良
好的 Promise,但我们可以知道它至少是一个 thenable。
Promise.resolve(..) 提供了可信任的 Promise 封装工具,可以链接使用:1
2
3
4
5
6
7
8
9
10// 不要只是这么做:
foo( 42 )
.then( function(v){
console.log( v );
} );
// 而要这么做:
Promise.resolve( foo( 42 ) )
.then( function(v){
console.log( v );
} );
3.3.8 建立信任
Promise 这种模式通过可信任的语义把回调作为参数传递,使得这种行为更可靠更合理。
通过把回调的控制反转反转回来,我们把控制权放在了一个可信任的系统(Promise)中,
这种系统的设计目的就是为了使异步编码更清晰。
3.4 链式流
链式流可以实现的关键在于以下两个 Promise 固有行为特性:
• 每次你对 Promise 调用 then(..) ,它都会创建并返回一个新的 Promise,我们可以将其
链接起来;
• 不管从 then(..) 调用的完成回调(第一个参数)返回的值是什么,它都会被自动设置
为被链接 Promise(第一点中的)的完成。
伪代码1
2
3
4
5
6
7
8
9
10var p = Promise.resolve( 21 );
var p2 = p.then( function(v){
console.log( v ); // 21
// 用值42填充p2
return v * 2;
} );
// 连接p2
p2.then( function(v){
console.log( v ); // 42
} );
链式伪代码:1
2
3
4
5
6
7
8
9
10
11var p = Promise.resolve( 21 );
p
.then( function(v){
console.log( v ); // 21
// 用值42完成连接的promise
return v * 2;
} )
// 这里是链接的promise
.then( function(v){
console.log( v ); // 42
} );
我们使用了立即返回 return 语句,这会立即完成链接的 promise。
1 | var p = Promise.resolve( 21 ); |
在这些例子中,一步步传递的值是可选的。如果不显式返回一个值,就会隐式返回undefined ,并且这些 promise 仍然会以同样的方式链接在一起。
错误问题:
错误和异常是基于每个 Promise 的,这意味着可能在链的任意位置捕捉到这样的错误,而这个捕捉动作在某种程度上就相当于在这一位置将整条链“重置”回了正常运作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// 步骤1:
request( "http://some.url.1/" )
// 步骤2:
.then( function(response1){
foo.bar(); // undefined,出错!
// 永远不会到达这里
return request( "http://some.url.2/?v=" + response1 );
} )
// 步骤3:
.then(
function fulfilled(response2){
// 永远不会到达这里
},
// 捕捉错误的拒绝处理函数
function rejected(err){ // 第三步也可以捕获到错误,有返回值的话,下一步可以接收到这个返回值
console.log( err );
// 来自foo.bar()的错误TypeError
return 42;
}
)
// 步骤4:
.then( function(msg){
console.log( msg ); // 42 接收到了第三部错误的返回值
} );
注意:步骤4可以接收到步骤3中错误的返回值
在第 3 步返回的不是 42 而是一个 promise 的话,这个 promise 可能会延迟第 4 步。
调用 then(..) 时的完成处理函数或拒绝处理函数如果抛出异常,都会导致(链中的)下一个 promise 因这个异常而立即被拒绝。
让我们来简单总结一下使链式流程控制可行的 Promise 固有特性。
• 调用 Promise 的 then(..) 会自动创建一个新的 Promise 从调用返回。
• 在完成或拒绝处理函数内部,如果返回一个值或抛出一个异常,新返回的(可链接的)Promise 就相应地决议。
• 如果完成或拒绝处理函数返回一个 Promise,它将会被展开,这样一来,不管它的决议值是什么,都会成为当前 then(..) 返回的链接 Promise 的决议值。
术语:决议、完成以及拒绝
resolve表达结果可能是完成也可能是拒绝的话
下例会出现拒绝1
2
3
4
5
6var rejectedTh = {
then: function(resolved,rejected) {
rejected( "Oops" );
}
};
var rejectedPr = Promise.resolve( rejectedTh ); // 展开rejectedTh
所以 Promise.resolve(..) 是一个精确的好名字,因为它实际上的结果可能是完成或拒绝。
reject(..) 不会像 resolve(..) 一样进行展开。
如 果 向reject(..) 传入一个 Promise/thenable 值,它会把这个值原封不动地设置为拒绝理由。
3.5 错误处理
错误处理最自然的形式就是同步的 try..catch 结构。
遗憾的是,它只能是同步的,无法用于异步代码模式:
error-first 回调风格:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function foo(cb) {
setTimeout( function(){
try {
var x = baz.bar(); // 不能为异步
cb( null, x ); // 成功!
}
catch (err) {
cb( err );
}
}, 100 );
}
foo( function(err,val){
if (err) {
console.error( err ); // 烦 :(
}
else {
console.log( val );
}
} );
Promise 没有采用流行的 error-first 回调设计风格,而是使用了分离回调(split-callback)风格。
一个回调用于完成情况,一个回调用于拒绝情况:1
2
3
4
5
6
7
8
9var p = Promise.reject( "Oops" );
p.then(
function fulfilled(){
// 永远不会到达这里
},
function rejected(err){
console.log( err ); // "Oops"
}
);
1 | var p = Promise.resolve( 42 ); |
这里是一些错误使用导致 Promise 构造失败的例子:newPromise(null)、Promise.all()、Promise.race(42),等等。
结果会得到一个立即抛出的异常,而不是一个被拒绝的 Promise。
3.5.1 绝望的陷阱
Promise 错误处理就是一个“绝望的陷阱”设计。
为了避免丢失被忽略和抛弃的 Promise 错误,一些开发者表示,Promise 链的一个最佳实践就是最后总以一个 catch(..) 结束,比如:1
2
3
4
5
6
7
8var p = Promise.resolve( 42 );
p.then(
function fulfilled(msg){
// 数字没有string函数,所以会抛出错误
console.log( msg.toLowerCase() );
}
)
.catch( handleErrors );
因此,进入 p 的错误以及 p 之后进入其决议(就像 msg.toLowerCase() )的错误都会传递到最后的 handleErrors(..) 。
3.5.2 处理未捕获的情况
在这个链尾端添加一个新的 catch(..) ,它很可能会失败!!
更常见的一种看法是:Promsie 应该添加一个 done(..) 函数,从本质上标识 Promsie 链的
结束。 done(..) 不会创建和返回 Promise,所以传递给 done(..) 的回调显然不会报告一个
并不存在的链接 Promise 的问题。
它的处理方式类似于你可能对未捕获错误通常期望的处理方式:
done(..) 拒绝处理函数内部的任何异常都会被作为一个全局未处理错误抛出(基本上是在
开发者终端上)。代码如下:1
2
3
4
5
6
7
8
9var p = Promise.resolve( 42 );
p.then(
function fulfilled(msg){
// 数字没有string函数,所以会抛出错误
console.log( msg.toLowerCase() );
}
)
.done( null, handleErrors );
// 如果handleErrors(..)引发了自身的异常,会被全局抛出到这里
done()并不是 ES6 标准的一部分
浏览器有一个特有的功能是我们的代码所没有的:它们可以跟踪并了解所有对象被丢弃以及被垃圾回收的时机。
所以,浏览器可以追踪 Promise 对象。如果在它被垃圾回收的时候其中有拒绝,浏览器就能够确保这是一个真正的未捕获错误,进而可以确定应该将其报告到开发者终端。
但是,如果一个 Promise 未被垃圾回收——各种不同的代码模式中很容易不小心出现这种情况——浏览器的垃圾回收嗅探就无法帮助你知晓和诊断一个被你默默拒绝的 Promise。
还有其他办法吗?有。
3.5.3 成功的坑
• 默认情况下,Promsie 在下一个任务或时间循环 tick 上(向开发者终端)报告所有拒绝,
如果在这个时间点上该 Promise 上还没有注册错误处理函数。
• 如果想要一个被拒绝的 Promise 在查看之前的某个时间段内保持被拒绝状态,可以调用
defer() ,这个函数优先级高于该 Promise 的自动错误报告。
如果一个 Promise 被拒绝的话,默认情况下会向开发者终端报告这个事实(而不是默认为沉默)。
可以选择隐式(在拒绝之前注册一个错误处理函数)或者显式(通过 defer() )禁止这种报告。
在这两种情况下,都是由你来控制误报的情况。1
2
3
4
5
6
7
8
9
10
11
12var p = Promise.reject( "Oops" ).defer();
// foo(..)是支持Promise的
foo( 42 )
.then(
function fulfilled(){
return p;
},
function rejected(err){
// 处理foo(..)错误
}
);
//...
创建 p 的时候,我们知道需要等待一段时间才能使用或查看它的拒绝结果,所以我们就调用 defer() ,这样就不会有全局报告出现。
为了便于链接, defer() 只是返回这同一个promise。
从 foo(..) 返回的 promise 立刻就被关联了一个错误处理函数,所以它也隐式消除了出错全局报告。
但是,从 then(..) 调用返回的 promise 没有调用 defer() ,也没有关联错误处理函数,所
以如果它(从内部或决议处理函数)拒绝的话,就会作为一个未捕获错误被报告到开发者终端。
这种设计就是成功的坑。
默认情况下,所有的错误要么被处理要么被报告,这几乎是绝大多数情况下几乎所有开发者会期望的结果。
你要么必须注册一个处理函数要么特意选择退出,并表明你想把错误处理延迟到将来。你这时候是在为特殊情况主动承担特殊的责任。
这种方案唯一真正的危险是,如果你 defer() 了一个 Promise,但之后却没有成功查看或处理它的拒绝结果。
但是,你得特意调用 defer() 才能选择进入这个绝望的陷阱(默认情况下总是成功的坑)。
3.6 Promise 模式
3.6.1 Promise.all([ .. ])
如果想要同时执行两个或更多步骤,要怎么实现呢?
在经典的编程术语中,门(gate)是这样一种机制要等待两个或更多并行 / 并发的任务都完成才能继续。
它们的完成顺序并不重要,但是必须都要完成,门才能打开并让流程控制继续。
1 | // request(..)是一个Promise-aware Ajax工具 |
Promise.all([ .. ]) 需要一个参数,是一个数组,通常由 Promise 实例组成。
从 Promise.all([ .. ]) 调用返回的 promise 会收到一个完成消息(代码片段中的 msg )。
这是一个由所有传入 promise 的完成消息组成的数组,与指定的顺序一致(与完成顺序无关)。
严格说来,传给 Promise.all([ .. ]) 的数组中的值可以是 Promise、thenable,甚至是立即值。
就本质而言,列表中的每个值都会通过 Promise.resolve(..) 过滤,以确保要等待的是一个真正的 Promise,所以立即值会被规范化为为这个值构建的 Promise。
如果数组是空的,主 Promise 就会立即完成。
Promise.all([ .. ]) 所有的成员 如果这些 promise 中有任何一个被拒绝的话,主 Promise.all([ .. ]) promise 就会立即被拒绝,并丢弃来自其他所有 promise 的全部结果。
3.6.2 Promise.race([ .. ])
只响应“第一个跨过终点线的 Promise”,而抛弃其他 Promise。
这种模式传统上称为门闩,但在 Promise 中称为竞态。
Promise.race([ .. ]) 也接受单个数组参数。这个数组由一个或多个 Promise、thenable 或立即值组成。
立即值之间的竞争在实践中没有太大意义,因为显然列表中的第一个会获胜,就像赛跑中有一个选手是从终点开始比赛一样!
一旦有任何一个 Promise 决议为完成, Promise.race([ .. ])就会完成;一旦有任何一个 Promise 决议为拒绝,它就会拒绝。
如果你传入了一个空数组,主race([..]) Promise 永远不会决议,而不是立即决议。
永远不要递送空数组。
3.6.2.1. 超时竞赛
1 | // foo()是一个支持Promise的函数 |
3.6.2.2. finally
一个关键问题是:“那些被丢弃或忽略的 promise 会发生什么呢?”
