1 欢迎进入Node
1.2 异步和事件触发:浏览器
Node为服务端JavaScript提供了一个事件驱动的、异步的平台。
当浏览器中有I/O操作时,该操作会在事件轮询的外面执行(脚本执行的主顺序之外) ,然后当这个I/O操作完成时,它会发出一个“事件” ,会有一个函数(通常称作“回调” )处理它
1.3 异步和事件触发:服务器
如果IO阻塞,有更多请求过来,通常会用多线程来实现。
一种常见的实现是给每个连接分配一个线程, 并为那些连接设置一个线程池。
线程通常都是处于进程之内的,并且会维护它自己的工作内存。
每个线程会处理一到多个服务器连接。
但是程序内的线程管理非常复杂
此外,当需要大量的线程处理很多并发的服务器连接时,线程会消耗额外的操作系统资源–线程需要CPU和额外的RAM来做上下文切换。
在Node中,I/O几乎总是在主事件轮询之外进行,使得服务器可以一直处于高效并且随时能够做出响应的状态,就像NGINX一样。
1.4 DIRT程序
DIRT程序:表示数据密集型实时程序(data-intensive real-time)。
因为Node自身在I/O上非常轻量,它善于将数据从一个管道混排或代理到另一个管道上, 这能在处理大量请求时持有很多开放的连接, 并且只占用一小部分内存。它的设计目标是保证响应能力,跟浏览器一样。
所以Node擅长实时响应大量并发的用户请求
1.5 默认DIRT
Node从构建开始就有一个事件驱动和异步的模型。
Node重新实现了宿主中那些常用的对象,尽量让浏览器和服务器保持一致。
Node还有一组用来处理多种网络和文件I/O的核心模块。
其中包括用于HTTP、 TLS、 HTTPS、文件系统(POSIX) 、数据报(UDP)和NET(TCP)的模块。
1.5.1 简单的异步程序
1 | var fs = require('fs'); |
这段程序要从硬盘里读取resource.json文件。当所|有数据都读出来后,会调用那个匿名函数(即回调函数 ) ,传给它的参数是 er (如果出现错误)和 data (文件中的数据) 。
1.5.2 Hello World HTTP 服务器
1 | var http = require('http'); |
1.5.3 流数据
你可以把数据流看成特殊的数组, 只不过数组中的数据分散在空间上,而数据流中的数据是分散在时间上的。通过将数据一块一块地传送,开发人员可以每收到一块数据就开始处理,而不用等所有数据都到全了再做处理。下
下面我们用数据流的方式来处理resource.json:1
2
3
4
5
6
7var stream = fs.createReadStream('./resource.json') //创建流数据
stream.on('data', function (chunk) {
console.log(chunk)
})
stream.on('end', function () {
console.log('finished')
})
只要有新的数据块准备好,就会激发 data 事件,当所有数据块都加载完之后,会激发一个end 事件。
我们借用一下前面那个HTTP服务器,看看如何把一张图片流到客户端:1
2
3
4
5
6
7var http = require('http');
var fs = require('fs');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'image/png'});
fs.createReadStream('./image.png').pipe(res); //重点在这里呦
}).listen(3000);
console.log('Server running at http://localhost:3000/');
数据从文件中读进来fs.createReadStream ,然后数据随着进来就被送到.pipe客户端res 。
在数据流动时,事件轮询还能处理其他事件。
1.5.4 常用模块声明
1 | var http = require('http'); //内置的 http 模块提供了HTTP服务器和客户端功能 |
2 构建有多个房间的聊天室程序
2.2 程序需求及初始设置
提供静态文件就一定需要使用Node内置的http模块。
通过HTTP提供文件时,通常不能只是发送文件中的内容,还应该有所发送文件的类型。
也就是说要用正确的MIME类型设置HTTP头的 Content-Type 。
为了查找这些MIME类型,你会用到第三方的模块 mime 。
HTTP是单向通信,每次都要创建新的TCP/IP连接,而且传输数据量也比较大,所以不要用这种协议。
所以程序没用依赖于HTTP的方案,而是采用了 WebSocket,这是一个为支持实时通讯而设计的轻量的双向通信协议。
Socket.IO库,它给不能使用WebSocket的浏览器提供了一些后备措施,包括使用Flash。
Socket.IO还是事件发射器(Event Emitter)的好例子。事件发射器本质上是组织异步逻辑的一种很方便的设计模式。
事件发射器是跟某种资源相关联的, 它能向这个资源发送消息, 也能从这个资源接收消息。资源可以连接远程服务器,或者更抽象的东西,比如游戏中的角色。
程序注意点:
- 防止跨域脚本(XSS)攻击。
方法一:净化文本
将特殊字符转换成HTML实体。
例如:>转换成>
方法二:
插入text文本格式
3 Node编程基础
3.1 Node功能的组成及重用
Node模块允许你从被引入文件中选择要暴露给程序的函数和变量。
如果模块返回的函数或变量不止一个,那它可以通过设定 exports 对象的属性来指明它们。
但如果模块只返回一个函数或变量,则可以设定 module.exports 属性。
3.1.1 创建模块
模块既可能是一个文件,也可能是包含一个或多个文件的目录,如图3-3所示。
如果模块是个目录,Node通常会在这个目录下找一个叫index.js的文件作为模块的入口(这个默认设置可以重写,见3.1.4节) 。
定义一个模块:1
2
3
4
5
6//currency.js
exports.USToCanadian = function(us) {
return roundTwoDecimals(us / canadianDollar);
}
//引入
var currency = require('./currency');
require 是Node中少数几个同步I/O操作之一。
3.1.2 用module.exports微调模块的创建
用 module.exports可以对外提供单个变量、函数或者对象。
如果你创建了一个既有 exports 又有 module.exports的模块,那它会返回 module.exports ,而 exports 会被忽略。
exports 只是对 module.exports 的一个全局引用,最初被定义为一个可以添加属性的空对象 。
所以,如果把 exports 设定为别的,就打破了 module.exports 和 exports 之间的引用关系。
3.1.3 用node_modules重用模块
3.1.4 注意事项
如果模块是目录,在模块目录中定义模块的文件必须被命名为index.js,除非你在这个目录下一个叫package.json的文件里特别指明。
package.json文件里必须有一个对象,其中有一个名为 main的键,指明模块目录内主文件的路径。
3.2 异步编程技术
在Node的世界里流行两种响应逻辑管理方式:回调和事件监听。
3.2.1 用回调处理一次性事件
回调是一个函数,它被当做参数传给异步函数,它描述了异步操作完成之后要做什么。
解决回调层数多的方法:
- 改用命名函数不用匿名函数
- 减少由if/else引起的嵌套:尽早从函数中返回。
回调函数的第一个参数一般都是err或er
3.2.2 用事件发射器处理重复性事件
事件发射器会触发事件,并且在那些事件被触发时能处理它们。
3.2.2.1 事件发射器示例
1 | socket.on('data', handleData); |
socket是事件发射器
on是监听器
3.2.2.2 响应只应该发生一次的事件
用 once 方法响应单次事件
3.2.2.3 创建事件发射器:一个PUB/SUB的例子
用Node内置的事件模块创建自己的事件发射器。
1 | var EventEmitter = require('events').EventEmitter; //引入事件发射器模块 |
用事件发射器实现的简单的发布/预订系统1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25var events = require('events');
var net = require('net');
var channel = new events.EventEmitter();
channel.clients = {};
channel.subscriptions = {};
channel.on('join', function(id, client) { //添加 join 事件的监听器,保 存用户的 client 对象,以便 程序可以将数据发送给用户
this.clients[id] = client;
this.subscriptions[id] = function(senderId, message) {
if (id != senderId) { //忽略发出这一广播数据的用户
this.clients[id].write(message);
}
}
this.on('broadcast', this.subscriptions[id]); //添加一个专门针对当前用户 的 broadcast 事件监听器
});
var server = net.createServer(function (client) {
var id = client.remoteAddress + ':' + client.remotePort;
client.on('connect', function() { //都是建立在原生事件基础之上的
channel.emit('join', id, client); //当有用户连到服务器上来时发出一个 join 事件,指明用户ID和 client 对象
});
client.on('data', function(data) {
data = data.toString();
channel.emit('broadcast', id, data); //当有用户发送数据时,发出一个 频道 broadcast 事件,指明用户 ID和消息
});
});
server.listen(8888);
把聊天服务器跑起来后,在命令行中输入下面的命令进入聊天程序:1
telnet 127.0.0.1 8888
如果你打开几个命令行窗口, 在其中任何一个窗口中输入的内容都将会被发送到其他所有窗口中。
问题:在用户关闭连接离开聊天室后,原来那个监听器还在,仍会尝试向已经断开的连接写数据。
解决:把监听器添加到频道事件发射器上,并且向服务器的 close 事件监听器中添加发射频道的leave 事件的处理逻辑。
leave 事件本质上就是要移除原来给客户端添加的 broadcast 监听器。1
2
3
4
5
6
7
8
9
10
11channel.on('leave', function(id) { //创建 leave 事件的监听器
channel.removeListener('broadcast', this.subscriptions[id]); //移除指定客户端的 broadcast 监听器
channel.emit('broadcast', id, id + " has left the chat.\n");
});
var server = net.createServer(function (client) {
//...
client.on('close', function() { //都是建立在原生事件基础之上的
channel.emit('leave', id); //在用户断开连接时发出 leave事件
});
});
server.listen(8888);
改进:如果只是想停止聊天服务,但又不想关掉服务器,可以用 removeAllListeners 事件发射器方法去掉给定类型的全部监听器。1
2
3
4channel.on('shutdown', function() { //这个shutdown是自定义的,是用户命令敲的
channel.emit('broadcast', '', "Chat has shut down.\n");
channel.removeAllListeners('broadcast');
});
shutdown实现:建立在原生事件data上1
2
3
4
5
6
7client.on('data', function(data) {
data = data.toString();
if (data == "shutdown\r\n") {
channel.emit('shutdown');
}
channel.emit('broadcast', id, data);
});
现在只要有人输入 shutdown 命令,所有参与聊天的人都会被踢出去。
想查看当前有几个已链接的聊天用户,可以用下面这个监听器方法,它能根据给定的事件类型返回一个监听器数组:1
2
3
4
5channel.on('join', function(id, client) {
var welcome = "Welcome!\n"
+ 'Guests online: ' + this.listeners('broadcast').length; //this.listeners('broadcast')获取监听器数组
client.write(welcome + "\n");
}
this.listeners('broadcast')获取监听器数组channel.setMaxListeners(50)增加监听器的数量setMaxListeners(0)移除掉警告
3.2.2.4 扩展事件监听器:文件监视器
1 | function Watcher(watchDir, processedDir) { |
3.2.3 异步开发的难题
因为异步,程序的变量也可能会出现意想不到的变化。
为了保持变量,可以通过闭包来保持变量!!