通常最终它们会被垃圾回收。
Promise 不能被取消,也不应该被取消,因为那会摧毁 3.8.5 节讨论的外部不变性原则,所以它们只能被默默忽略。
有什么为超时后主动释放这些保留资源提供任何支持?
或者取消任何可能产生的副作用吗?
如果你想要的只是记录下 foo() 超时这个事实,又会如何呢?
有些开发者提出,Promise 需要一个 finally(..) 回调注册,这个回调在 Promise 决议后总是会被调用,并且允许你执行任何必要的清理工作。
目前,规范还没有支持这一点,不过在 ES7+ 中也许可以。只好等等看了。
模型:1
2
3
4
5var p = Promise.resolve( 42 );
p.then( something )
.finally( cleanup )
.then( another )
.finally( cleanup );
我们可以构建一个静态辅助工具来支持查看(而不影响)Promise 的决议:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// polyfill安全的guard检查
if (!Promise.observe) {
Promise.observe = function(pr,cb) {
// 观察pr的决议
pr.then(
function fulfilled (msg){
// 安排异步回调(作为Job)
Promise.resolve( msg ).then( cb );
},
function rejected(err){
// 安排异步回调(作为Job)
Promise.resolve( err ).then( cb );
}
);
// 返回最初的promise
return pr;
};
}
下面是如何在前面的超时例子中使用这个工具:1
2
3
4
5
6
7
8
9Promise.race( [
Promise.observe(
foo(), // 试着运行foo()
function cleanup(msg){
// 在foo()之后清理,即使它没有在超时之前完成
}
),
timeoutPromise( 3000 ) // 给它3秒钟
] )
这个辅助工具 Promise.observe(..) 只是用来展示 Promise 的完成而不对其产生影响
3.6.3 all([ .. ]) 和 race([ .. ]) 的变体
• none([ .. ])
这个模式类似于 all([ .. ]) ,不过完成和拒绝的情况互换了。
所有的 Promise 都要被拒绝,即拒绝转化为完成值,反之亦然。
• any([ .. ])
这个模式与 all([ .. ]) 类似,但是会忽略拒绝,所以只需要完成一个而不是全部。
• first([ .. ])
这个模式类似于与 any([ .. ]) 的竞争,即只要第一个 Promise 完成,它就会忽略后续的任何拒绝和完成。
• last([ .. ])
这个模式类似于 first([ .. ]) ,但却是只有最后一个完成胜出。
自己来实现它们:
定义 first([ .. ]) :1
2
3
4
5
6
7
8
9
10
11
12
13
14// polyfill安全的guard检查
if (!Promise.first) {
Promise.first = function(prs) {
return new Promise( function(resolve,reject){
// 在所有promise上循环
prs.forEach( function(pr){
// 把值规整化
Promise.resolve( pr )
// 不管哪个最先完成,就决议主promise
.then( resolve );
} );
} );
};
}
3.6.4 并发迭代
如果要对每个 Promise 执行的任务本身是同步的,那这些工具就可以工作,就像前面代码中的forEach(..) 。
上例中每个pr都是同步的
但如果这些任务从根本上是异步的,或者可以 / 应该并发执行,那你可以使用这些工具的异步版本
下例中的cb是回调函数,是异步的!!
举例来说,让我们考虑一下一个异步的 map(..) 工具。它接收一个数组的值(可以是
Promise 或其他任何值),外加要在每个值上运行一个函数(任务)作为参数。
map(..) 本身返回一个 promise,其完成值是一个数组,该数组(保持映射顺序)保存任务执行之后的异步完成值:1
2
3
4
5
6
7
8
9
10
11
12
13
14if (!Promise.map) {
Promise.map = function(vals,cb) {
// 一个等待所有map的promise的新promise
return Promise.all(
// 注:一般数组map(..)把值数组转换为 promise数组
vals.map( function(val){
// 用val异步map之后决议的新promise替换val
return new Promise( function(resolve){
cb( val, resolve );
} );
} )
);
};
}
在这个 map(..) 实现中,不能发送异步拒绝信号,但如果在映射的回调(cb(..))内出现同步的异常或错误,主 Promise.map(..) 返回的 promise就会拒绝。
下面展示如何在一组 Promise(而非简单的值)上使用 map(..) :
1 | var p1 = Promise.resolve( 21 ); |
3.7 Promise API 概述
3.7.1 new Promise(..) 构造器
构造器 Promise(..) 必须和 new 一起使用,并且必须提供一个函数回调。
这个回调是同步的或立即调用的。
这个函数接受两个函数回调。
通常我们把这两个函数称为 resolve(..) 和 reject(..) :1
2
3
4var p = new Promise( function(resolve,reject){
// resolve(..)用于决议/完成这个promise
// reject(..)用于拒绝这个promise
} );
resolve(..) 既可能完成 promise,也可能拒绝,要根据传入参数而定。
如果传给 resolve(..) 的是一个非 Promise、非 thenable 的立即值,这个 promise 就会用这个值完成。
3.7.2 Promise.resolve(..) 和 Promise.reject(..)
创建一个已被拒绝的 Promise 的快捷方式是使用 Promise.reject(..) ,所以以下两个promise 是等价的:1
2
3
4var p1 = new Promise( function(resolve,reject){
reject( "Oops" );
} );
var p2 = Promise.reject( "Oops" );
Promise.resolve(..) 也会展开 thenable 值(前面已多次介绍)。
在这种情况下,返回的 Promise 采用传入的这个 thenable 的最终决议值,可能是完成,也可能是拒绝:
参考3.3.7
如果传入的是真正的 Promise, Promise.resolve(..) 什么都不会做,只会直接把这个值返回。
3.7.3 then(..) 和 catch(..)
Promise 决议之后,立即会调用这两个处理函数之一,但不会两个都调用,而且总是异步调用(参见 1.5 节)。
then(..) 接受一个或两个参数,如果两者中的任何一个被省略或者作为非函数值传入的话,就会替换为相应的默认回调。
默认完成回调只是把消息传递下去,而默认拒绝回调则只是重新抛出(传播)其接收到的出错原因。
catch(..) 只接受一个拒绝回调作为参数,并自动替换默认完成回调。
换句话说,它等价于 then(null,..) :
如果任意一个回调返回非 Promise、非 thenable 的立即值,这个值会被用作返回 promise 的完成值。
如果完成处理函数返回一个 promise 或 thenable,那么这个值会被展开,并作为返回promise 的决议值。
3.7.4 Promise.all([ .. ]) 和 Promise.race([ .. ])
门:
对 Promise.all([ .. ]) 来说,如果完成的话,你会得到一个数组,其中包含传入的所有 promise 的完成值。
对于拒绝的情况,你只会得到第一个拒绝 promise 的拒绝理由值。
门闩:
对 Promise.race([ .. ]) 来说,只有第一个决议的 promise(完成或拒绝)取胜,并且其决议结果成为返回 promise 的决议。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var p1 = Promise.resolve( 42 );
var p2 = Promise.resolve( "Hello World" );
var p3 = Promise.reject( "Oops" );
Promise.race( [p1,p2,p3] )
.then( function(msg){
console.log( msg ); // 42
} );
Promise.all( [p1,p2,p3] )
// 通过catch捕获
.catch( function(err){
console.error( err ); // "Oops"
} );
Promise.all( [p1,p2] )
.then( function(msgs){
console.log( msgs ); // [42,"Hello World"]
} );
若向 Promise.all([ .. ]) 传入空数组,它会立即完成,但 Promise.race([ .. ]) 会挂住,且永远不会决议。
3.8 Promise 局限性
3.8.1 顺序错误处理
如果构建了一个没有错误处理函数的 Promise 链,链中任何地方的任何错误都会在链中一直传播下去,最后的处理函数能够得到所有传播过来的错误的通知
1 | var p = foo( 42 ) |
这里的 p 并不指向链中的第一个 promise,而是指向最后一个 promise,即来自调用 then(STEP3) 的那一个。
所以可以在 p 上注册一个拒绝错误处理函数,对于链中任何位置出现的任何错误,这个处理函数都会得到通知:1
p.catch( handleErrors );
如果链中的任何一个步骤事实上进行了自身的错误处理,那你的 handleErrors(..) 就不会得到通知。
这等同于 try..catch 存在的局限: try..catch 可能捕获一个异常并简单地吞掉它。
3.8.2 单一值
Promise 只能有一个完成值或一个拒绝理由,在复杂的场景中,可能就会发现这是一种局限了。
有时候你可以把这一点当作提示你可以 / 应该把问题分解为两个或更多 Promise 的信号
3.8.2.1 分裂值
设想你有一个工具 foo(..) ,它可以异步产生两个值( x 和 y ):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21function getY(x) {
return new Promise( function(resolve,reject){
setTimeout( function(){
resolve( (3 * x) - 1 );
}, 100 );
} );
}
function foo(bar,baz) {
var x = bar * baz;
return getY( x )
.then( function(y){
// 把两个值封装到容器中
return [x,y]; // ★★★★★把 x 和 y 封装到一个数组值中
} );
}
foo( 10, 20 )
.then( function(msgs){
var x = msgs[0];
var y = msgs[1];
console.log( x, y ); // 200 599
} );
重新组织一下 foo(..) 返回的内容,这样就不再需要把 x 和 y 封装到一个数组值中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function foo(bar,baz) {
var x = bar * baz;
// ★★返回两个promise
return [
Promise.resolve( x ),
getY( x )
];
}
Promise.all(
foo( 10, 20 )
)
.then( function(msgs){
var x = msgs[0];
var y = msgs[1];
console.log( x, y );
} );
一个 promise 数组真的要优于传递给单个 promise 的一个值数组吗?从语法的角度来说,这算不上是一个改进,只是更整洁也更灵活。
3.8.2.2 展开 / 传递参数
var x = .. 和 var y = .. 赋值操作仍然是麻烦的开销。
ES6 给出了一个更好的答案:解构。1
2
3
4
5
6Promise.all(
foo( 10, 20 )
)
.then( function([x,y]){
console.log( x, y ); // 200 599
} );
3.8.3 单决议
Promise 最本质的一个特征是:Promise 只能被决议一次(完成或拒绝)。
但是,还有很多异步的情况适合另一种模式——一种类似于事件和 / 或数据流的模式。
设想这样一个场景:你可能要启动一系列异步步骤以响应某种可能多次发生的激励,比如按钮点击。1
2
3
4
5
6
7
8
9
10
11
12// click(..)把"click"事件绑定到一个DOM元素
// request(..)是前面定义的支持Promise的Ajax
var p = new Promise( function(resolve,reject){
click( "#mybtn", resolve );
} );
p.then( function(evt){
var btnID = evt.currentTarget.id;
return request( "http://some.url.1/?id=" + btnID );
} )
.then( function(text){
console.log( text );
} );
如果这个按钮被点击了第二次的话,promise p 已经决议,因此第二个 resolve(..) 调用就会被忽略。
转化这个范例:1
2
3
4
5
6
7click( "#mybtn", function(evt){
var btnID = evt.currentTarget.id;
request( "http://some.url.1/?id=" + btnID )
.then( function(text){
console.log( text );
} );
} );
这个设计在某种程度上破坏了关注点与功能分离(SoC)的思想。
另外一种清晰展示这种局限性的方法是:如果能够构建某种“可观测量”,可以将一个 Promise 链对应到这个“可观测量”就好了。
有一些库已经创建了这样的抽象(比如 RxJS,http://rxjs.codeplex.com),但是这种抽象看起来非常笨重.