3.3异步逻辑的顺序化
Node流程控制分为两类: 串行和并行,
3.3.1 什么时候使用串行流程控制
实现串行流程的方法:
方法一:嵌套回调1
2
3
4
5
6
7
8
9setTimeout(function() {
console.log('I execute first.');
setTimeout(function() {
console.log('I execute next.');
setTimeout(function() {
console.log('I execute last.');
}, 100);
}, 500);
}, 1000);
缺点:比较乱,可读性差
方法二:Nimble插件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21var flow = require('nimble');
flow.series([ //注意这里是数组[,flow.series是模块方法
function (callback) { //将所有需要同步的函数,分别放入function(callback){}中
setTimeout(function() {
console.log('I execute first.');
callback();
}, 1000);
},
function (callback) {
setTimeout(function() {
console.log('I execute next.');
callback();
}, 500);
},
function (callback) {
setTimeout(function() {
console.log('I execute last.');
callback();
}, 80);
}
]);
方法三:通过next()实现同步1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//只写了一个逻辑函数,只做说明用
function checkForRSSFile () {
fs.exists(configFilename, function(exists) {
if (!exists)
return next(new Error('Missing RSS file: ' + configFilename));
next(null, configFilename); //这里调用next() 方法
});
}
function next(err, result) {
if (err) throw err;
var currentTask = tasks.shift(); //重中之重!!这里获得数组删掉的值,此时数组变了,而且还能取到删掉的值!太棒了
if (currentTask) {
currentTask(result);
}
}
next();
3.3.3 实现并行化流程控制
场景:读取几个文本文件的内容,并输出单词在整个文件中出现的次数。
分析:异步的,分别读取文件并计数,都完成后相加!
方法一:叠加完成数,原生判断都完成再处理操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45var fs = require('fs');
var completedTasks = 0;
var tasks = [];
var wordCounts = {};
var filesDir = './text';
function checkIfComplete() {
completedTasks++;
if (completedTasks == tasks.length) { //重点!!不等于tasks.length的时候不执行,所以只有等都完成的时候,才一起统计!!
for (var index in wordCounts) {
console.log(index +': ' + wordCounts[index]);
}
}
}
function countWordsInText(text) {
var words = text
.toString()
.toLowerCase()
.split(/\W+/)
.sort();
for (var index in words) {
var word = words[index];
if (word) {
wordCounts[word] =
(wordCounts[word]) ? wordCounts[word] + 1 : 1;
}
}
}
fs.readdir(filesDir, function(err, files) {
if (err) throw err;
for(var index in files) {
var task = (function(file) {
return function() {
fs.readFile(file, function(err, text) {
if (err) throw err;
countWordsInText(text);
checkIfComplete();
});
}
})(filesDir + '/' + files[index]);
tasks.push(task);
}
for(var task in tasks) {
tasks[task]();
}
});
方法二:Nimble模块1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31var flow = require('nimble')
var exec = require('child_process').exec;
function downloadNodeVersion(version, destination, callback) {
var url = 'http://nodejs.org/dist/node-v' + version + '.tar.gz';
var filepath = destination + '/' + version + '.tgz';
exec('curl ' + url + ' >' + filepath, callback);
}
flow.series([ //模块固定方法
function (callback) { //这里是同步执行--下载
flow.parallel([ //这里是定义 异步
function (callback) { //异步1
console.log('Downloading Node v0.4.6...');
downloadNodeVersion('0.4.6', '/tmp', callback);
},
function (callback) { //异步2
console.log('Downloading Node v0.4.7...');
downloadNodeVersion('0.4.7', '/tmp', callback);
}
], callback);
},
function(callback) { //同步执行--归档
console.log('Creating archive of downloaded files...');
exec(
'tar cvf node_distros.tar /tmp/0.4.6.tgz /tmp/0.4.7.tgz',
function(error, stdout, stderr) {
console.log('All done!');
callback();
}
);
}
]);
4 构建Node Web程序
4.1 HTTP 服务器的基础知识
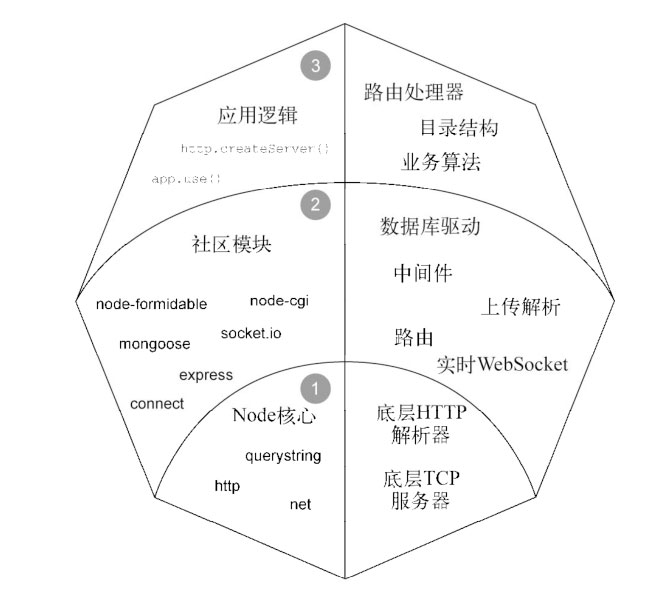
4.1.1 Node如何向开发者呈现HTTP请求
创建HTTP服务器要调用 http.createServer() 函数。
Node不会自动往客户端写任何响应。
在调用完请求回调函数之后,就要由你负责用 res.end()方法结束响应了
4.1.2 一个用“Hello World”做响应的HTTP服务器
1 | var http = require('http'); |
res.write() 和 res.end() 可以合起来缩写成一条语句1
res.end('Hello World');
4.1.3 读取请求头及设定响应头
在发送HTML内容时,必须发送一个值为 text/html 的 Content-Type 头,让浏览器知道要把响应结果作为HTML渲染。
Node提供了几个修改HTTP响应头的方法: res.setHeader(field, value)、res.getHeader(field)和 res .removeHeader(field) 。
这里有个使用 res.setHeader() 的例子:1
2
3
4var body = 'Hello World';
res.setHeader('Content-Length', body.length);
res.setHeader('Content-Type', 'text/plain');
res.end(body);
4.1.4 设定HTTP响应的状态码
设定响应码用 res.statusCode 属性。
在程序响应期间可以随时给这个属性赋值,只要是在第一次调用 res.write() 或 res.end() 之前就行。
4.2构建 RESTful Web 服务
RESTful Web服务,一个使用 HTTP方法谓词提供精简API的服务。
cURL是一个强大的命令行HTTP客户端,可以用来向目标服务器发送请求。
cURL(http://curl.haxx.se/download.html)代替Web浏览器跟Web服务交互。
选项 -d 会自动将请求方法设定为 POST ,并将参数值作为 POST 数据传入:1
$ curl -d 'buy groceries' http://localhost:3000
选项 -i 或 --include让cURL把响应头输出出来:1
$ curl http://localhost:3000/static.js -i
4.2.1 用POST请求创建资源
req.method 属性查看用的是哪个HTTP方法(谓词) -POST/GET···
data 事件会提供 Buffer 对象,这是Node版的字节数组。
而对于文本格式的待办事项而言,你并不需要二进制数据,所以最好将流编码设定为 ascii 或 utf8 ;
这样 data 事件会给出字符串。这可以通过调用 req.setEncoding(encoding) 方法设定:1
2
3
4req.setEncoding('utf8') //现在的数据块不再是 Buffer 对象,而是一个 utf8 字符串
req.on('data', function(chunk){
console.log(chunk);
});
POST请求体字符串缓存,代码示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var http = require('http');
var url = require('url');
var items = []; //用一个常规的JavaScript数组存放数据
var server = http.createServer(function(req, res){
switch (req.method) {
case 'POST':
var item = ''; //为进来的事项设置字符串缓存
req.setEncoding('utf8');
req.on('data', function(chunk){
item += chunk; //将数据块拼接到缓存上
});
req.on('end', function(){
items.push(item); //将完整的新事项压入事项数组中
res.end('OK\n');
});
break;
}
});
4.2.2 用GET请求获取资源
设定Content-Length头
为了提高响应速度,如果可能的话,应该在响应中带着 Content-Length 域一起发送。
原理:对于事项清单而言,响应主体很容易在内存中提前构建好,所以你能得到字符串的长度并一次性地将整个清单发出去。设定 Content-Length 域会隐含禁用Node的块编码,因为要传输的数据更少,所以能提升性能。
经过优化的GET可以这么写:1
2
3
4
5
6var body = items.map(function(item, i){
return i + ') ' + item;
}).join('\n');
res.setHeader('Content-Length', Buffer.byteLength(body)); //这里呦
res.setHeader('Content-Type', 'text/plain; charset="utf-8"');
res.end(body);
你可能想用 body.length 的值设定 Content-Length ,但 Content-Length 的值应该是字节长度,不是字符长度,并且如果字符串中有多字节字符,两者的长度是不一样的。为了规避这个问题,Node提供了一个 Buffer.byteLength() 方法。
Node的REPL环境(读取-计算-输出-循环):在命令行 中不带任何参数运行node就可以进入这个环境。
4.2.3 用DELETE请求移除资源
例子中用的是事项数组中的索引,比如 DELETE /1 或 DELETE /5 。
Node提供了 url 模块,特别是 .parse() 函数。
下面的REPL会话阐明了这个函数的用法,将URL解析到一个对象中,包括要用在 DELETE 处理器中的 pathname 属性。1
2
3
4
5
6
7
8
9
10
11
12
13$ node
> require('url').parse('http://localhost:3000/1?api-key=foobar')