附录 B 会再次讨论这种“可观测量”模式。
3.8.4 惯性
现存的所有代码都还不理解 Promise。
每个基于回调的工具手工定义支持 Promise 的封装,这样的开销会让你不太可能选择支持 Promise的重构。
Promise.wrap(..) 辅助工具:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// polyfill安全的guard检查
if (!Promise.wrap) {
Promise.wrap = function(fn) {
return function() {
var args = [].slice.call( arguments );
return new Promise( function(resolve,reject){
fn.apply(
null,
args.concat( function(err,v){
if (err) {
reject( err );
}
else {
resolve( v );
}
} )
);
} );
};
};
}
使用方式:1
2
3
4
5var request = Promise.wrap( ajax );
request( "http://some.url.1/" )
.then(
//
)
Promise.wrap(..) 并不产出 Promise。它产出的是一个将产生 Promise 的函数。
把需要回调的函数封装为支持 Promise 的函数,这个动作有时被称为“提升”或“Promise工厂化”。
Promise.wrap(ajax) 产生了一个 ajax(..) promisory,我们称之为 request(..) 。
这个 promisory 为 Ajax 响应生成 Promise。
回到前面的例子,我们需要为 ajax(..) 和 foo(..) 都构造一个 promisory:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 为ajax(..)构造一个promisory
var request = Promise.wrap( ajax );
// 重构foo(..),但使其外部成为基于外部回调的,
// 与目前代码的其他部分保持通用
// ——只在内部使用 request(..)的promise
function foo(x,y,cb) {
request(
"http://some.url.1/?x=" + x + "&y=" + y
)
.then(
function fulfilled(text){
cb( null, text );
},
cb
);
}
// 现在,为了这段代码的目的,为foo(..)构造一个 promisory
var betterFoo = Promise.wrap( foo );
// 并使用这个promisory
betterFoo( 11, 31 )
.then(
function fulfilled(text){
console.log( text );
},
function rejected(err){
console.error( err );
}
);
保持与代码库中其他部分兼容的基于回调的形式
现在foo(..)也是一个promisory,因为它委托了request(..) promisory1
2
3
4
5
6
7function foo(x,y) {
return request( // return
"http://some.url.1/?x=" + x + "&y=" + y
);
}
foo( 11, 31 )
.then( .. )
尽管原生 ES6 Promise 并没有提供辅助函数用于这样的 promisory 封装,但多数库都提供了这样的支持,或者你也可以构建自己的辅助函数。
3.8.5 无法取消的 Promise
一旦创建了一个 Promise 并为其注册了完成和 / 或拒绝处理函数,如果出现某种情况使得这个任务悬而未决的话,你也没有办法从外部停止它的进程。
很多 Promise 抽象库提供了工具来取消 Promise,但这个思路很可怕!
考虑前面的 Promise 超时场景:1
2
3
4
5
6
7
8
9
10
11
12var p = foo( 42 );
Promise.race( [
p,
timeoutPromise( 3000 )
] )
.then(
doSomething,
handleError
);
p.then( function(){
// 即使在超时的情况下也会发生 :(
} );
这个“超时”相对于 promise p 是外部的,所以 p 本身还会继续运行,这一点可能并不是我们所期望的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var OK = true;
var p = foo( 42 );
Promise.race( [
p,
timeoutPromise( 3000 )
.catch( function(err){ // ★ 重点是这个
OK = false; // ★ 还有这个 改变OK标志
throw err;
} )
] )
.then(
doSomething,
handleError
);
p.then( function(){
if (OK) { // ★ 通过判断来决定是否执行
// 只在没有超时情况下才会发生 :)
}
} );
这很丑陋,但可以工作。
我建议你应查看 Promise 抽象库以获得帮助,而不是 hack 自己的版本。
3.8.6 Promise 性能
Promise 进行的动作要比回调的异步任务链的动作多一些,这自然意味着它也会稍慢一些。
更多的工作,更多的保护。这些意味着 Promise 与不可信任的裸回调相比会更慢一些。
有一些立即(同步)完成的步骤仍然会延迟到任务的下一步。
这意味着一个 Promise 任务序列可能比完全通过回调连接的同样的任务序列运行得稍慢一点。
Promise 稍慢一些,但是作为交换,你得到的是大量内建的可信任性、对 Zalgo 的避免以及可组合性。
4.生成器
第 2 章里,我们确定了回调表达异步控制流程的两个关键缺陷:
• 基于回调的异步不符合大脑对任务步骤的规划方式;
• 由于控制反转,回调并不是可信任或可组合的。
在第 3 章里,我们详细介绍了 Promise 如何把回调的控制反转反转回来,恢复了可信任性 /可组合性。
现在我们把注意力转移到一种顺序、看似同步的异步流程控制表达风格。
4.1 打破完整运行
普遍依赖的假定:一个函数一旦开始执行,就会运行到结束,期间不会有其他代码能够打断它并插入其间。
不过 ES6 引入了一个新的函数类型,它并不符合这种运行到结束的特性。
ES6 代码中指示暂停点的语法是 yield
下面是实现这样的合作式并发的 ES6 代码:1
2
3
4
5
6
7
8
9var x = 1;
function *foo() {
x++;
yield; // 暂停!
console.log( "x:", x );
}
function bar() {
x++;
}
生成器声明格式推荐:function *foo() { .. }
因为这样在使用 *foo()来引用生成器的时候就会比较一致。
使得 bar() 在 *foo() 内部的 yield 处执行呢?1
2
3
4
5
6
7
8// 构造一个迭代器it来控制这个生成器
var it = foo();
// 这里启动foo()!
it.next();
x; // 2
bar();
x; // 3
it.next(); // x: 3
foo() 启动了,但是没有完整运行,它在 yield 处暂停了。后面恢复了 foo() 并让它运行到结束,但这不是必需的。
4.1.1 输入和输出
它可以接受参数(即输入),也能够返回值(即输出)。1
2
3
4
5
6function *foo(x,y) {
return x * y;
}
var it = foo( 6, 7 );
var res = it.next();
res.value; // 42
这个 next(..) 调用的结果是一个对象,它有一个 value 属性,持有从 *foo(..) 返回的值(如果有的话)。
yield 会导致生成器在执行过程中发送出一个值,这有点类似于中间的 return 。
4.1.1.1 迭代消息传递
生成器提供了内建消息输入输出能力,通过 yield 和 next(..) 实现。
1 | function *foo(x) { |
在 foo(..) 内部,开始执行语句 var y = x .. ,但随后就遇到了一个 yield 表达式。
它就会在这一点上暂停 foo(..) (在赋值语句中间!),并在本质上要求调用代码为 yield
表达式提供一个结果值。
接下来,调用 it.next( 7 ) ,这一句把值 7 传回作为被暂停的yield 表达式的结果。
一般来说,需要的 next(..) 调用要比 yield 语句多一个,前面的代码片段有一个 yield 和两个 next(..) 调用。
4.1.1.2 两个问题的故事
把视角转化一下:不从生成器的视角看这个问题,而是从迭代器的角度。
消息是双向传递的——
yield.. 作为一个表达式可以发出消息响应 next(..) 调用,
next(..) 也可以向暂停的 yield 表达式发送值。1
2
3
4
5
6
7
8
9function *foo(x) {
var y = x * (yield "Hello"); // <-- yield一个值!
return y;
}
var it = foo( 6 );
var res = it.next(); // 第一个next(),并不传入任何东西
res.value; // "Hello"
res = it.next( 7 ); // 向等待的yield传入7
res.value; // 42
yield .. 和 next(..) 这一对组合起来,在生成器的执行过程中构成了一个双向消息传递系统。1
2
3
4var res = it.next(); // 第一个next(),并不传入任何东西
res.value; // "Hello"
res = it.next( 7 ); // 向等待的yield传入7
res.value; // 42
我们并没有向第一个 next() 调用发送值,这是有意为之。
只有暂停的 yield 才能接受这样一个通过 next(..) 传递的值,而在生成器的起始处我们调用第一个 next() 时,还没有暂停的 yield 来接受这样一个值。
规范和所有兼容浏览器都会默默丢弃传递给第一个 next() 的任何东西。
最后一个 it.next(7) 调用再次提出了这样的问题:生成器将要产生的下一个值是什么。
但是,再没有 yield 语句来回答这个问题了,是不是?那么谁来回答呢?return 语句回答这个问题!
生成器中和在普通函数中一样, return 当然不是必需的——总有一个假定的 / 隐式的 return; (也就是 return undefined; )
4.1.2 多个迭代器
每次构建一个迭代器,实际上就隐式构建了生成器的一个实例,通过这个迭代器来控制的是这个生成器实例。
同一个生成器的多个实例可以同时运行,它们甚至可以彼此交互:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function *foo() {
var x = yield 2;
z++;
var y = yield (x * z);
console.log( x, y, z );
}
var z = 1; // 全局的 所以会累加
var it1 = foo();
var it2 = foo();
var val1 = it1.next().value; // 2 <-- yield 2 不同的实例
var val2 = it2.next().value; // 2 <-- yield 2 不同的实例
val1 = it1.next( val2 * 10 ).value; // 40 <-- x:20, z:2 返回第二个yeild 后边运算后的值
val2 = it2.next( val1 * 5 ).value; // 600 <-- x:200, z:3
it1.next( val2 / 2 ); // y:300
// 20 300 3
it2.next( val1 / 4 ); // y:10
// 200 10 3
交替执行
1 | var a = 1; |
不用生成器,只有两种可能,要么foo先执行,要么bar先执行
使用生成器的话,交替执行成为可能!1
2
3
4
5
6
7
8
9
10
11
12
13
14var a = 1;
var b = 2;
function *foo() {
a++;
yield;
b = b * a;
a = (yield b) + 3;
}
function *bar() {
b--;
yield;
a = (yield 8) + b;
b = a * (yield 2);
}
来构建一个名为 step(..) 的辅助函数,用于控制迭代器:1
2
3
4
5
6
7
8function step(gen) {
var it = gen();
var last;
return function() {
// 不管yield出来的是什么,下一次都把它原样传回去!
last = it.next( last ).value;
};
}
前面的 yield 发出的值会在下一步发送回去。
于是,yield 8 就是 8 ,而 yield b 就是 b ( yield 发出时的值)。
用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14// 确保重新设置a和b
a = 1;
b = 2;
var s1 = step( foo );
var s2 = step( bar );
s2(); // b--;
s2(); // yield 8
s1(); // a++;
s2(); // a = 8 + b;
// yield 2
s1(); // b = b * a;
// yield b
s1(); // a = b + 3;
s2(); // b = a * 2;
4.2 生成器产生值
先介绍一点迭代器
4.2.1 生产者与迭代器
假定你要产生一系列值,其中每个值都与前面一个有特定的关系。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var gimmeSomething = (function(){
var nextVal; // 外层不能访问到
return function(){ // 其实执行的就是这个函数 里边的nextVal是访问的上一层的,每次执行都是执行的上一层的,上一层的会叠加,但是一直保持在最外层里边
if (nextVal === undefined) {
nextVal = 1;
}
else {
nextVal = (3 * nextVal) +6;
}
return nextVal;
};
})();
gimmeSomething(); // 1
gimmeSomething(); // 9
gimmeSomething(); // 33
gimmeSomething(); // 105
生成任意数字序列并不是一个很实际的例子。
实际上,这个任务是一个非常通用的设计模式,通常通过迭代器来解决。
迭代器是一个定义良好的接口,用于从一个生产者一步步得到一系列值。
可以为我们的数字序列生成器实现标准的迭代器接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21var something = (function(){
var nextVal;
return {
// for..of循环需要
[Symbol.iterator]: function(){ return this; },
// 标准迭代器接口方法
next: function(){
if (nextVal === undefined) {
nextVal = 1;
}
else {
nextVal = (3 * nextVal) + 6;
}
return { done:false, value:nextVal };
}
};
})();
something.next().value; // 1
something.next().value; // 9
something.next().value; // 33
something.next().value; // 105
在 4.2.2 节解释为什么在这段代码中需要 [Symbol.iterator]: .. 这一部分。
从语法上说,这涉及了两个 ES6 特性。首先, [ .. ] 语法被称为计算属性名
另外, Symbol.iterator 是 ES6 预定义的特殊Symbol 值之一
next() 调用返回一个对象。这个对象有两个属性: done 是一个 boolean 值,标识迭代器的完成状态; value 中放置迭代值。
ES6 还新增了一个 for..of 循环,这意味着可以通过原生循环语法自动迭代标准迭代器:1
2
3
4
5
6
7
8for (var v of something) {
console.log( v );
// 不要死循环!
if (v > 500) {
break;
}
}
// 1 9 33 105 321 969
因为我们的 迭代器 something 总是返回 done:false ,因此这个 for..of 循环将永远运行下去,这也就是为什么我们要在里面放一个 break 条件。
在接收到 done:true 之后自动停止。
也可以手工在迭代器上循环,调用 next() 并检查 done:true 条件来确定何时停止循环:1
2
3
4
5
6
7
8
9
10
11for (
var ret;
(ret = something.next()) && !ret.done;
) {
console.log( ret.value );
// 不要死循环!
if (ret.value > 500) {
break;
}
}
// 1 9 33 105 321 969
这种手工 for 方法当然要比 ES6 的 for..of 循环语法丑陋,但其优点是,这样就可以在需要时向 next() 传递值。
许多 JavaScript 的内建数据结构(从 ES6 开始),比如 array ,也有默认的迭代器:1
2
3
4
5var a = [1,3,5,7,9];
for (var v of a) {
console.log( v );
}
// 1 3 5 7 9
for..of 循环向 a 请求它的迭代器,并自动使用这个迭代器迭代遍历 a 的值。
一般的 object 是故意不像 array 一样有默认的迭代器。
如果你只是想要迭代一个对象的所有属性的话(不需要保证特定的顺序),
可以通过 Object.keys(..) 返回一个 array ,类似于 for (var k of Object.keys(obj)) { .. 这样使用。
4.2.2 iterable
iterable(可迭代),即指一个包含可以在其值上迭代的迭代器的对象。
从 ES6 开始,从一个 iterable 中提取迭代器的方法是:
iterable 必须支持一个函数,其名称是专门的 ES6 符号值 Symbol.iterator 。
调用这个函数时,它会返回一个迭代器。
通常每次调用会返回一个全新的迭代器,虽然这一点并不是必须的。
前面代码片段中的 a 就是一个 iterable。
for..of 循环自动调用它的 Symbol.iterator 函数来构建一个迭代器。
我们当然也可以手工调用这个函数,然后使用它返回的迭代器:1
2
3
4
5var a = [1,3,5,7,9];
var it = a[Symbol.iterator]();
it.next().value; // 1
it.next().value; // 3
it.next().value; // 5
前面的代码中列出了定义的 something ,你可能已经注意到了这一行:1
[Symbol.iterator]: function(){ return this; }
将 something 的值也构建成为一个 iterable。
现在它既是 iterable,也是迭代器。
1 | for (var v of something) { |
for..of 循环期望 something 是 iterable,于是它寻找并调用它的 Symbol.iterator 函数。
我们将这个函数定义为就是简单的 return this ,也就是把自身返回,而 for..of 循环并不知情。
4.2.3 生成器迭代器
可以把生成器看作一个值的生产者,我们通过迭代器接口的 next() 调用一次提取出一个值。
所以,严格说来,生成器本身并不是 iterable,尽管非常类似——当你执行一个生成器,就得到了一个迭代器:1
2function *foo(){ .. }
var it = foo();
通过生成器实现前面的这个 something 无限数字序列生产者,类似这样:1
2
3
4
5
6
7
8
9
10
11
12function *something() {
var nextVal;
while (true) {
if (nextVal === undefined) {
nextVal = 1;
}
else {
nextVal = (3 * nextVal) + 6;
}
yield nextVal;
}
}
通常在实际的 JavaScript 程序中使用 while..true 循环是非常糟糕的主意,
至少如果其中没有 break 或 return 的话是这样,因为它有可能会同步地无限循环,并阻塞和锁住浏览器 UI。
但是,如果在生成器中有 yield 的话,使用这样的循环就完全没有问题。
因为生成器会在每次迭代中暂停,通过 yield 返回到主程序或事件循环队列中。
简单地说就是:“生成器把 while..true 带回了 JavaScript 编程的世界!”
因为生成器会在每个 yield 处暂停,函数 *something() 的状态(作用域)会被保持,
即意味着不需要闭包在调用之间保持变量状态。
现在,可以通过 for..of 循环使用我们雕琢过的新的 *something() 生成器。1
2
3
4
5
6
7
8for (var v of something()) {
console.log( v );
// 不要死循环!
if (v > 500) {
break;
}
}
// 1 9 33 105 321 969
如果认真思考的话,你也许会从这段生成器与循环的交互中提出两个问题。
• 为什么不能用 for (var v of something) .. ?(没有()运行符号)因为这里的 something 是生成器,并不是
iterable。我们需要调用 something() 来构造一个生产者供 for..of 循环迭代。
• something() 调用产生一个迭代器,但 for..of 循环需要的是一个 iterable,对吧?是
的。生成器的迭代器也有一个 Symbol.iterator 函数,基本上这个函数做的就是 return this ,
和我们前面定义的 iterable something 一样。换句话说,生成器的迭代器也是一个iterable !
停止生成器
在前面的例子中,看起来似乎 *something() 生成器的迭代器实例在循环中的 break 调用之后就永远留在了挂起状态。
其实有一个隐藏的特性会帮助你管理此事。 for..of 循环的“异常结束”(也就是“提前终止”),
通常由 break 、 return 或者未捕获异常引起,会向生成器的迭代器发送一个信号使其终止。
尽管 for..of 循环会自动发送这个信号,但你可能会希望向一个迭代器手工发送这个信号。
可以通过调用 return(..) 实现这一点。
如果在生成器内有 try..finally 语句,它将总是运行,即使生成器已经外部结束。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18function *something() {
try {
var nextVal;
while (true) {
if (nextVal === undefined) {
nextVal = 1;
}
else {
nextVal = (3 * nextVal) + 6;
}
yield nextVal;
}
}
// 清理子句
finally {
console.log( "cleaning up!" );
}
}
之前的例子中, for..of 循环内的 break 会触发 finally 语句。
但是,也可以在外部通过return(..) 手工终止生成器的迭代器实例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var it = something();
for (var v of it) {
console.log( v );
// 不要死循环!
if (v > 500) {
console.log(
// 完成生成器的迭代器
it.return( "Hello World" ).value
);
// 这里不需要break
}
}
// 1 9 33 105 321 969
// 清理!
// Hello World
调用 it.return(..) 之后,它会立即终止生成器,这当然会运行 finally 语句。
另外,它还会把返回的 value 设置为传入 return(..) 的内容,这也就是 “Hello World” 被传出去的过程。
现在我们也不需要包含 break 语句了,因为生成器的迭代器已经被设置为done:true ,所以 for..of 循环会在下一个迭代终止。
4.3 异步迭代生成器
我们应该重新讨论第 3 章中的一个场景。回想一下回调方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14function foo(x,y,cb) {
ajax(
"http://some.url.1/?x=" + x + "&y=" + y,
cb
);
}
foo( 11, 31, function(err,text) {
if (err) {
console.error( err );
}
else {
console.log( text );
}
} );
如果想要通过生成器来表达同样的任务流程控制,可以这样实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27function foo(x,y) {
ajax(
"http://some.url.1/?x=" + x + "&y=" + y,
function(err,data){
if (err) {
// 向*main()抛出一个错误
it.throw( err );
}
else {
// 用收到的data恢复*main()
it.next( data );
}
}
);
}
function *main() {
try {
var text = yield foo( 11, 31 ); // foo没有返回值
console.log( text );
}
catch (err) {
console.error( err );
}
}
var it = main();
// 这里启动!
it.next();
首先,让我们查看一下最重要的这段代码:1
2var text = yield foo( 11, 31 );
console.log( text );
第 1 章的开始部分的话,我们给出了几乎相同的代码:1
2var data = ajax( "..url 1.." );
console.log( data );
在 yield foo(11,31) 中,首先调用 foo(11,31) ,它没有返回值return(即返回 undefined )
所以,生成器在 yield 处暂停,本质上是在提出一个问题:“我应该返回什么值来赋给变量text ?”
看一下 foo(..) 。如果这个 Ajax 请求成功,我们调用:1
it.next( data );
同步错误处理
前面的生成器代码甚至还给我们带来了更多其他的好处。
让我们把注意力转移到生成器内部的 try..catch :
下边这个其实是在*main()内部的1
2
3
4
5
6
7try {
var text = yield foo( 11, 31 );
console.log( text );
}
catch (err) {
console.error( err );
}
调用 foo(..) 是异步完成的,难道 try..catch 不是无法捕获异步错误,就像我们在第 3 章中看到的一样吗?
我们已经看到 yield 是如何让赋值语句暂停来等待 foo(..) 完成,使得响应完成后可以被赋给 text 。
精彩的部分在于 yield 暂停也使得生成器能够捕获错误。
代码把错误抛出到生成器中:1
2
3
4if (err) {
// 向*main()抛出一个错误
it.throw( err );
}
生成器 yield 暂停的特性意味着我们不仅能够从异步函数调用得到看似同步的返回值,还可以同步捕获来自这些异步函数调用的错误!
从生成器向外抛出错误:1
2
3
4
5
6
7
8
9
10
11
12function *main() {
var x = yield "Hello World";
yield x.toLowerCase(); // 引发一个异常!
}
var it = main();
it.next().value; // Hello World
try { // 在 *main()外部
it.next( 42 );
}
catch (err) {
console.error( err ); // TypeError
}
也可以通过 throw .. 手工抛出一个错误1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function *main() {
var x = yield "Hello World";
// 永远不会到达这里
console.log( x );
}
var it = main();
it.next();
try {
// *main()会处理这个错误吗?看看吧!
it.throw( "Oops" ); // 手工抛出
}
catch (err) {
// 不行,没有处理!
console.error( err ); // Oops
}
4.4 生成器 +Promise
生成器可以解决异步变成同步,但是却错失了很重要的两点:Promise 的可信任性和可组合性1
2
3
4
5
6
7
8
9
10
11
12
13
14function foo(x,y) {
return request(
"http://some.url.1/?x=" + x + "&y=" + y
);
}
foo( 11, 31 )
.then(
function(text){
console.log( text );
},
function(err){
console.error( err );
}
);
在前面的运行 Ajax 例子的生成器代码中, foo(..) 没有返回值( undefined ),并且我们的迭代器控制代码并不关心 yield 出来的值。
而这里支持 Promise 的 foo(..) 在发出 Ajax 调用之后返回了一个 promise。
这暗示我们可以通过 foo(..) 构造一个 promise,然后通过生成器把它 yield 出来,然后迭代器控制代码就可以接收到这个 promise 了。
迭代器应该侦听这个 promise 的决议(完成或拒绝),然后要么使用完成消息恢复生成器运行,要么向生成器抛出一个带有拒绝原因的错误。
获得 Promise 和生成器最大效用的最自然的方法就是 yield 出来一个 Promise,然后通过这个 Promise 来控制生成器的迭代器。
来试一下1
2
3
4
5
6
7
8
9
10
11
12
13
14function foo(x,y) {
return request(
"http://some.url.1/?x=" + x + "&y=" + y
);
}
function *main() {
try {
var text = yield foo( 11, 31 );
console.log( text );
}
catch (err) {
console.error( err );
}
}
实现接收和连接 yield 出来的 promise,使它能够在决议之后恢复生成器。先从手工实现开始:1
2
3
4
5
6
7
8
9
10
11var it = main();
var p = it.next().value;
// 等待promise p决议
p.then(
function(text){
it.next( text );
},
function(err){
it.throw( err );
}
);
4.4.1 支持 Promise 的 Generator Runner
有几个 Promise 抽象库提供了这样的工具,包括我的 asynquence 库及其 runner(..) ,本部分的附录 A 中会介绍。
为了学习和展示的目的,我们还是自己定义一个独立工具,叫作 run(..) :1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// 在此感谢Benjamin Gruenbaum (@benjamingr on GitHub)的巨大改进!
function run(gen) {
var args = [].slice.call( arguments, 1), it;
// 在当前上下文中初始化生成器
it = gen.apply( this, args ); // it就是gen(args)
// 返回一个promise用于生成器完成
return Promise.resolve()
.then( function handleNext(value){
// 对下一个yield出的值运行
var next = it.next( value );
return (function handleResult(next){
// 生成器运行完毕了吗?
if (next.done) {
return next.value;
}
// 否则继续运行
else {
return Promise.resolve( next.value )
.then(
// 成功就恢复异步循环,把决议的值发回生成器
handleNext,
// 如果value是被拒绝的 promise,
// 就把错误传回生成器进行出错处理
function handleErr(err) {
return Promise.resolve(
it.throw( err )
)
.then( handleResult );
}
);
}
})(next);
} );
}
使用方法1
2
3
4function *main() {
// ..