{ protocol: 'http:',
slashes: true,
host: 'localhost:3000',
port: '3000',
hostname: 'localhost',
href: 'http://localhost:3000/1?api-key=foobar',
search: '?api-key=foobar',
query: 'api-key=foobar',
pathname: '/1',
path: '/1?api-key=foobar'
}
url.parse() 只能帮你解析出 pathname , 但事项ID仍然是字符串。
要在程序中使用这个ID,应该把它转换成数字。
简单的做法是用 String.slice(),不过它的返回结果还是字符串,不过可以通过 parseInt()转为数字。
4.3 提供静态文件服务
创建一个简单的静态文件服务器;
用 pipe() 优化数据传输;
通过设定状态码处理用户和文件系统错误。
4.3.1 创建一个静态文件服务器
__dirname 在Node中是一个神奇的变量,它的值是该文件所在目录的路径。
有了文件的路径,还需要传输文件的内容。
这可以用高层流式硬盘访问 fs.ReadStream 完成,它是Node中 Stream 类之一。
最基本的ReadStream静态文件服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var http = require('http');
var parse = require('url').parse;
var join = require('path').join;
var fs = require('fs');
var root = __dirname;
var server = http.createServer(function(req, res){
var url = parse(req.url);
var path = join(root, url.pathname); //构造绝对路径
var stream = fs.createReadStream(path); //创建fs.ReadStream
stream.on('data', function(chunk){ //将文件数据写到响应中
res.write(chunk);
});
stream.on('end', function(){
res.end(); //文件写完后结束响应
});
});
server.listen(3000);
用 STREAM.PIPE() 优化数据传输
用法:1
ReadableStream#pipe(WritableStream);
读取一个文件(ReadableStream)并把其中的内容写到另一个文件中(WritableStream)用的就是管道:1
2
3var readStream = fs.createReadStream('./original.txt')
var writeStream = fs.createWriteStream('./copy.txt')
readStream.pipe(writeStream);
并且:res.end() 会在 stream.pipe() `内部调用1
2
3
4
5
6var server = http.createServer(function(req, res){
var url = parse(req.url);
var path = join(root, url.pathname);
var stream = fs.createReadStream(path);
stream.pipe(res);
});
但是,一个未处理的异常,比如用户请求了一个不存在的文件,就会把整个服务器拖垮。
4.3.2 处理服务器错误
在Node中,所有继承了 EventEmitter 的类都可能会发出 error 事件。
为了防止服务器被错误搞垮,我们要监听错误,在 fs.ReadStream 上注册一个 error 事件处理器(比如下面这段代码) ,返回响应状态码500表明有服务器内部错误:1
2
3
4
5stream.pipe(res);
stream.on('error', function(err){
res.statusCode = 500;
res.end('Internal Server Error');
});
4.3.3 用 fs.stat() 实现先发制人的错误处理
可以用 stat() 系统调用获取文件的相关信息,比如修改时间、字节数等。
在提供条件式 GET 支持时,这些信息特别重要,浏览器可以发起请求检查它的缓存是否过期了。
调用了 fs.stat() 用于得到文件的相关信息,比如它的大小,或者得到错误码。
如果文件不存在, fs.stat() 会在 err.code 中放入 ENOENT作为响应,然后你可以返回错误码404,向客户端表明文件未找到。
如果 fs.stat() 返回了其他错误码,你可以返回通用的错误码500。
例:检查文件是否存在,并在响应中提供Content-Length1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23var server = http.createServer(function(req, res){
var url = parse(req.url);
var path = join(root, url.pathname);
fs.stat(path, function(err, stat){
if (err) {
if ('ENOENT' == err.code) { //检查文件是否存在
res.statusCode = 404;
res.end('Not Found');
} else {
res.statusCode = 500;
res.end('Internal Server Error');
}
} else {
res.setHeader('Content-Length', stat.size); //用 stat 对象的属性设置Content-Length
var stream = fs.createReadStream(path);
stream.pipe(res);
stream.on('error', function(err){
res.statusCode = 500;
res.end('Internal Server Error');
});
}
});
});
4.4 从表单中接受用户输入
4.4.1 处理提交的表单域
表单提交请求带的 Content-Type 值通常有两种:
application/x-www-form-urlencoded :这是HTML表单的默认值;
multipart/form-data :在表单中含有文件或非ASCII或二进制数据时使用。(适用于BLOB(大型二进制文件)的MIME类型。)
例如:支持GET和POST的HTTP服务器–简单的路由原理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var http = require('http');
var items = [];
var server = http.createServer(function(req, res){
if ('/' == req.url) {
switch (req.method) {
case 'GET':
show(res);
break;
case 'POST':
add(req, res);
break;
default:
badRequest(res);
}
} else {
notFound(res);
}
});
server.listen(3000);
因为默认的响应状态就是200 OK,所以这里没必要给 res.statusCode 赋值。
querystring模块
了解下Node服务器中用到的这个 querystring.parse() 函数是如何解析请求主体的。1
2
3
4
5$ node
> var qs = require('querystring');
> var body = 'item=take+ferrets+to+the+vet';
> qs.parse(body);
{ item: 'take ferrets to the vet' }
4.4.2 用formidable处理上传的文件
文件上传完成后发出了 file 事件。
在收到文件并处理好后会发出 file 事件,收完输入域后会发出 field 事件。
file 对象为你提供了文件大小,在 form.uploadDir 目录(默认为/tmp)中的路径,原始的主档名,以及MIME类型。
当传到 console.log() 中时, file 对象如下所示:1
2
3
4
5
6
7
8
9
10{ size: 28638,
path: '/tmp/d870ede4d01507a68427a3364204cdf3',
name: 'clock.png',
type: 'image/png',
lastModifiedDate: Sun, 05 Jun 2011 02:32:10 GMT,
length: [Getter],
filename: [Getter],
mime: [Getter],
...
}
如果没有错误,就会传入后面的两个对象: fields 和 files 。
fields 对象看起来就像 console.log() 的下面这种输出:{ name: ‘my clock’ }
files 对象跟 file 事件中的 File 实例一样,像 fields 那样以名称为键。
下面这段代码展示了如何使用这个更精简的API得到我们前面已经讨论过的结果:1
2
3
4
5
6var form = new formidable.IncomingForm();
form.parse(req, function(err, fields, files){
console.log(fields); //直接打印这个对象
console.log(files); //直接打印这个对象
res.end('upload complete!');
});
4.4.3 计算上传进度
Formidable的 progress 事件能给出收到的字节数,以及期望收到的字节数。1
2
3
4form.on('progress', function(bytesReceived, bytesExpected){ //收到字节,期望字节
var percent = Math.floor(bytesReceived / bytesExpected * 100);
console.log(percent);
});
4.5 用 HTTPS 加强程序的安全性
HTTPS将HTTP和TLS/SSL传输层结合到一起。
如果你想在你的Node程序里使用HTTPS,第一件事就是取得一个私钥和一份证书。
私钥本质上是个“秘钥” ,可以用它来解密客户端发给服务器的数据。
私钥保存在服务器上的一个文件里,放在一个不可信用户无法轻易访问到的地方。
生成私钥需要OpenSSL,在装Node时就已经装过了。
打开命令行窗口,输入下面的命令会生成一个名为key.pem的私钥文件:1
openssl genrsa 1024 > key.pem
秘钥通常都是放在 ~/.ssh。
除了私钥,你还需要一份证书。证书跟私钥不同,可以与全世界分享,它包含了公钥和证书持有者的信息。
公钥用来加密从客户端发往服务器的数据。
创建证书需要私钥。输入下面的命令会生成名为key-cert.pem的证书:1
openssl req -x509 -new -key key.pem > key-cert.pem
HTTPS服务器配置项1
2
3
4
5
6
7
8
9
10var https = require('https');
var fs = require('fs');
var options = {
key: fs.readFileSync('./key.pem'), //作为配置项的SSL秘钥和证书
cert: fs.readFileSync('./key-cert.pem') //作为配置项的SSL秘钥和证书
};
https.createServer(options, function (req, res) { //第一个传入的就是配置项对象
res.writeHead(200);
res.end("hello world\n");
}).listen(3000);
5 存储Node程序中的数据
三种不同存储:
内存存储和文件存储
用关系型数据库存储数据,具体说就是MySQL和PostgreSQL;
用NoSQL数据库存储数据,具体说就是Redis、MongoDB和Mongoose。
5.1 无服务器的数据存储
5.1.1 内存存储
内存存储用变量存放数据。
这种数据的读取和写入都很快,但重启后丢失!1
2
3
4
5
6
7var http = require('http');
var counter = 0; //内存存储-存储在变量内
var server = http.createServer(function(req, res) {
counter++;
res.write('I have been accessed ' + counter + ' times.');
res.end();
}).listen(8888);
5.1.2 基于文件的存储
用文件系统存放数据,支持持久化保存,重启不丢失。
并发问题
两个用户可能会同时加载相同的文件进行修改。
保存一个版本会覆盖另外一个,导致其中某个用户的修改丢失。
在保存之前,任务会被转换成JSON格式,从文件中读出来时再从JSON格式转回来。
5.1.2.1 编写启动逻辑
解析来自命令行参数的任务命令和描述,并指明用来保存任务的文件。
代码:收集参数值并解析文件数据库的路径1
2
3
4
5
6var fs = require('fs');
var path = require('path');