}
run( main );
ES7: async 与 await ?
其形式很可能会类似如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function foo(x,y) {
return request(
"http://some.url.1/?x=" + x + "&y=" + y
);
}
async function main() {
try {
var text = await foo( 11, 31 );
console.log( text );
}
catch (err) {
console.error( err );
}
}
main();
有 C# 经验的人可能很熟悉 async/await 语法,因为它们基本上是相同的。
4.4.2 生成器中的 Promise 并发
想象这样一个场景:你需要从两个不同的来源获取数据,然后把响应组合在一起以形成第三个请求,最终把最后一条响应打印出来。
最简单的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14function *foo() {
// 让两个请求"并行"
var p1 = request( "http://some.url.1" ); // 已经开始并行执行
var p2 = request( "http://some.url.2" ); // 已经开始并行执行
// 等待两个promise都决议
var r1 = yield p1;
var r2 = yield p2;
var r3 = yield request(
"http://some.url.3/?v=" + r1 + "," + r2
);
console.log( r3 );
}
// 使用前面定义的工具run(..)
run( foo );
通过Promise实现流程控制1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function *foo() {
// 让两个请求"并行",并等待两个promise都决议
var results = yield Promise.all( [
request( "http://some.url.1" ),
request( "http://some.url.2" )
] );
var r1 = results[0];
var r2 = results[1];
var r3 = yield request(
"http://some.url.3/?v=" + r1 + "," + r2
);
console.log( r3 );
}
// 使用前面定义的工具run(..)
run( foo );
隐藏的 Promise
将Promise从生成器中抽离出来1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 注:普通函数,不是生成器 ★ 从生成器中将Promise抽离出来
function bar(url1,url2) {
return Promise.all( [
request( url1 ),
request( url2 )
] );
}
function *foo() {
// 隐藏bar(..)内部基于Promise的并发细节
var results = yield bar(
"http://some.url.1",
"http://some.url.2"
);
var r1 = results[0];
var r2 = results[1];
var r3 = yield request(
"http://some.url.3/?v=" + r1 + "," + r2
);
console.log( r3 );
}
// 使用前面定义的工具run(..)
run( foo );
4.5 生成器委托
从一个生成器调用另一个生成器,使用辅助函数 run(..)1
2
3
4
5
6
7
8
9
10
11
12function *foo() {
var r2 = yield request( "http://some.url.2" );
var r3 = yield request( "http://some.url.3/?v=" + r2 );
return r3;
}
function *bar() {
var r1 = yield request( "http://some.url.1" );
// ☆通过 run(..) "委托"给*foo()
var r3 = yield run( foo );
console.log( r3 );
}
run( bar );
一个更好的方法可以实现从 bar() 调用 foo() ,称为 yield 委托。
yield 委托的具体语法是: yield __(注意多出来的 )。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20function *foo() {
console.log( "*foo() starting" );
yield 3;
yield 4;
console.log( "*foo() finished" );
}
function *bar() {
yield 1;
yield 2;
yield *foo(); // ☆yield委托!
yield 5;
}
var it = bar();
it.next().value; // 1
it.next().value; // 2
it.next().value; // *foo()启动
// 3
it.next().value; // 4
it.next().value; // *foo()完成
// 5
一旦 it 迭代器控制消耗了整个 foo() 迭代器, it 就会自动转回控制 bar() 。
回到前面使用三个顺序 Ajax 请求的例子:1
2
3
4
5
6
7
8
9
10
11
12function *foo() {
var r2 = yield request( "http://some.url.2" );
var r3 = yield request( "http://some.url.3/?v=" + r2 );
return r3;
}
function *bar() {
var r1 = yield request( "http://some.url.1" );
// 通过 yeild* "委托"给*foo()
var r3 = yield *foo();
console.log( r3 );
}
run( bar );
这段代码和前面版本的唯一区别就在于使用了 yield *foo(), 而不是前面的 yield run(foo) 。
4.5.1 为什么用委托
把两者分开实现的原因是该程序的适当的代码组织要求它们位于不同的函数中。
保持生成器分离有助于程序的可读性、可维护性和可调试性。
yield *foo() 消除了对 run(..)工具的需要.
4.5.2 消息委托
也用于双向消息传递工作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28function *foo() {
console.log( "inside *foo():", yield "B" );
console.log( "inside *foo():", yield "C" );
return "D";
}
function *bar() {
console.log( "inside *bar():", yield "A" );
// yield委托!
console.log( "inside *bar():", yield *foo() );
console.log( "inside *bar():", yield "E" );
return "F"; // 注意这里
}
var it = bar();
console.log( "outside:", it.next().value );
// outside: A
console.log( "outside:", it.next( 1 ).value );
// inside *bar(): 1
// outside: B
console.log( "outside:", it.next( 2 ).value );
// inside *foo(): 2
// outside: C
console.log( "outside:", it.next( 3 ).value );
// inside *foo(): 3
// inside *bar(): D
// outside: E
console.log( "outside:", it.next( 4 ).value );
// inside *bar(): 4
// outside: F
注意:console.log的执行顺序
yield 委托甚至并不要求必须转到另一个生成器,它可以转到一个非生成器的一般 iterable。比如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23function *bar() {
console.log( "inside *bar():", yield "A" );
// yield委托给非生成器!
console.log( "inside *bar():", yield *[ "B", "C", "D" ] );
console.log( "inside *bar():", yield "E" );
return "F";
}
var it = bar();
console.log( "outside:", it.next().value );
// outside: A
console.log( "outside:", it.next( 1 ).value );
// inside *bar(): 1
// outside: B
console.log( "outside:", it.next( 2 ).value );
// outside: C
console.log( "outside:", it.next( 3 ).value );
// outside: D
console.log( "outside:", it.next( 4 ).value );
// inside *bar(): undefined
// outside: E
console.log( "outside:", it.next( 5 ).value );
// inside *bar(): 5
// outside: F
最显著的是,默认的数组迭代器并不关心通过 next(..) 调用发送的任何消息,所以值 2 、3 和 4 根本就被忽略了。
还有,因为迭代器没有显式的返回值(和前面使用的 foo() 不同),所以 yield 表达式完成后得到的是一个 undefined 。
异常也被委托
和 yield 委托透明地双向传递消息的方式一样,错误和异常也是双向传递的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44function *foo() {
try {
yield "B";
}
catch (err) {
console.log( "error caught inside *foo():", err );
}
yield "C";
throw "D";
}
function *bar() {
yield "A";
try {
yield *foo();
}
catch (err) {
console.log( "error caught inside *bar():", err );
}
yield "E";
yield *baz();
// 注:不会到达这里!
yield "G";
}
function *baz() {
throw "F";
}
var it = bar();
console.log( "outside:", it.next().value );
// outside: A
console.log( "outside:", it.next( 1 ).value );
// outside: B
console.log( "outside:", it.throw( 2 ).value );
// error caught inside *foo(): 2
// outside: C
console.log( "outside:", it.next( 3 ).value );
// error caught inside *bar(): D
// outside: E
try {
console.log( "outside:", it.next( 4 ).value );
}
catch (err) {
console.log( "error caught outside:", err );
}
// error caught outside: F
这段代码中需要注意以下几点。
(1) 调用 it.throw(2) 时,它会发送错误消息 2 到 bar() ,它又将其委托给
foo() ,后者捕
获并处理它。然后, yield “C” 把 “C” 发送回去作为 it.throw(2) 调用返回的 value 。
(2) 接下来从 foo() 内 throw 出来的值 “D” 传播到 bar() ,这个函数捕获并处理它。然后
yield “E” 把 “E” 发送回去作为 it.next(3) 调用返回的 value 。
(3) 然后,从 baz() throw 出来的异常并没有在 bar() 内被捕获——所以 baz() 和 bar()
都被设置为完成状态。这段代码之后,就再也无法通过任何后续的 next(..) 调用得到
值 “G” , next(..) 调用只会给 value 返回 undefined 。
4.5.3 异步委托
回到前面的多个顺序 Ajax 请求的 yield 委托例子:1
2
3
4
5
6
7
8
9
10
11function *foo() {
var r2 = yield request( "http://some.url.2" );
var r3 = yield request( "http://some.url.3/?v=" + r2 );
return r3;
}
function *bar() {
var r1 = yield request( "http://some.url.1" );
var r3 = yield *foo(); // 不再用run()
console.log( r3 );
}
run( bar );
之前的版本中,使用了 Promise 机制(通过 run(..) 控制)把值从 foo() 内的 return r3 传递给 bar() 中的局部变量 r3 。
现在,这个值通过 yield * 机制直接返回。
4.5.4 递归委托
可以使用 yield委托实现异步的生成器递归,即一个 yield 委托到它自身的生成器:1
2
3
4
5
6
7
8
9
10
11
12function *foo(val) {
if (val > 1) {
// 生成器递归
val = yield *foo( val - 1 );
}
return yield request( "http://some.url/?v=" + val );
}
function *bar() {
var r1 = yield *foo( 3 );
console.log( r1 );
}
run( bar );
4.6 生成器并发
1 | // request(..)是一个支持Promise的Ajax工具 |
在这里,两个实例都是各自的响应一回来就取得了数据,然后每个实例再次 yield ,用于控制传递的目的。
然后我们在 Promise.all([ .. ]) 处理函数中选择它们的恢复顺序。
还可以做得更好。来设想一下使用一个称为 runAll(..) 的工具:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// request(..)是一个支持Promise的Ajax工具
var res = [];
runAll(
function*(){
var p1 = request( "http://some.url.1" );
// 控制转移
yield;
res.push( yield p1 );
},
function*(){
var p2 = request( "http://some.url.2" );
// 控制转移
yield;
res.push( yield p2 );
}
);
我的 asynquence 库也提供了一个前面提过的 runner(..)工具,其中已经内建了对类功能的支持,这将在本部分的附录 A 中讨论。
如果继续扩展 runAll(..) 来提供一个内层的变量空间,以使多个生成器实例可以共享,将是非常有帮助的,比如下面这个称为 data 的空对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// request(..)是一个支持Promise的Ajax工具
runAll(
function*(data){
data.res = [];
// 控制转移(以及消息传递)
var url1 = yield "http://some.url.2";
var p1 = request( url1 ); // "http://some.url.1"
// 控制转移
yield;
data.res.push( yield p1 );
},
function*(data){
// 控制转移(以及消息传递)
var url2 = yield "http://some.url.1";
var p2 = request( url2 ); // "http://some.url.2"
// 控制转移