var args = process.argv.splice(2);
var command = args.shift(); //取出第一个参数(命令)
var taskDescription = args.join(' '); //合并剩余的参数为字符串
var file = path.join(process.cwd(), '/.tasks'); //process.cwd() 为当前工作目录
代码:确定CLI脚本应该采取什么动作–如果没提供参数,则会显示用法帮助。1
2
3
4
5
6
7
8
9
10
11switch (command) {
case 'list': //'list' 会列出所有已保存的任务
listTasks(file);
break;
case 'add': //'add' 会添加新任务
addTask(file, taskDescription);
break;
default: //其他任何参数都会显示帮助
console.log('Usage: ' + process.argv[0]
+ ' list|add [taskDescription]');
}
5.1.2.2 定义获取任务的辅助函数 -读取
loadOrInitializeTaskArray–辅助函数 ,用来获取已有的任务。
loadOrInitializeTaskArray 会从一个文本文件中加载编码为JSON格式的数据。
代码中用到了fs模块中的两个异步函数。
代码:从文本文件中加载用JSON编码的数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function loadOrInitializeTaskArray(file, cb) {
fs.exists(file, function(exists) {
var tasks = [];
if (exists) {
fs.readFile(file, 'utf8', function(err, data) { //从.tasks文件中读取待办事项数据
if (err) throw err;
var data = data.toString();
var tasks = JSON.parse(data || '[]'); //把用JSON编码的待办事项数据解析到任务对象中
cb(tasks);
});
} else {
cb([]); //如果.tasks文件不存在,则创建空的任务数组
}
});
}
任务函数:会调用上边的loadOrInitializeTaskArray函数1
2
3
4
5
6
7function listTasks(file) {
loadOrInitializeTaskArray(file, function(tasks) {
for(var i in tasks) { //循环任务列表并打印
console.log(tasks[i]);
}
});
}
5.1.2.3 定义一个存放任务的辅助函数 -存储
代码:把任务保存到磁盘中1
2
3
4
5
6function storeTasks(file, tasks) {
fs.writeFile(file, JSON.stringify(tasks), 'utf8', function(err) {
if (err) throw err;
console.log('Saved.');
});
}
代码:添加一项任务1
2
3
4
5
6function addTask(file, taskDescription) {
loadOrInitializeTaskArray(file, function(tasks) {
tasks.push(taskDescription);
storeTasks(file, tasks);
});
}
5.2 关系型数据库管理系统
MySQL和PostgreSQL,这是两个最流行的全功能关系型数据库。
暂时略过···用时回来补
5.3 NoSQL 数据库 (非关系型)
5.3.1 Redis
Redis把数据存在RAM中,并在磁盘中记录数据的变化。
常用的数据结构:哈希表、链表、键/值对(作为简单的变量使用)、集合(set) 。

Redis API模块是Matt Ranney的node_redis(https://github.com/mranney/node_redis) 。
用下面这条npm命令安装它:1
npm install redis
5.3.1.1 连接Redis服务器
1 | var redis = require('redis'); |
5.3.1.2 操作Redis中的数据
设置和获取存储1
2
3
4
5client.set('color', 'red', redis.print); //print 函数输出操 作的结果,或在出错时输出错误。
client.get('color', function(err, value) {
if (err) throw err;
console.log('Got: ' + value);
});
5.3.1.3 用哈希表存储和获取数据
哈希表,也被称为哈希映射!hmset 设定哈希表中的元素,用键标识值。hkeys 列出哈希表中所有元素的键。hget 获取特定键的值
代码:在Redis哈希表元素中存放数据1
2
3
4
5
6
7
8
9
10
11
12
13
14client.hmset('camping', { //设定哈希表元素
'shelter': '2-person tent',
'cooking': 'campstove'
}, redis.print);
client.hget('camping', 'cooking', function(err, value) { //获取元素 "cooking" 的值
if (err) throw err;
console.log('Will be cooking with: ' + value);
});
client.hkeys('camping', function(err, keys) { //获取哈希表的键
if (err) throw err;
keys.forEach(function(key, i) {
console.log(' ' + key);
});
});
5.3.1.4 用链表存储和获取数据
链表是Redis支持的另一种数据结构。如果内存足够大,Redis链表理论上可以存放40多亿条元素。
省略···
5.3.1.5 用集合存储和获取数据
Redis集合是一组无序的字符串组。
省略···
5.3.1.6 用信道传递数据
Redis超越了数据存储的传统职责,它提供的信道是无价之宝。
信道是数据传递机制,提供了发布/预定功能,对于聊天和游戏程序来说,它们很实用。
Redis客户端可以向任一给定的信道预订或发布消息。
预订一个信道意味着你会收到所有发送给它的消息。
发布给信道的消息会发送给所有预订了那个信道的客户端。
1 | var net = require('net'); |
5.3.1.7 NODE_REDIS性能最大化
hiredis模块(https://github.com/pietern/hiredis-node)
这个模块会显著提升Redis的性能
如果你装了hiredis,node_redis API会自动使用hiredis替代它的JavaScript实现。1
2npm install hiredis
npm rebuild hiredis //重新编译hiredis
5.3.2 MongoDB
MongoDB是一个通用的非关系型数据库,使用RDBMS的那类程序都可以使用MongoDB。
MongoDB数据库把文档存在集合(collection)中。集合中的文档,如图所示
MongoDB API模块是Christian Amor Kvalheim的 node-mongodb-native1
npm install mongodb

5.3.2.1 连接MongoDB
1 | var mongodb = require('mongodb'); |
原生的方法还有:增删减等等操作,暂时省略,我们直接用Mongoose来操作
5.3.3 Mongoose
本节会把Mongoose的基础知识过一遍,包括如何:
打开或关闭MongoDB连接 ;
注册schema;
添加任务;
搜索文档;
更新文档;
删除文档。
首先,你可以用下面这条npm命令安装Mongoose:1
npm install mongoose
5.3.3.1 连接的打开和关闭
启动MongoDB服务器并连接tasks的数据库1
2var mongoose = require('mongoose');
var db = mongoose.connect('mongodb://localhost/tasks');
终止Mongoose创建的连接1
mongoose.disconnect();
5.3.3.2 注册schema
定义结构用的1
2
3
4
5
6var Schema = mongoose.Schema;
var Tasks = new Schema({
project: String,
description: String
});
mongoose.model('Task', Tasks); //设置数据结构
Mongoose的schema很强大。除了定义数据结构,还可以设定默认值,处理输入,以及加强校验。
5.3.3.3 添加任务
1 | var Task = mongoose.model('Task'); |
5.3.3.4 搜索文档
Task模型的 find 方法可以用来查找所有文档,或者用一个JavaScript对象指明过滤标准来选择特定的文档。
下面这段代码搜索跟特定项目相关的任务, 并输出每项任务的唯一ID和描述:1
2
3
4
5
6
7var Task = mongoose.model('Task');
Task.find({'project': 'Bikeshed'}, function(err, tasks) {
for (var i = 0; i < tasks.length; i++) {
console.log('ID:' + tasks[i]._id); //_id 唯一的ID 是自动添加的
console.log(tasks[i].description);
}
});
5.3.3.5 更新文档
尽管用模型的 find 方法可以定位一个文档,然后修改并保存它,但Mongoose还有一个update 方法专门来做这个。1
2
3
4
5
6
7
8
9
10var Task = mongoose.model('Task');
Task.update(
{_id: '4e65b793d0cf5ca508000001'}, //用内部ID更新
{description: 'Paint the bikeshed green.'},
{multi: false}, //只更新一个文档
function(err, rows_updated) {
if (err) throw err;
console.log('Updated.');
}
);
5.3.3.6 删除文档
你可以用文档的内部ID(或其他任何条件,如果你用 find 代替 findById 的话)获取和删除文档,代码就像下面这样:1
2
3
4var Task = mongoose.model('Task');
Task.findById('4e65b3dce1592f7d08000001', function(err, task) {
task.remove(); //删除它
});
6 Connect
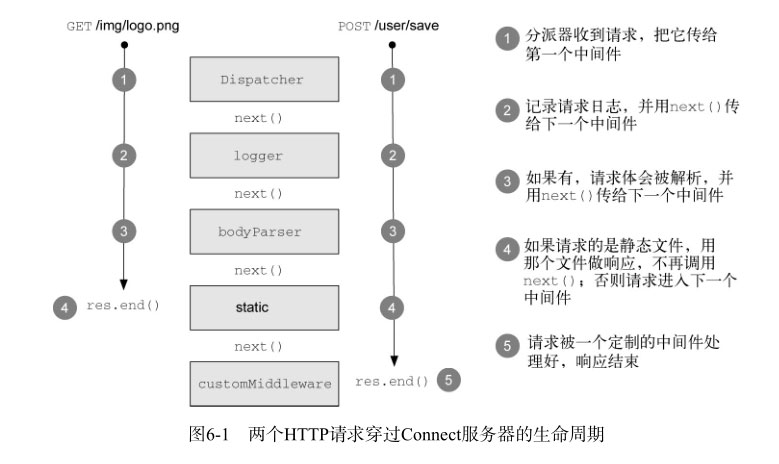
Express框架是构建在Connect上的扩展,添加了更多高层的糖衣。
Connect是第三方模块,所以它不在Node的默认安装之列。你可以用下面的命令从npm注册
中心下载Connect并安装它:1
$ npm install connect
代码清单6-1 最小的Connect程序
1 | var connect = require('connect'); |
这个裸程序没有中间件,所以分派器会用404 Not Found状态码响应它收到的所有HTTP请求。
6.2 Connect 的工作机制
在Connect中,中间件组件是一个JavaScript函数,按惯例会接受三个参数:一个请求对象,一个响应对象,还有一个通常命名为 next 的参数,
它是一个回调函数,表明这个组件已经完成了它的工作,可以执行下一个中间件组件了。
6.2.1 做日志的中间件
next 函数可以在中间件里调用,告诉分派器这个中间件已经完成了自己的任务,可以把控制权交给下一个中间件组件了。
用回调函数,而不是从方法中返回,是为了可以在中间件组件里运行异步逻辑,这样分派器就只能等着前一个中间件组件完成后才会进入下一个中间件组件。
用next() 处理中间件组件之间的流程是不错的机制。next() 将控制权交给分派器。
要在程序中使用这个中间件,你可以调用. use() 方法,把中间件函数传给它:
简单日志中间件
1 | function logger(req, res, next) { |
使用多个中间组件1
2
3
4connect()
.use(logger)
.use(hello)
.listen(3000);
. use()的链式调用不是必须的1
2
3
4
5//可写成
var app = connect();
app.use(logger);
app.use(hello);
app.listen(3000);
6.3 为什么中间件的顺序很重要
6.4 挂载中间件和服务器
Connect中有一个挂载的概念,这是一个简单而强大的组织工具,可以给中间件或整个程序定义一个路径前缀。
代码清单6-5 Connect中挂载中间件组件或服务器的语法
1 | var connect = require('connect'); |
6.4.1 认证中间件
只有请求URL以/ admin 开始时,才会调用它.
代码清单6-6实现了简陋的Basic认证逻辑。
Basic认证是一种简单的认证机制,借助带着Base64编码认证信息的HTTP请求头中的authorization字段进行认证。
代码清单6-6 实现HTTP Basic认证的中间件组件
1 | function restrict(req, res, next) { |
6.4.2 显示管理面板的中间件
中间件组件 admin 在请求URL上用 switch 语句做了一个原始的路由器。
当用户请求 / 时,admin 组件会显示一条转发消息,
请求 /users 时,它会返回一个包含用户名的JSON数组。
代码清单6-7 路由 admin 请求
1 | function admin(req, res, next) { |
这里要注意的是 case 中用的是字符串,是 / 和 /users ,而不是 /admin 和 /admin/users 。
这是因为在调用中间件之前,Connect从 req.url 中去掉了前缀,就像URL挂载在/上一样。
可以让博客程序的URL从http://foo.com/blog上迁移到http://bar.com/posts上。1
2
3
4
5
6
7var connect = require('connect');
connect()
.use(logger)
.use('/blog', blog)
.use('/posts', blog)
.use(hello)
.listen(3000);
6.5 创建可配置中间件
用函数返回另一个函数(这是一个强大的JavaScript特性,通常称为闭包)
基本结构:1
2
3
4
5
6
7
8
9
10function setup(options) {
// 设置逻辑
//在这里做中间件的初始化
return function(req, res, next) {
// 中间件逻辑
//即使被外部函数返回了,仍然可以访问 options
}
}
用法:1
app.use(setup({some: 'options'}))
6.5.1 创建可配置的 logger 中间件组件
代码清单6-8 可配置的Connect中间件组件 logger
最后结果:1
2
3var app = connect()
.use(logger(':method :url'))
.use(hello);
代码:1
2
3
4
5
6
7
8
9
10
11function setup(format) { //setup 函数可以用不 同的配置调用多次
var regexp = /:(\w+)/g; //logger组件用正则表达式匹配请求属性
return function logger(req, res, next) { //Connect使用的真 实 logger 组件
var str = format.replace(regexp, function(match, property){ //用正则表达式格式化请求的日志条目
return req[property];
});
console.log(str);
next();
}
}
module.exports = setup;
6.5.2 构建路由中间件组件
先看看怎么使用以后做的 router 中间组件
1 | //用法 |
路由中间件实现原理
1 | var parse = require('url').parse; |
6.5.3 构建一个重写URL的中间件组件
将URL转换成/blog/ posts/
这个任务特别适合中间件!
基于缩略名重写请求URL的中间件
1 | var path = url.parse(req.url).pathname; |
6.6 使用错误处理中间件
6.6.1 Connect的默认错误处理器
看一下下面这个中间件组件,因为函数foo()没有定义,所以它会抛出错误ReferenceError:1
2
3
4
5
6
7
8var connect = require('connect')
connect()
.use(function hello(req, res) {
foo();
res.setHeader('Content-Type', 'text/plain');
res.end('hello world');
})
.listen(3000)
默认情况下,Connect给出的响应是状态码500,包含文本“Internal Server Error”以及错误自身详细信息的响应主体。
6.6.2 自行处理程序错误
错误处理中间件函数必须接受四个参数: err 、 req 、 res 和 next1
2
3
4
5
6
7
8
9
10
11
12
13
14function errorHandler() {
var env = process.env.NODE_ENV || 'development';
return function(err, req, res, next) { //错误处理中间件定义四个参数
res.statusCode = 500;
switch (env) { //errorHandler中间件组 件根据 NODE_ENV 的值 执行不同的操作
case 'development':
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify(err));
break;
default:
res.end('Server error');
}
}
}
用 NODE_ENV 设定程序的模式 Connect通常是用环境变量
NODE_ENV ( process.env.NODE_ENV )在不同的服务器环境之间切换,比如生产和开发环境。
6.6.3 使用多个错误处理中间件组件–不同的组件处理不同的错误
比较多,略过···
7 Connect自带的中间件
Connect中间件快速参考指南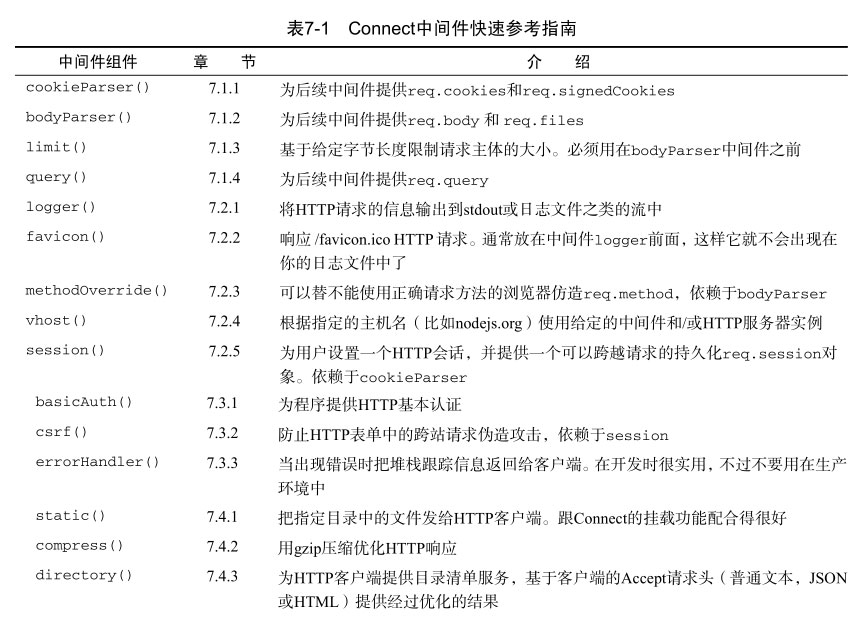
8 Express
8.1 生成程序骨架
https://codepen.io/oslego/pen/XdvWmd?from=singlemessage
最小的Express程序
1 | var express = require('express'); |
8.1.1 安装Express的可执行程序
1 | $ npm install -g express |
--help 标记看看可用的选项
8.1.2 生成程序
要使用EJS模板引擎,需要指定 -e (或 –ejs )标记,执行1
2
3
4express -e photo
//补 4.0版本需要安装express-generator才能生成程序了
npm install -g express-generator
express -e photo
8.2 配置 Express 和你的程序
Express有一个极简的环境驱动配置系统,由5个方法组成,全部由环境变量 NODE_ENV 驱动:
app.configure()
app.set()
app.get()
app.enable()
app.disable()
设置环境变量
要在UNIX中设置环境变量,可以用这个命令:1
$ NODE_ENV=production node app
在Windows中用这个:1
2$ set NODE_ENV=production
$ node app
这些环境变量会出现在你程序里的 process.env 对象中。
跨平台设置NODE_ENV
1 | cross-env NODE_ENV=development |
基于环境的配置
尽管环境变量 NODE_ENV 源自Express, 但现在很多Node框架都用它通知Node程序它在什么环境中,默认为开发环境。app.configure() 方法接受一个表示环境的可选字符串,以及一个函数。
用 app.configure() 设定特定环境的选项
1 | app.configure(function(){ |
原生代码实现1
2
3
4
5
6
7var env = process.env.NODE_ENV || 'development'; //默认为“development”
app.set('views', __dirname + '/views');
app.set('view engine', 'ejs'); //所有环境
...