yield;
data.res.push( yield p2 );
}
);
继续扩展 runAll(..) 来提供一个内层的变量空间,以使多个生成器实例可以共享,将是非常有帮助的,比如下面这个称为 data 的空对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// request(..)是一个支持Promise的Ajax工具
runAll(
function*(data){
data.res = [];
// 控制转移(以及消息传递)
var url1 = yield "http://some.url.2";
var p1 = request( url1 ); // "http://some.url.1"
// 控制转移
yield;
data.res.push( yield p1 );
},
function*(data){
// 控制转移(以及消息传递)
var url2 = yield "http://some.url.1";
var p2 = request( url2 ); // "http://some.url.2"
// 控制转移
yield;
data.res.push( yield p2 );
}
);
两个生成器不只是协调控制转移,还彼此通信
通过 data.res 和 yield 的消息来交换 url1 和 url2 的值
4.7 形实转换程序
在通用计算机科学领域,有一个早期的前 JavaScript 概念,称为形实转换程序(thunk)。
直接给出形实转换程序的一个狭义表述:JavaScript 中的 thunk 是指一个用于调用另外一个函数的函数,没有任何参数。1
2
3
4
5
6
7
8function foo(x,y) {
return x + y;
}
function fooThunk() {
return foo( 3, 4 );
}
// 将来
console.log( fooThunk() ); // 7
同步的 thunk 是非常简单的。但如果是异步的 thunk 呢?—回调1
2
3
4
5
6
7
8
9
10
11
12function thunkify(fn) {
var args = [].slice.call( arguments, 1 );
return function(cb) {
args.push( cb );
return fn.apply( null, args );
};
}
var fooThunk = thunkify( foo, 3, 4 );
// 将来
fooThunk( function(sum) {
console.log( sum ); // 7
} );
典型的方法——如果不令人迷惑的话——并不是 thunkify(..) 构造 thunk 本身,而是thunkify(..) 工具产生一个生成 thunk 的函数。1
2
3
4
5
6
7
8
9function thunkify(fn) {
return function() {
var args = [].slice.call( arguments );
return function(cb) {
args.push( cb );
return fn.apply( null, args );
};
};
}
主要的区别在于多出来的 return function() { .. } 这一层。以下是用法上的区别:1
2
3
4
5
6var whatIsThis = thunkify( foo );
var fooThunk = whatIsThis( 3, 4 );
// 将来
fooThunk( function(sum) {
console.log( sum ); // 7
} );
这段代码暗藏的一个大问题是: whatIsThis 调用的是什么。并不是这个 thunk,而是某个从 foo(..) 调用产生 thunk 的东西。这有点类似于 thunk 的“工厂”。
所以我的建议是 thunkory(thunk+factory)。
于是就有, thunkify(..) 生成一个 thunkory,然后 thunkory 生成 thunk。1
2
3
4
5
6
7
8
9
10var fooThunkory = thunkify( foo );
var fooThunk1 = fooThunkory( 3, 4 );
var fooThunk2 = fooThunkory( 5, 6 );
// 将来
fooThunk1( function(sum) {
console.log( sum ); // 7
} );
fooThunk2( function(sum) {
console.log( sum ); // 11
} );
暴露 thunkory 方法——而不是像前面的 thunkify(..) 那样把这个中间步骤隐藏——似乎是不必要的复杂性。1
2
3
4
5
6
7// 更简洁:
var fooThunkory = thunkify( foo );
var fooThunk1 = fooThunkory( 3, 4 );
var fooThunk2 = fooThunkory( 5, 6 );
// 而不是:
var fooThunk1 = thunkify( foo, 3, 4 );
var fooThunk2 = thunkify( foo, 5, 6 );
s/promise/thunk/
可以把 thunk 和 promise 大体上对比一下:
它们都可以被看作是对一个值的请求,回答可能是异步的。
第 3 章里我们定义了一个Promise.wrap(..) ,也可以将其称为 promisify(..) !
这个 Promise 封装工具并不产生Promise,它生成的是 promisory,而 promisory 则接着产生 Promise。
这和现在讨论的thunkory 和 thunk 是完全对称的。
首先把前面的 foo(..) 例子修改一下,改成使用 error-first 风格的回调:1
2
3
4
5
6function foo(x,y,cb) {
setTimeout( function(){
// 假定cb(..)是error-first风格的
cb( null, x + y );
}, 1000 );
}
对比一下 thunkify(..) 和 promisify(..)的使用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 对称:构造问题提问者
var fooThunkory = thunkify( foo );
var fooPromisory = promisify( foo );
// 对称:提问
var fooThunk = fooThunkory( 3, 4 );
var fooPromise = fooPromisory( 3, 4 );
// 得到答案
fooThunk( function(err,sum){
if (err) {
console.error( err );
}
else {
console.log( sum ); // 7
}
} );
// 得到promise答案
fooPromise
.then(
function(sum){
console.log( sum ); // 7
},
function(err){
console.error( err );
}
);
了解了这个视角之后,就可以看出, yield 出 Promise 以获得异步性的生成器,也可以为
异步性而 yield thunk。我们所需要的只是一个更智能的 run(..) 工具(就像前面的一样),
不但能够寻找和链接 yield 出来的 Promise,还能够向 yield 出来的 thunk 提供回调。
考虑:1
2
3
4
5function *foo() {
var val = yield request( "http://some.url.1" );
console.log( val );
}
run( foo );
在这个例子中, request(..) 可能是一个返回 promise 的 promisory,也可能是一个返回
thunk 的 thunkory。从生成器内部的代码逻辑的角度来说,我们并不关心这个实现细节,这
一点是非常强大的!
于是, request(..) 可能是以下两者之一:
1 | // promisory request(..) (参见第3章) |
最后,作为前面 run(..) 工具的一个支持 thunk 的补丁,我们还需要这样的逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 我们收到返回的thunk了吗?
else if (typeof next.value == "function") {
return new Promise( function(resolve,reject){
// 用error-first回调调用这个thunk
next.value( function(err,msg) {
if (err) {
reject( err );
}
else {
resolve( msg );
}
} );
} )
.then(
handleNext,
function handleErr(err) {
return Promise.resolve(
it.throw( err )
)
.then( handleResult );
}
);
}
现在,我们的生成器可以调用 promisory 来 yield Promise,也可以调用 thunkory 来 yield
thunk。不管哪种情况, run(..) 都能够处理这个值,并等待它的完成来恢复生成器运行。
从更大的角度来说,thunk 本身基本上没有任何可信任性和可组合性保证,而这些是Promise 的设计目标所在。
4.8 ES6 之前的生成器
对 ES6 中所有的语法扩展来说,都有工具将其翻译为等价代码。
可怎么实现呢?
显然 yield 的“魔法”看起来并不那么容易翻译。
实际上,我们之前在讨论基于闭包的迭代器时已经暗示了一种解决方案。
4.8.1 手工变换
1.先把非生成器变换的轮廓刻画出来:
1 | function foo(url) { |
2.生成器是通过暂停自己的作用域 / 状态实现它的“魔法”的。
可以通过函数闭包来模拟这一点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// request(..)是一个支持Promise的Ajax工具
function *foo(url) {
// 状态1 初始
try {
console.log( "requesting:", url );
var TMP1 = request( url );
// 状态2 成功
var val = yield TMP1;
console.log( val );
}
catch (err) {
// 状态3 失败
console.log( "Oops:", err );
return false;
}
}
1 是起始状态, 2 是 request(..) 成功后的状态, 3 是 request(..) 失败的状态。
3.把任何额外的 yield 步骤编码为更多的状态
让我们在闭包中定义一个变量 state 用于跟踪状态:
现在在闭包内定义一个内层函数,称为 process(..) ,使用 switch 语句处理每个状态:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// request(..)是一个支持Promise的Ajax工具
function foo(url) {
// 管理生成器状态
var state;
// 生成器范围变量声明
var val;
function process(v) {
switch (state) {
case 1:
console.log( "requesting:", url );
return request( url );
case 2:
val = v;
console.log( val );
return;
case 3:
var err = v;
console.log( "Oops:", err );
return false;
}
}
// ..
}
对于每个生成器级的变量声明( val ),我们都把它移动为 process(..) 外的一个 val 声明,
这样它们就可以在多个 process(..) 调用之间存活。
在状态 1 ,没有了 yield resolve(..) ,我们所做的是 return resolve(..) 。
在终止状态 2 ,没有显式的 return ,所以我们只做一个 return ,这等价于 return undefined 。
在终止状态3 ,有一个 return false ,因此就保留这一句。
4.现在需要定义迭代器函数的代码,使这些函数正确调用 process(..) :
1 | function foo(url) { |
4.8.2 自动转换
前面的 ES6 生成器到前 ES6 等价代码的手工推导练习,向我们教授了概念上生成器是如何
工作的。但是,这个变换非常复杂,并且对于代码中的其他生成器而言也是不可移植的。
这部分工作通过手工实现十分不实际,会完全抵消生成器的一切优势。
已经有可用工具:
regenerator 就是这样的一个工具(http://facebook.github.io/regenerator/)
5.程序性能
5.1 Web Worker
这是浏览器(即宿主环境)的功能,实际上和 JavaScript 语言本身几乎没什么关系。
也就是说,JavaScript 当前并没有任何支持多线程执行的功能。
程序中每一个这样的独立的多线程部分被称为一个(Web)Worker。
这种类型的并行化被称为任务并行,因为其重点在于把程序划分为多个块来并发运行。
从 JavaScript 主程序(或另一个 Worker)中,可以这样实例化一个 Worker:1
var w1 = new Worker( "http://some.url.1/mycoolworker.js" );
这个 URL 应该指向一个 JavaScript 文件的位置,这个文件将被加载到一个 Worker 中。
然后浏览器启动一个独立的线程,让这个文件在这个线程中作为独立的程序运行。
除了提供一个指向外部文件的 URL,你还可以通过提供一个 Blob URL(另外一个 HTML5 特性)创建一个在线 Worker(Inline Worker),
本质上就是一个存储在单个(二进制)值中的在线文件。
不过,Blob 已经超出了我们这里的讨论范围。
Worker 之间以及它们和主程序之间,不会共享任何作用域或资源,
那会把所有多线程编程的噩梦带到前端领域,而是通过一个基本的事件消息机制相互联系。
Worker w1 对象是一个事件侦听者和触发者,可以通过订阅它来获得这个 Worker 发出的事件以及发送事件给这个 Worker。
以下是如何侦听事件(其实就是固定的 “message” 事件):1
2
3w1.addEventListener( "message", function(evt){
// evt.data
} );
也可以发送 “message” 事件给这个 Worker:1
w1.postMessage( "something cool to say" );
在这个 Worker 内部,收发消息是完全对称的:1
2
3
4
5// "mycoolworker.js"
addEventListener( "message", function(evt){
// evt.data
} );
postMessage( "a really cool reply" );
通常由主页面应用程序创建 Worker,但若是需要的话,Worker 也可以实例化它自己的子Worker,称为 subworker。
有时候,把这样的细节委托给一个“主”Worker,由它来创建其他 Worker 处理部分任务,这样很有用。
不幸的是,到写作本书时为止,Chrome 还不支持 subworker,不过 Firefox 支持。
要在创建 Worker 的程序中终止 Worker,可以调用 Worker 对象(就像前面代码中的 w1 )上的 terminate() 。
突然终止 Worker 线程不会给它任何机会完成它的工作或者清理任何资源。这就类似于通过关闭浏览器标签页来关闭页面。
如果浏览器中有两个或多个页面(或同一页上的多个 tab !)试图从同一个文件 URL 创建 Worker,那么最终得到的实际上是完全独立的 Worker。
后面我们会简单介绍如何共享Worker。
系统能够决定可以创建多少个实际的线程 /CPU/ 核心。
没有办法预测或保证你能够访问多少个可用线程,尽管很多人假定至少可以达到 CPU/ 核心的数量。
我认为最安全的假定就是在主 UI 线程之外至少还有一个线程,就是这样。
5.1.1 Worker 环境
在 Worker 内部是无法访问主程序的任何资源的。这意味着你不能访问它的任何全局变量,也不能访问页面的 DOM 或者其他资源。记住,这是一个完全独立的线程。
但是,你可以执行网络操作(Ajax、WebSockets)以及设定定时器。
Worker 可以访问几个重要的全局变量和功能的本地复本,包括 navigator 、 location 、 JSON 和applicationCache 。
你还可以通过 importScripts(..) 向 Worker 加载额外的 JavaScript 脚本:1
2// 在Worker内部
importScripts( "foo.js", "bar.js" );
这些脚本加载是同步的。也就是说, importScripts(..) 调用会阻塞余下 Worker 的执行,直到文件加载和执行完成。
另外,已经有一些讨论涉及把
Web Worker 通常应用于哪些方面呢?