if ('development' == env) { //仅开发环境,用if语句 代替 app.configure
app.use(express.errorHandler());
}
8.3 渲染视图
process.cwd() 当前工作目录__dirname 当前运行的文件所在的目录
8.4 处理表单和文件上传 ★★★★★
实现照片上传功能总共分三步:
定义照片模型;
创建照片上传表单;
显示照片列表。
8.5 创建资源下载 ★★★★★
Express进阶
这个程序允许人们注册,提交公开的消息,按发布时间逆序呈现给访问者观看。
认证用户;
实现校验和分页;
提供一个公开表述性状态转移(REST)API,以发送和接收消息。
9.1 认证用户
9.2 先进的路由技术
9.3 创建一个公开的 REST API
9.4 错误处理
10 测试Node程序
自动化测试:
单元测试→TDD:测试驱动开发
单元测试→BDD:行为驱动开发
验收测试:
用脚本控制浏览器,并试图用它触发Web程序的功能。
10.1 单元测试
框架:
Node内置的assert模块 TDD风格自动化测试的好工具;
nodeunit 长期以来都能得到Node社区喜爱的TDD风格测试工具;
Mocha 相对比较新的测试框架,可以用来做TDD-或BDD-风格的测试;
Vows 得到广泛应用的BDD风格测试工具;
should.js 构建在Node assert模块之上的模块,提供BDD风格的断言。
10.1.1 assert模块
大多数的Node单元测试都是基于内置的assert模块
10.1.1.1 一个简单的例子
10.1.1.2 用equal测试变量的内容
equal 是assert模块中用的最多的断言,它判断变量的内容是否确实等于第二个参数指定的值。1
2
3
4
5
6
7
8
9
10
11
12var assert = require('assert');
var Todo = require('./todo');
var todo = new Todo();
var testsCompleted = 0;
function deleteTest () {
todo.add('Delete Me'); //添加一些数据以便测试删除
assert.equal(todo.getCount(), 1, '1 item should exist'); //重点:断言数据被正确添加
todo.deleteAll();
assert.equal(todo.getCount(), 0, 'No items should exist');
testsCompleted++;
}
10.1.1.3 用notEqual找出逻辑中的问题
1 | function addTest () { |
10.1.1.4 使用增加的功能: strictEqual、 notStrictEqual、 DEEPEQUAL、 NOTDEEPEQUAL
assert模块还提供了这两个断言的严格版本: strictEqual 和notStrictEqual 。它们使用严格的相等操作符=== ,而不是更随和的==。
为了比较对象, assert模块提供了 deepEqual 和 notDeepEqual 。
这些断言名称中的deep表明它们会递归地比较两个对象,比较两个对象的属性,如果属性也是对象,则会继续比较属性的属性。
10.1.1.5 用OK测试异步值是否为TRUE
1 | //测试看 doAsync 回调传入的是否为 true |
10.1.1.6 测试能否正确抛出错误
throws 语句中 的第二个参数是一个正则表达式,在错误消息中查找文本“ requires ” 。1
2
3
4
5//测试看缺少参数时add是否会抛出错误
function throwsTest (cb) {
assert.throws(todo.add, /requires/);
testsCompleted++
}
10.1.3 Mocha
尽管Mocha是BDD风格的,但你也可以把它用在TDD风格的测试中。
Mocha的功能多种多样,包括全局变量泄漏检测
如果你想禁用全局泄漏检测,可以带着 --ignored-leaks 选项运行mocha命令。
此外,如果你想指明要用的几个全局变量,可以把它们放在 --globals 选项后面,用逗号分开
Mocha测试默认使用BDD风格的函数定义和设置,这些函数包括 describe 、 it 、 before 、after 、 beforeEach 和 afterEach 。
另外你也可以用Mocha的TDD接口,用 suite 代替了describe , test 代替 it , setup 代替 before , teardown 代替 after 。
不过在我们的例子中用的还是默认的BDD接口。
10.1.3.1 用Mocha测试Node程序
1 | $ npm install -g mocha |
- Mocha测试的基本结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//BDD风格
var memdb = require('..');
describe('memdb', function(){
describe('.save(doc)', function(){
it('should save the document', function(){
});
});
});
//TDD风格
module.exports = {
'memdb': {
'.save(doc)': {
'should save the document': function(){
}
}
}
}
例子:测试memdb.save功能1
2
3
4
5
6
7
8
9
10
11
12var memdb = require('..'); //要测试的文件是当前目录下的index.js文件
var assert = require('assert');
describe('memdb', function(){ //描述memdb 功能 *1
describe('.save(doc)', function(){ //描述 .save() 方法的功能
it('should save the document', function(){ //期望值 *2
var pet = { name: 'Tobi' };
memdb.save(pet);
var ret = memdb.first({ name: 'Tobi' });
assert(ret == pet); //确保找到了pet *3
})
})
})
因为没有定义.save()方法,所以报错
用Mocha挂钩定义设置和清理逻辑
Mocha挂钩: 比如说,BDD风格的接口有 beforeEach() 、 afterEach() 、 before() 和 after() ,它们接受 回调,你可以在 describe() 定义的测试用例、测试集之前和之后定义设置和清理逻辑。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31var memdb = require('..');
var assert = require('assert');
describe('memdb', function(){
beforeEach(function(){ //在每个测试用例之前都要清理数据库,保持测试的无状态性
memdb.clear();
})
describe('.save(doc)', function(){
it('should save the document', function(){
var pet = { name: 'Tobi' };
memdb.save(pet);
var ret = memdb.first({ name: 'Tobi' });
assert(ret == pet);
})
})
describe('.first(obj)', function(){
it('should return the first matching doc', function(){
var tobi = { name: 'Tobi' };
var loki = { name: 'Loki' };
memdb.save(tobi);
memdb.save(loki);
var ret = memdb.first({ name: 'Tobi' });
assert(ret == tobi);
var ret = memdb.first({ name: 'Loki' });
assert(ret == loki);
})
it('should return null when no doc matches', function(){
var ret = memdb.first({ name: 'Manny' });
assert(ret == null);
})
})
})测试异步逻辑
要测试的代码:1
2
3
4
5
6
7
8exports.save = function(doc, cb){
db.push(doc);
if (cb) {
setTimeout(function() {
cb();
}, 1000);
}
};
只要给定义测试逻辑的函数添加一个参数,就可以把Mocha测试用例定义为异步的。这个参数通常被命名为 done 。1
2
3
4
5
6
7
8
9
10describe('.save(doc)', function(){
it('should save the document', function(done){ //传入done
var pet = { name: 'Tobi' };
memdb.save(pet, function(){
var ret = memdb.first({ name: 'Tobi' });
assert(ret == pet); //断言文档正确保存了
done(); //告诉Mocha你已经完成这个测试用例了
});
});
});
Mocha一个接一个地执行测试,而不是并行执行,这样会使得测试包执行得更慢,但编写起来更容易。
不过Mocha不会让任何测试运行的时间过长,它默认只让测试运行2000毫秒,超过这个时长的测试就会失败。
如果你有运行时间更长的测试,可以带着 --timeout 选项运行Mocha,给它指定一个更大的数值。
BDD风格和验收测试用到的时候再更新····
11 Web程序模板
11.2 嵌入 JavaScript 的模板 –EJS
11.2.1 创建模板
下面这个 简单的Node程序使用EJS把上下文渲染到一个简单的模板中:1
2
3
4var ejs = require('ejs');
var template = '<%= message %>';
var context = {message: 'Hello template!'};
console.log(ejs.render(template, {locals: context})); //render第二个参数locals,包含渲染选项以及上下文数据
render 的第二个参数, 一定不要给上下文中的值用这些名称: cache 、 client 、 close 、 compileDebug 、 debug 、 filename 、 open 或 scope 。它们是 可以修改模板引擎设定的保留字。
字符转义
EJS会转义上下文值中的所有特殊字符,将它们替换为HTML实体码。
这是为了防止跨站脚本(XSS)攻击
例子:1
2
3
4
5
6var ejs = require('ejs');
var template = '<%= message %>';
var context = {message: "<script>alert('XSS attack!');</script>"};
console.log(ejs.render(template, context));
// 转移后就是下边这样
<script>alert('XSS attack!');</script>
不想转义可以用 <%- 代替 <%=
11.2.2 用EJS过滤器处理模板数据
为了表明你正在用过滤器,要在EJS的开始标签中添加一个冒号( : ) 。
例如:
<%=: 是用在转义的EJS输出上的过滤器。
<%-: 是用在非转义的EJS输出上的过滤器。
11.2.2.1 处理选择的过滤器
last 过滤器的功能就是只取出数组的最后一项first 数组的第一个get得到列表中的指定条目.例:<%=: movies | get:1 %>1
2
3
4
5
6
7
8var ejs = require('ejs');
var template = '<%=: movies | last %>'; //最后一个
var context = {'movies': [
'Bambi',
'Babe: Pig in the City',
'Enter the Void'
]};
console.log(ejs.render(template, context));
11.2.2.2 处理大小写的过滤器
capitalize 首字母大写upcase 全大写downcase 全小写
11.2.2.3 处理文本的过滤器
truncate切割文本字符串truncate_words 切割文本单词1
2
3
4//把标题截成只有20个字符的**字符串**
<%=: title | truncate:20 %>
//把标题截成只有2个单词
<%=: title | truncate_words:2 %>
replace底层用的是 String.prototype.replace(pattern) ,所以它可以接受字符串或正则表达式。1
<%=: weight | replace:'kilogram','kg' %>
11.2.2.4 排序的过滤器
按字母顺序1
2
3
4//按字母顺序--当movies是数组
<%=: movies | sort | first %>
//按字母顺序--当movies是数组
<%=: movies | sort_by:'name' | first | get:'name' %>
注意过滤器链最后的 get:’name’ 。因为 sort 返回的是对象,而你还要选择显示对象的哪个属性。
11.2.2.5 过滤器map
对于前面那个例子而言,你也可以在过滤器链中使用 map 。
你不必非得用 sort_by 指定属性,然后再用 get 指定要显示的属性。
你可以用 map 创建一个包含对象属性的数组。1
<%=: movies | map: 'name' | sort | first %>
11.2.2.6 创建定制的过滤器
例子:对小数位做四舍五入的过滤器1
2
3
4
5
6
7
8
9
10var ejs = require('ejs');
var template = '<%=: price * 1.145 | round:2 %>';
var context = {price: 21};
ejs.filters.round = function(number, decimalPlaces) { //在 ejs.filters 对象上定义一个函数
number = isNaN(number) ? 0 : number;
decimalPlaces = !decimalPlaces ? 0 : decimalPlaces;
var multiple = Math.pow(10, decimalPlaces);
return Math.round(number * multiple) / multiple;
};
console.log(ejs.render(template, context));
11.2.3 将EJS集成到你的程序中
把模板代码放在独立文件中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24var ejs = require('ejs');
var fs = require('fs');
var http = require('http');
var filename = './template/students.ejs'; //模板引擎的位置
var students = [ //传给引擎的数据
{name: 'Rick LaRue', age: 23},
{name: 'Sarah Cathands', age: 25},
{name: 'Bob Dobbs', age: 37}
];
var server = http.createServer(function(req, res) { //创建一个服务器
if (req.url == '/') {
fs.readFile(filename, function(err, data) { //从文件中读取模板
var template = data.toString();
var context = {students: students};
var output = ejs.render(template, context); //渲染模板
res.setHeader('Content-type', 'text/html');
res.end(output); //发送http响应
});
} else {
res.statusCode = 404;
res.end('Not found');
}
});
server.listen(8000);
EJS模板写法
1 | <% if (students.length) { %> |
缓存EJS模板
也就是说在EJS中,解析完模板文件后,可以把解析得到的函数存下来。因为可以跳过解析步骤,所以渲染缓存的模板速度更快。
如果是Node程序的初步开发,并且你想马上看到修改的效果,可以不启用缓存。
但在把程序部署到生产环境中时,启用缓存是一种简单快捷的制胜之道。
你可以通过环境变量 NODE_ENV 设定是否启用缓存的条件。
如果你想尝试一下缓存机制,将前面的 render 函数调用改成下面这样:1
2
3
4
5var cache = process.env.NODE_ENV === 'production';
var output = ejs.render(
template,
{students: students, cache: cache, filename: filename} //后边多了cache和filename
);
其中的选项 filename 不一定必须是文件——你可以用你要渲染的模板的唯一标识。
在客户端程序中使用EJS
代码:用EJS给客户端增加使用模板的能力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<html>
<head>
<title>EJS example</title>