• 处理密集型数学计算
• 大数据集排序
• 数据处理(压缩、音频分析、图像处理等)
• 高流量网络通信
5.1.2 数据传递
早期的 Worker 中,唯一的选择就是把所有数据序列化到一个字符串值中。
除了双向序列化导致的速度损失之外,另一个主要的负面因素是数据需要被复制,这意味着两倍的内存使用(及其引起的垃圾收集方面的波动)。
现在已经有了一些更好的选择
方案一:
如果要传递一个对象,可以使用结构化克隆算法把这个对象复制到另一边。
这个算法非常高级,甚至可以处理要复制的对象有循环引用的情况。
这样就不用付出 to-string 和 from-string 的性能损失了,但是这种方案还是要使用双倍的内存。
IE10 及更高版本以及所有其他主流浏览器都支持这种方案。
方案二:
还有一个更好的选择,特别是对于大数据集而言,就是使用 Transferable 对象。
这时发生的是对象所有权的转移,数据本身并没有移动。
一旦你把对象传递到一个 Worker 中,在原来的位置上,它就变为空的或者是不可访问的,这样就消除了多线程编程作用域共享带来的混乱。
当然,所有权传递是可以双向进行的。
如果选择 Transferable 对象的话,其实不需要做什么。
任何实现了 Transferable 接口的数据结构就自动按照这种方式传输(Firefox 和 Chrome 都支持)。
举例来说,像 Uint8Array 这样的带类型的数组就是 Transferable。
下面是如何使用 postMessage(..)发送一个 Transferable 对象:1
2// 比如foo是一个Uint8Array
postMessage( foo.buffer, [ foo.buffer ] );
第一个参数是一个原始缓冲区,第二个是一个要传输的内容的列表。
不支持 Transferable 对象的浏览器就降级到结构化克隆,这会带来性能下降而不是彻底的功能失效。
5.1.3 共享 Worker
如果你的站点或 app 允许加载同一个页面的多个 tab(一个常见的功能),那你可能非常希望通过防止重复专用 Worker 来降低系统的资源使用。
在这一方面最常见的有限资源就是socket 网络连接,因为浏览器限制了到同一个主机的同时连接数目。
当然,限制来自于同一客户端的连接数也减轻了你的资源压力。
在这种情况下,创建一个整个站点或 app 的所有页面实例都可以共享的中心 Worker 就非常有用了。
这称为 SharedWorker ,可通过下面的方式创建(只有 Firefox 和 Chrome 支持这一功能):1
var w1 = new SharedWorker( "http://some.url.1/mycoolworker.js" );
因为共享 Worker 可以与站点的多个程序实例或多个页面连接,所以这个 Worker 需要通过某种方式来得知消息来自于哪个程序。
这个唯一标识符称为端口(port),可以类比网络socket 的端口。
因此,调用程序必须使用 Worker 的 port 对象用于通信:1
2
3w1.port.addEventListener( "message", handleMessages );
// ..
w1.port.postMessage( "something cool" );
还有,端口连接必须要初始化,形式如下:1
w1.port.start();
在共享 Worker 内部,必须要处理额外的一个事件: “connect” 。
这个事件为这个特定的连接提供了端口对象。
保持多个连接独立的最简单办法就是使用 port 上的闭包,就像下面的代码一样,
把这个链接上的事件侦听和传递定义在 “connect” 事件的处理函数内部:1
2
3
4
5
6
7
8
9
10
11
12// 在共享Worker内部
addEventListener( "connect", function(evt){
// 这个连接分配的端口
var port = evt.ports[0];
port.addEventListener( "message", function(evt){
// ..
port.postMessage( .. );
// ..
} );
// 初始化端口连接
port.start();
} );
如果有某个端口连接终止而其他端口连接仍然活跃,那么共享 Worker 不会终止。
而对专用 Worker 来说,只要到实例化它的程序的连接终止,它就会终止。
5.1.4 模拟 Web Worker
如果浏览器不支持 Worker,那么从性能的角度来说是没法模拟多线程的。
通常认为 Iframe 提供了并行环境,但是在所有的现代浏览器中,它们实际上都是和主页面运行在同一个线程中的,所以并不足以模拟并发。
JavaScript 的异步(不是并行)来自于事件循环队列,所以可使用定时器( setTimeout(..) 等)强制模拟实现异步的伪 Worker。
然后你只需要提供一个 Worker API 的封装。
Modernizr GitHub 页面上列出了一些实现,但坦白地说,它们看起来都不太好。
5.2 SIMD
单指令多数据(SIMD)是一种数据并行(data parallelism)方式,与 Web Worker 的任务
并行(task parallelism)相对,因为这里的重点实际上不再是把程序逻辑分成并行的块,而是并行处理数据的多个位。
通过 SIMD,线程不再提供并行。取而代之的是,现代 CPU 通过数字“向量”(特定类型
的数组),以及可以在所有这些数字上并行操作的指令,来提供 SIMD 功能。
这是利用低级指令级并行的底层运算。
SIMD 目前正在进行早期的标准化,很有机会进入到 JavaScript 的未来版本,比如 ES7。
SIMD JavaScript 计划向 JavaScript 代码暴露短向量类型和 API。
在支持 SIMD 的那些系统中,这些运算将会直接映射到等价的 CPU 指令,而在非 SIMD 系统中就会退化回非并行化的运算。
对于数据密集型的应用(信号分析、关于图形的矩阵运算,等等),这样的并行数学处理带来的性能收益是非常明显的!
在本书写作时,早期提案中的 API 形式类似如下:1
2
3
4
5
6
7
8var v1 = SIMD.float32x4( 3.14159, 21.0, 32.3, 55.55 );
var v2 = SIMD.float32x4( 2.1, 3.2, 4.3, 5.4 );
var v3 = SIMD.int32x4( 10, 101, 1001, 10001 );
var v4 = SIMD.int32x4( 10, 20, 30, 40 );
SIMD.float32x4.mul( v1, v2 );
// [ 6.597339, 67.2, 138.89, 299.97 ]
SIMD.int32x4.add( v3, v4 );
// [ 20, 121, 1031, 10041 ]
这里展示的是两个不同的向量数据类型,32 位浮点数和 32 位整型。可以看到,这些向量
大小恰好就是四个 32 位元素,因为这和多数当代 CPU 上支持的 SIMD 向量大小(128 位)
匹配。未来还有可能看到这些 API 的 x8 (或更大!)版本。
除了 mul() 和 add() ,很多其他运算还可以包含在内,比如 sub() 、 div() 、 abs() 、 neg() 、
sqrt() 、 reciprocal() 、 reciprocalSqrt() ( 算 术 )、 shuffle() ( 重 新 安 排 向 量 元 素 )、
and() 、 or() 、 xor() 、 not() ( 逻 辑 )、 equal() 、 greaterThan() 、 lessThan() ( 比 较 )、
shiftLeft() 、 shiftRightLogical() 、 shiftRightArithmetic() ( 移 位 )、 fromFloat32x4()
以及 fromInt32x4() (转换)。
对于可用的 SIMD 功能,有一个官方的(有希望的、值得期待的、面向未来的)prolyfill,它展示了比我们这一节中多得多的计划好的 SIMD 功能。
5.3 asm.js
asm.js这个标签是指 JavaScript 语言中可以高度优化的一个子集。
通过小心避免某些难以优化的机制和模式(垃圾收集、类型强制转换,等等),asm.js 风格的代码可以被 JavaScript 引擎识别并进行特别激进的底层优化。
asm.js 并不是 JavaScript 语言规范需要采纳的某种东西。虽然 asm.js 规范的确存在(http://asmjs,org/spec/latest/)
目前还没有提出任何新的语法。事实上,asm.js 提出了一些识别满足 asm.js 规则的现存标准 JavaScript 语法的方法,并让引擎据此实现它们自己的优化。
早期版本的 asm.js 实验需要一个 “use asm” ;
pragma(类似于严格模式的 “use strict” ;)帮助提醒JavaScript 引擎寻找 asm.js 优化机会。
另外一些人认为,asm.js 应该就是一个启发式的集合,引擎应该能够自动识别,无需开发者做任何额外的事情。
5.3.1 如何使用 asm.js 优化
关于 asm.js 优化,首先要理解的是类型和强制类型转换
JavaScript 引擎需要多个不同类型的值,才能按需处理类型之间的强制类型转换,那么这大量的额外工作会使得程序优化无法达到最优。
asm.js 通常是其他工具的编译目标,比如mscripten
可以用来向支持 asm.js 的 JavaScript 引擎暗示变量和运算想要的类型是什么使它可以省略这些类型转换跟踪步骤。1
2
3var a = 42;
// ..
var b = a;
在这个程序中,赋值 b = a 留下了变量类型二义性的后门。1
2
3var a = 42;
// ..
var b = a | 0;
这样的代码在一般的 JavaScript 引擎上都可以正常工作。
而对支持 asm.js 的JavaScript 引擎来说,这段代码就发出这样的信号, b 应该总是被当作 32 位整型来处理,这样就可以省略强制类型转换追踪。
类似地,可以这样把两个变量的加运算限制为更高效的整型加运算(而不是浮点型):1
(a + b) | 0
5.3.2 asm.js 模块
对 JavaScript 性能影响最大的因素是内存分配、垃圾收集和作用域访问。
你需要明确地导入一个严格规范的命名空间——规范将之称为stdlib因为它应该代表所需的标准库——以导入必要的符号,而不是通过词法作用域使用全局的那些符号。
基本上, window 对象就是一个 asm.js 模块可以接受的 stdlib 对象,
你还需要声明一个堆(heap)并将其传入。
这个术语用于表示内存中一块保留的位置,变量可以直接使用而不需要额外的内存请求或释放之前使用的内存。
这样,asm.js 模块就不需要任何可能导致内存扰动的动作了,只需使用预先保留的空间即可。
一个堆就像是一个带类型的 ArrayBuffer ,比如:1
var heap = new ArrayBuffer( 0x10000 ); // 64k堆
由于使用这个预留的 64k 二进制空间,asm.js 模块可以在这个缓冲区存储和获取值,不需要付出任何内存分配和垃圾收集的代价。
举例来说,可以在模块内部使用堆缓冲区备份一个 64 位浮点值数组,就像这样:1
var arr = new Float64Array( heap );
用一个简单快捷的 asm.js 风格模块例子来展示这些细节是如何结合到一起的。
我们定义了一个 foo(..)。
它接收一个起始值( x )和终止值( y )整数构成一个范围,并计算这个范围内的值的所有相邻数的乘积,然后算出这些值的平均数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34function fooASM(stdlib,foreign,heap) {
;
var arr = new stdlib.Int32Array( heap );
function foo(x,y) {
x = x | 0;
y = y | 0;
var i = 0;
var p = 0;
var sum = 0;
var count = ((y|0) - (x|0)) | 0;
// 计算所有的内部相邻数乘积
for (i = x | 0;
(i | 0) < (y | 0);
p = (p + 8) | 0, i = (i + 1) | 0
) {
// 存储结果
arr[ p >> 3 ] = (i * (i + 1)) | 0;
}
// 计算所有中间值的平均数
for (i = 0, p = 0;
(i | 0) < (count | 0);
p = (p + 8) | 0, i = (i + 1) | 0
) {
sum = (sum + arr[ p >> 3 ]) | 0;
}
return +(sum / count);
}
return {
foo: foo
};
}
var heap = new ArrayBuffer( 0x1000 );
var foo = fooASM( window, null, heap ).foo;
foo( 10, 20 ); // 233
出于展示的目的,这个 asm.js 例子是手写的,所以它并不能代表由目标为
asm.js 的编译工具产生的同样功能的代码。但是,它确实显示了 asm.js 代码
的典型特性,特别是类型提示以及堆缓冲区在存储临时变量上的使用。
asm.js 并不是对任意程序都适用的通用优化手段。它的目标是对特定的任务处理提供一种优化方法,比如数学运算(如游戏中的图形处理)。
6.性能测试与调优
第 5 章是关于宏观程序架构级的性能。这一章要讨论的主题则是微观性能,关注点在单个表达式和语句。
##6.1 性能测试
如何测试某个运算的速度,绝大多数 JavaScript 开发者都会从类似下面的代码开始:1
2
3
4var start = (new Date()).getTime(); // 或者Date.now()
// 进行一些操作
var end = (new Date()).getTime();
console.log( "Duration:", (end - start) );
不准确:
因为以更大的递增间隔更新定时器,运算的运行时间至少需要大于等于10ms(随便写的)这么长才不会被报告为 0 !
无法判断有没有受到什么影响。
你也不知道这个运算测试的环境是否过度优化了(浏览器自己进行的优化)。
6.1.1 重复
重复一个运算 100 次,然后整个循环报告共消耗了 137ms,来计算
不准确
迭代 100 次,即使只有几个(过高或过低的)的异常值也可以影响整个平均值
定时器的精度越低,你需要运行的时间就越长,这样才能确保错误率最小化。
6.1.2 Benchmark.js
任何有意义且可靠的性能测试都应该基于统计学上合理的实践。
此处并不打算撰写一章关于统计学的内容,所以我要和如下术语挥手作别:标准差、方差、误差幅度。
John-David Dalton 和 Mathias Bynens编写了一个统计学上有效的性能测试工具,名为 Benchmark.js。
还有一些很棒的文章介绍了更多的细节和方法,比如这里
(http://calendar.perfplanet.com/2010/bulletproof-javascript-benchmarks)和这里
(http://monsur.hosa.in/2012/12/11/benchmarksjs.html)。
简单展示一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14function foo() {
// 要测试的运算
}
var bench = new Benchmark(
"foo test", // 测试名称
foo, // 要测试的函数(也即内容)
{
// .. // 可选的额外选项(参见文档)
}
);
bench.hz; // 每秒运算数
bench.stats.moe; // 出错边界
bench.stats.variance; // 样本方差
// ..
setup / teardown
在前面的代码片段中,我们忽略了“额外选项” { .. } 对象。
这里有两个选项是我们应该讨论的: setup 和 teardown 。
这两个选项使你可以定义在每个测试之前和之后调用的函数。
有一点非常重要,一定要理解,setup 和 teardown 代码不会在每个测试迭代都运行。
设想你有一个像这样的测试用例:1
2a = a + "w";
b = a.charAt( 1 );
然后,你建立了测试 setup 如下:1
var a = "x";
你的目的可能是确保每个测试迭代开始的 a 值都是 “x” 。
但并不是这样!只有在每一轮测试开始时 a 值为 “x” ,然后重复 + “w” 链接运算会使得 a 值越来越长,即使你只是访问了位置 1 处的字符 “w” 。
6.2 环境为王
引擎优化
你无法可靠地推断,如果在你的独立测试中 X 比 Y 要快上 10μs,就意味着 X 总是比 Y 要快,就应该总是使用 X。
现代引擎要比我们凭直觉进行的推导复杂得多。
它们会实现各种技巧,比如跟踪记录代码在一小段时期内或针对特别有限的输入集的行为。
这是不是意味着无法真正进行任何有用的测试呢?绝对不是!
如果有实际可能的话,你应该测试实际的而非无关紧要的代码,测试条件与你期望的真实情况越接近越好。
只有这样得出的结果才有可能接近事实。
6.3 jsPerf.com
有一个很棒的网站正是因这样的需求而诞生的,名为 jsPerf(http://jsperf.com)。
它使用我们前面介绍的 Benchmark.js 库来运行统计上精确可靠的测试,并把测试结果放在一个公开可得的 URL 上,你可以把这个 URL 转发给别人。
可以通过一个技巧实现只用一个测试用例(如果需要测试单个方法的性能,
而不需要对比的话),就是在首次创建的时候在第二个测试输入框填入占位
符文字,然后编辑测试并把第二个测试清空,也就是删除了它。
你总是可以在以后增加新的测试用例。
完整性检查
公开发布的测试中有大量是有缺陷或无意义的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 用例1
var x = [];
for (var i=0; i<10; i++) {
x[i] = "x";
}
// 用例2
var x = [];
for (var i=0; i<10; i++) {
x[x.length] = "x";
}
// 用例3
var x = [];
for (var i=0; i<10; i++) {
x.push( "x" );
}
• 对开发者来说,极常见的情况是:把自己的循环放入测试用例,却忘了 Benchmark.js 已
经实现了你所需的全部重复。非常有可能这些情况下的 for 循环完全是不必要的噪音。
• 每个测试用例中 x 的声明和初始化可能是不必要的。回忆一下之前的内容,如果 x = []
放在 setup 代码中,它并不会在每个测试迭代之前实际运行,而是只在每轮测试之前运
行一次。这意味着 x 将会持续增长到非常大,而不是 for 循环中暗示的大小—— 10 。
创建一个在线函数表达式与使用预先定义好的函数对比,如果发现在线函数表达式创建版本要慢 2% ~ 20%,你会不会感到吃惊?!
更公平的测试就是将mySort(..) 的声明放在页面 setup 中
这样这个声明就不在比较最后中了
6.4 写好测试
不要试图窄化到真实代码的微小片段,以及脱离上下文而只测量这一小部分的性能,因为
包含更大(仍然有意义的)上下文时功能测试和性能测试才会更好。这些测试可能也会运
行得慢一点,这意味着环境中发现的任何差异都更有意义。
6.5 微性能
你应该习惯的第一件事情就是你所写的代码并不总是引擎真正运行的代码。
有时候编译器可能会决定执行与你所写的不同的代码,不只是顺序不同,实际内容也会不同。
编译器通常会缓存这样的查找结果
如果编译器意识到这个 foo 只在一个位置被引用而别处没有任何引用,并且注意到这个值只是 41 而从来不会变成其他值呢?
JavaScript 可能决定完全去掉 foo 变量,将其值在线化,这不是很可能发生也可以接受的1
2
3
4
5
6
7
8
9var foo = 41; // 会被撤掉
(function(){
(function(){
(function(baz){
var bar = foo + baz;
// ..
})(1);
})();
})();
另外,有些引擎会进行名为递归展开的动作,在这里,它能够意识到你表达的递归其实可以用循环更简单地实现(即优化)。
比较下面的三个 for 循环:1
2
3
4
5
6
7
8
9
10
11
12// 选择1
for (var i=0; i<10; i++) {
console.log( i );
}
// 选择2
for (var i=0; i<10; ++i) {
console.log( i );
}
// 选择3
for (var i=-1; ++i<10; ) {
console.log( i );
}
2、3并不一定就比1快
在某些像 v8 这样的引擎中,可以看到(http://mrale.ph/blog/2014/12/24/array-
length-caching.html),预先缓存长度而不是让引擎为你做这件事情,会使性能稍微
6.5.1 不是所有的引擎都类似
分析 v8 JavaScript 引擎的特定内部实现细节
如下是 v8 的一些经常提到的例子(https://github.com/petkaantonov/bluebird/wiki/Optimization-killers)。
• 不要从一个函数到另外一个函数传递 arguments 变量,因为这样的泄漏会降低函数实现
速度。
• 把 try..catch 分离到单独的函数里。
浏览器对任何有try..catch 的函数实行优化都有一些困难,所以把这部分移到独立的函数中意味着你控制了反优化的害处,并让其包含的代码可以优化。
随着时间的发展,JavaScript 引擎改变了内部管理字符串的方法,特别对 + 连接进行了优化。
它们并没有降低 join(..) 本身的效率,而是花了更多精力提高 + 的使用,因为 join仍然是广泛使用的。
随着时间的推移,那些使用数组 join(..) 来连接字符串的代码就成次优的了。
我对在我的代码中单纯根据引擎实现细节进行的广泛性能优化非常小心,特别是如果这些细节只对于单个引擎成立的话。
6.5.2 大局
首先要了解你的代码是否运行在关键路径上。
高德纳著名的一句话:“过早优化是万恶之源。”
这么解释高德纳的意思是合理的:“非关键路径上的优化是万恶之源。”
举例来说,考虑一下:一个关键路径动画循环需要把一个字符串类型转换到数字。1
2
3
4
5
6
7
8
9
10
11var x = "42"; // 需要数字42
// 选择1:让隐式类型转换自动发生
var y = x / 2;
// 选择2:使用parseInt(..)
var y = parseInt( x, 0 ) / 2;
// 选择3:使用Number(..)
var y = Number( x ) / 2;
// 选择4:使用一元运算符+
var y = +x / 2;
// 选项5:使用一元运算符|
var y = (x | 0) / 2;
parseInt(..)可以实现这个功能,但是它也做了更多的工作:它解析字符串而不是近几年进行类型转换。
6.6 尾调用优化
简单地说,尾调用就是一个出现在另一个函数“结尾”处的函数调用。
这个调用结束后就没有其余事情要做了(除了可能要返回结果值)。
举例来说,以下是一个非递归的尾调用:1
2
3
4
5
6
7
8
9
10function foo(x) {
return x;
}
function bar(y) {
return foo( y + 1 ); // 尾调用
}
function baz() {
return 1 + bar( 40 ); // 非尾调用
}
baz(); // 42
foo(y+1) 是 bar(..) 中的尾调用,因为在 foo(..) 完成后, bar(..) 也完成了,并且只需要返回 foo(..) 调用的结果。
然而, bar(40) 不是尾调用,因为在它完成后,它的结果需要加上 1 才能由 baz() 返回。
调用一个新的函数需要额外的一块预留内存来管理调用栈,称为栈帧。
所以前面的代码一般会同时需要为每个 baz() 、 bar(..) 和 foo(..) 保留一个栈帧。
如果支持 TCO 的引擎能够意识到 foo(y+1) 调用位于尾部,这意味着 bar(..) 基本上已经完成了,
那么在调用 foo(..) 时,它就不需要创建一个新的栈帧,而是可以重用已有的 bar(..) 的栈帧。
这样不仅速度更快,也更节省内存。
在简单的代码片段中,这类优化算不了什么,但是在处理递归时,这就解决了大问题,特别是如果递归可能会导致成百上千个栈帧的时候。
有了 TCO,引擎可以用同一个栈帧执行所有这类调用!
如果没有 TCO 的话,引擎需要实现一个限制来界定递归栈的深度,达到了就得停止,以防止内存耗尽。
ES6 之所以要求引擎实现 TCO 而不是将其留给引擎自由决定,
一个原因是缺乏 TCO 会导致一些 JavaScript 算法因为害怕调用栈限制而降低了通过递归实现的概率。
所以引擎缺乏 TCO不单单只是降低了性能,重要的是它会导致一些程序变得无法实现,所以成为了ES6的一个重要的语言特性。
考虑到前面递归的 factorial(..) ,这次重写成 TCO 友好的:1
2
3
4
5
6
7
8function factorial(n) {
function fact(n,res) {
if (n < 2) return res;
return fact( n - 1, n * res );
}
return fact( n, 1 );
}
factorial( 5 ); // 120