<script src="ejs.js"></script>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.8/jquery.js"></script>
</head>
<body>
<div id='output'></div> //用来渲染模板输出的占位标签
<script>
var template = "<%= message %>"; //渲染内容用的模板
var context = {message: 'Hello template!'}; //用在模板中的数据
$(document).ready(function() { //等着浏览器加载数据
$('#output').html(
ejs.render(template, context) //将模板渲染到ID为"output" 的div中
);
});
</script>
</body>
</html>
其他模板待更新···
12 部署Node程序并维持正常运行时间
专用服务器;
虚拟私有服务器(VPS);
通用的云服务器。
专用服务器(普通电脑) > 云主机(可自行创建多个vps) > VPS(类似一个虚拟机) > 虚拟主机(只是一个文件夹)
12.2.2 让Node保持运行
Forever:在你断开SSH连接后让程序保持运行状态, 在程序崩溃退出后还能重启它。
安装:1
sudo npm install -g forever
用forever启动程序1
forever start server.js
用forever停止程序1
forever stop server.js
获取forever管理的程序清单1
forever list
当有源码文件发生变化时,可以让它重启程序1
forever -w start server.js
12.3 让正常运行时间和性能达到最优
如果只用一个核,并且Web程序流量增长显著,单核可能没有足够的能力来处理这些流量,Web程序也不能做出稳定的响应。
除了用上所有的CPU内核,对于高容量的生产型站点而言,还要避免用 Node传送静态文件。
Node主要是面向交互性程序的,比如Web程序和TCP/IP协议,它提供静态文件服务的效率不如那些专门为此进行优化的软件。
处理静态文件可以用Nginx或者CDN。
以下介绍性能优化:
用Upstart保持程序的运行状态,能跨越服务器的重启和崩溃;
借助Node的集群API利用多核处理器;
借助Nginx提供Node程序的静态文件服务。
12.3.1 用Upstart维护正常运行时间
Upstart可以优雅地管理所有Linux程序的启动和停止,一般用在服务器重启后,让你的node程序自动启动
安装:1
2
3
4//ubuntu
sudo apt-get install upstart
//centos
sudo yum install upstart
具体配置待更新···
12.3.2 集群API:利用多核的优势 –多个人干一样的工作
为了让单个程序使用多核实现起来更容易,Node增加了集群(cluster)API。
借助这个API,程序可以在不同的内核上同时运行多个“工人” ,每个“工人”做的都是相同的事情,
并且是在同一个TCP/IP端口上返回响应。
例子:Node集群API演示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length; //确定服务器的内核数
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork(); //每个内核创建一个fork
}
cluster.on('exit', function(worker, code, signal) {
console.log('Worker ' + worker.process.pid + ' died.');
});
} else {
http.Server(function(req, res) { //定义每个工人的工作
res.writeHead(200);
res.end('I am a worker running in process ' + process.pid);
}).listen(8000);
}
主进程和工人运行在各自的进程内,所以它们不能通过全局变量共享状态。
但集群API提供了一种让主进程和工人彼此相互通信的办法。
下面的代码清单是一个在主进程和工人之间传送消息的例子。主进程会持有所有请求的计数,并且只要有工人报告处理了请求,它就会被传递给所有工人。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
var workers = {};
var requests = 0;
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
workers[i] = cluster.fork();
(function (i) {
workers[i].on('message', function(message) { //监听来自工人的消息
if (message.cmd == 'incrementRequestTotal') {
requests++;
for (var j = 0; j < numCPUs; j++) {
workers[j].send({ //将新的请求总数发送给所有工人
cmd: 'updateOfRequestTotal',
requests: requests
});
}
}
});
})(i); //用闭包保留工人的值
}
cluster.on('exit', function(worker, code, signal) {
console.log('Worker ' + worker.process.pid + ' died.');
});
} else {
process.on('message', function(message) { //监听来自主进程的消息
if (message.cmd == 'updateOfRequestTotal') {
requests = message.requests; //用主进程的消息更新请求计数
}
});
http.Server(function(req, res) {
res.writeHead(200);
res.end('Worker in process ' + process.pid
+ ' says cluster has responded to ' + requests
+ ' requests.');
process.send({cmd: 'incrementRequestTotal'}); //让主进程知道请求总数应该增加了
}).listen(8000);
}
12.3.3 静态文件及代理
Nginx(http://nginx.org/en/)是一个专门**针对静态文件服务**做过优化的开源Web服务器
在典型的Nginx/Node配置中,一般由Nginx先处理所有Web请求,再将非静态文件的请求转给Node。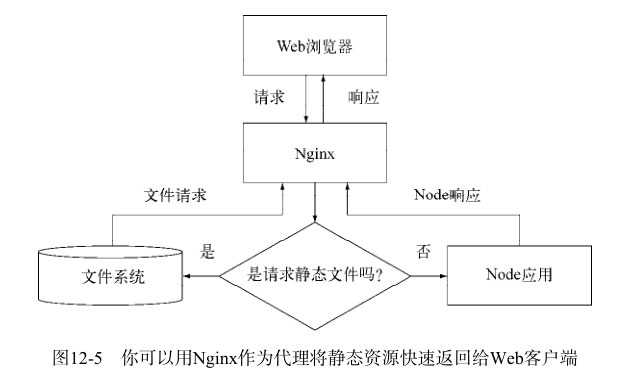
下面的配置代码实现了这种设置,它应该被放在Nginx配置文件的 http 部分。
按照传统,这个配置文件应该是Linux /etc目录下的/etc/nginx/nginx.conf文件。
1 | http { |
13 超越Web服务器
13.1 Socket.IO
Socket.IO在基于Web的浏览器游戏、聊天程序和流媒体应用中非常流行。
HTTP是无状态协议,也就是说客户端只能向服务器发起单个的、短命的请求,并且服务器也没有真正意义上的已连接的或断开连接的用户。
13.1.1 创建一个最小的Socker.IO程序
例:用自己的时间更新客户端的Socket.IO服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var app = require('http').createServer(handler);
var io = require('socket.io').listen(app); //将普通的HTTP服务器升级为Socket.IO服务器
var fs = require('fs');
var html = fs.readFileSync('index.html', 'utf8');
function handler (req, res) {
res.setHeader('Content-Type', 'text/html');
res.setHeader('Content-Length', Buffer.byteLength(html, 'utf8'));
res.end(html);
}
function tick () {
var now = new Date().toUTCString(); //取得当前时间的UTC表示
io.sockets.send(now); //将时间发送给所有连接上来的客户端
}
setInterval(tick, 1000); //每秒运行一次 tick 函数
app.listen(8080); //app来监听端口
Socket.IO将需要额外添加到基本HTTP服务器上所需的代码量降到了最低。
下边是:显示服务器广播时间的Socket.IO客户端1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!DOCTYPE html>
<html>
<head>
<script type="text/javascript" src="/socket.io/socket.io.js">
</script>
<script type="text/javascript">
var socket = io.connect();
socket.on('message', function (time) {
document.getElementById('time').innerHTML = time;
});
</script>
</head>
<body>Current server time is: <b><span id="time"></span></b>
</body>
</html>
13.1.2 用Socket.IO触发页面和CSS的重新加载
需要:Socket.IO跟Node的 fs.watchFile 和 fs.watch 函数配合
代码:在文件改变时触发事件的Express/Socket.IO服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36var fs = require('fs');
var url = require('url');
var http = require('http');
var path = require('path');
var express = require('express');
var app = express();
var server = http.createServer(app); //创建http服务器
var io = require('socket.io').listen(server); //包装HTTP服务器创建Socket.IO实例
var root = __dirname;
app.use(function (req, res, next) { //用中间件开始监测 由 static 中间件 返回的文件
req.on('static', function () { //注册由 static() 中 间 件 发 射 的 static 事件
var file = url.parse(req.url).pathname;
var mode = 'stylesheet';
if (file[file.length - 1] == '/') {
file += 'index.html';
mode = 'reload';
}
createWatcher(file, mode);
});
next();
});
app.use(express.static(root)); //将服务器设置为基本的静态文件服务器
var watchers = {}; //保存被监测的活动文件清单
function createWatcher (file, event) {
var absolute = path.join(root, file);
if (watchers[absolute]) {
return;
}
fs.watchFile(absolute, function (curr, prev) {
if (curr.mtime !== prev.mtime) { //检查 mtime ( 最后修改时间)是否有变化; 如果变了, 激发Socket.IO事件
io.sockets.emit(event, file); //激发reload
}
});
watchers[absolute] = true;
}
server.listen(8080);
你有了功能完备的静态文件服务器,可以准备好用Socket.IO通过网络向客户端激发 reload和 stylesheet 事件。
客户端代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39<!DOCTYPE html>
<html>
<head>
<title>Socket.IO dynamically reloading CSS stylesheets</title>
<link rel="stylesheet" type="text/css" href="/header.css" />
<link rel="stylesheet" type="text/css" href="/styles.css" />
<script type="text/javascript" src="/socket.io/socket.io.js">
</script>
<script type="text/javascript">
window.onload = function () {
var socket = io.connect();
socket.on('reload', function () {
window.location.reload();
});
socket.on('stylesheet', function (sheet) {
var link = document.createElement('link');
var head = document.getElementsByTagName('head')[0];
link.setAttribute('rel', 'stylesheet');
link.setAttribute('type', 'text/css');
link.setAttribute('href', sheet);
head.appendChild(link);
});
}
</script>
</head>
<body>
<h1>This is our Awesome Webpage!</h1>
<div id="body">
<p>If this file (<code>index.html</code>) is edited, then the
server will send a message to the browser using Socket.IO telling
it to refresh the page.</p>
<p>If either of the stylesheets (<code>header.css</code> or
<code>styles.css</code>) are edited, then the server will send a
message to the browser using Socket.IO telling it to dynamically
reload the CSS, without refreshing the page.</p>
</div>
<div id="event-log"></div>
</body>
</html>
这个例子中的 reload 和 stylesheet 是你在程序中定义的定制事件,它们不是Socket.IO的
API。 这阐明了如何把 socket 对象当作双向 EventEmitter , Socket.IO会通过网络帮你传输激发
的事件。
13.2 深入 TCP/IP 网络
Buffer 数据类型,这是一块长度固定的二进制数据,有了它在实现其他协议时就可以访问底层二进制数据了。
13.2.1 处理缓冲区和二进制数据
你可以把缓冲区看做C中的 malloc() 函数或C++中的关键字 new 。缓冲区既快又轻,广泛应用在
Node的核心API中。比如说,所有的 Stream 类返回的 data 事件中默认都会包含它们。
从编程的角度来看,你可以把缓冲区看做数组,只是它们的大小是固定的,并且只能存放数字0到255。
Node中还有用来读写二进制(机器可读)整型数据的辅助函数。
writeInt32LE() 将数值121234869作为机器可读的二进制整型
writeInt16LE() 用于较小的整型值;
writeUInt32LE() 用于无符号值;
writeInt32BE() 用于大尾数值。
1 | var b = new Buffer("121234869"); |
把值作为二进制整型而不是文本字符串存在内存中,数据的大小减了一半
13.2.2 创建TCP服务器
net模块基本上就是Node核心基础的展示。
email用的SMTP,传输文件用的FTP,也需要以net为基础实现
13.2.2.1 写数据
net 模块提供了一个原始的TCP/IP socket接口。
创建TCP服务器需要调用 net.createServer()
读取会发出 data 事件,发送输出数据时它有 write() 和 end() 函数。
简单例子:1
2
3
4
5
6var net = require('net');
net.createServer(function (socket) {
socket.write('Hello World!\r\n');
socket.end();
}).listen(1337);
console.log('listening on port 1337');
浏览器不支持这个协议,所以无法连接,需要用合适的TCP客户端连接,比如
netcat(1) :1
2$ node server.js
listening on port 1337
telnet(1):1
2
3
4
5
6$ telnet localhost 1337
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello World!
Connection closed by foreign host.
13.2.2.2 读取数据
跟可读取的 Stream 接口一样,你只需要监听 data 事件,这个事件中就有从socket中读出来的数据:1
2
3socket.on('data', function (data) {
console.log('got "data"', data);
});
socket上默认没有设定编码,所有参数 data 应该是 Buffer 的实例。
通常这就是你想要的(所以是默认值) ,但你可以调用 setEncoding() 函数,让参数 data 变成被解码的字符串而不是缓冲区很方便。1
2
3
4
5
6
7var net = require('net');
var socket = net.connect({ host: process.argv[2], port: 22 });
socket.setEncoding('utf8');
socket.once('data', function (chunk) {
console.log('SSH server version: %j', chunk.trim());
socket.end();
});
13.2.2.3 用 socket.pipe() 连接两个流
把所有发给它的东西返回给客户端,在回调函数里用一行代码就能搞定:1
socket.pipe(socket);
通常会用更有意义的 stream 实例,比如文件系统或gzip流。
13.2.2.4 处理不干净的断开
当你按下杀掉进程,而不是Ctrl-D**干净地关闭连接时就会出现这种情况。
为了检测这种情况,你需要监听 close 事件:1
2
3socket.on('close', function () {
console.log('client disconnected');
});
应该在 close 事件中完成,而不是在 end 事件中,因为如果不是干净的关闭连接,不会激发 end 事件。
13.2.2.5 全拼到一起
创建一个简单的echo服务器, 把收到的所有数据返回给客户端的简单TCP服务器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var net = require('net');
net.createServer(function (socket) {
console.log('socket connected!');
socket.on('data', function (data) {
console.log('"data" event', data);
});
socket.on('end', function () {
console.log('"end" event');
});
socket.on('close', function () {
console.log('"close" event');
});
socket.on('error', function (e) {
console.log('"error" event', e);
});
socket.pipe(socket); //返给客户端
}).listen(1337);
13.2.3 创建TCP客户端 (HTTP就是爬虫)
创建到TCP服务器的原始连接关键是 net.connect() 函数
它可以接受一个指定 host 和 port 值的配置项参数,并返回一个 socket 实例。
net.connect() 返回的 socket 开始并没有连到服务器上,所以一般在你用socket做什么事情之前要监听 connect 事件:1
2
3
4
5
6
7var net = require('net');
var socket = net.connect({ port: 1337, host: 'localhost' });
socket.on('connect', function () {
// begin writing your "request"
socket.write('HELO local.domain.name\r\n');
...
});
例子:用Node实现 netcat(1) 命令的简单复制品1
2
3
4
5
6
7
8
9
10
11
12var net = require('net');
var host = process.argv[2];
var port = Number(process.argv[3]); //从命令行参数中解析出主机和端口
var socket = net.connect(port, host); //创建 socket 实例并开 始连接服务器
socket.on('connect', function () { //到服务器的连接建立好 后处理 connect 事件
process.stdin.pipe(socket); //将进程的stdin传给socket
socket.pipe(process.stdout); //将 socket 的 数据传给进 程的stdout
process.stdin.resume(); //在stdin上调用 resume() , 开始读取数据
});
socket.on('end', function () {
process.stdin.pause(); //当发生 event 事件 时中断stdin
});
13.3 跟操作系统交互的工具
Node的一些核心API:
全局的 process 对象——包含当前进程的相关信息,比如传给它的参数和当前设定的环境变量;
fs 模块——包含高层的 ReadStream 和 WriteStream 类,你现在应该已经掌握了,但还有我们即将介绍的底层函数;
child_process 模块——繁衍子进程的底层和高层接口,以及一种繁衍带有双向消息传递通道node实例的特殊办法。
13.3.1 单例的全局 process 对象
process.argv访问Node运行当前脚本时传入的参数process.env 对象获取或设定环境变量。
process对象并不是 EventEmitter 实例
监听 process 发出的特殊事件,比如 exit 和 uncaughtException ;
监听 process 发出的单例事件,比如 SIGUSR2 和 SIGKILL 。
13.3.1.1 用 process.env 获取和设定环境变量
可以配置环境变量,指定它监听的端口。
或者启动debug模式
代码:根据环境变量DEBUG定义 debug 函数1
2
3
4
5
6
7
8
9
10
11var debug;
if (process.env.DEBUG) { //根据环境变量DEBUG定义 debug 函数
debug = function (data) { //如果设定了DEBUG, debug 函数会将参数输出到 stderr 中
console.error(data);
};
} else {
debug = function () {}; //如果没设定DEBUG, debug函数为空,什么也不做
}
debug('this is a debug call'); //在代码中各处调用 debug 函数
console.log('Hello World!');
debug('this another debug call');
在启动Node实例时在命令前加上 DEBUG=1 。1
$ DEBUG=1 node debug-mode.js
社区模块debug (https://github.com/visionmedia/debug)封装了这一功能,还有些其他特性。
13.3.1.2 进程发出的特殊事件
process 对象通常会发出两个特殊事件:
进程退出之前发出的exit;
有未处理的错误被抛出时发出的uncaughtException。
要在退出前完成某些任务(比如清理对象或向控制台输出最后一条消息)的程序来说, exit 事件是必不可少的。1
2
3process.on('exit', function (code) {
console.log('Exiting...');
});
uncaughtException 事件只有一个参数,未捕获的 Error 对象。
如果没有“错误”事件的监听器,任何未捕获的错误都会搞垮进程
Node.js文档明确指出,使用这个事件时应该在回调中包含
process.exit() ;否则会让程序处于不确定的状态中,这很糟糕。
例子:对 uncaughtException 的监听,并抛出一个未捕获的错误:1
2
3
4process.on('uncaughtException', function (err) {
console.error('got uncaught exception:', err.message);
process.exit(1); //必须包含
});
13.3.1.3 捕获发送给进程的信号
UNIX有信号的概念,是进程间通信(IPC)的基本形式。
这些信号非常原始,只能使用一组固定的名称,并且不能传递参数。
SIGINT 在按下Ctrl-C时由shell发送。Node的默认行为是杀掉进程,但该行为可以由进程上SIGINT的单例监听器覆盖;
SIGUSR1 收到这个信号时,Node会进入它内置的调试器;
SIGWINCH 在调整终端大小时由shell发送。收到这个信号时,Node会重新设定process.stdout.rows 和 process.stdout.columns ,并发出一个 resize 事件。
可以在 process 对象上监听这些信号,调用回调函数。
假设你写了个服务器,但在你按下Ctrl-C要杀掉服务器时,这种关闭不干净,并且所有等待中的连接都会被丢掉。解决办法是捕获 SIGINT 信号并阻止服务器接受连接,并在结束进程之前完成所有已有连接的处理。1
2
3
4process.on('SIGINT', function () {
console.log('Got Ctrl-C!');
server.close(); //阻止杀死进程,只让其退出并关闭进程就可以了
});
现在按Ctrl-C键,会从你的shell向Node进程发送 SIGINT 信号,从而调用你注册的回调而不是杀掉进程。
13.3.2 使用文件系统模块
fs模块提供了跟文件系统交互的函数。其中的大多数都有一一对应的C函数,但也有像fs.readFile() 、 fs.writeFile() 、 fs.ReadStream 和 fs.WriteStream 类这样的高层抽象,
它们构建在 open() 、 read() 、 write() 和 close() 之上。fs.stat() 和 fs.statSync() 是C函数 stat(2) 的底层绑定。
13.3.2.1 移动文件
根本没有 fs.move() 函数
但有一个 fs.rename() 函数,如果你仔细想想,它们是一样的。完美!
fs.rename() 直接对应C函数 rename(2) ,这个函数有个怪毛病,它不能跨越物理设备(比如两个硬盘) 。
解决办法:用 fs.ReadStream 和 fs.WriteStream 把文件从一个设备复制到另一个设备中
代码实现:可能时重命名,并以复制为后备手段的 move() 函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24var fs = require('fs');
module.exports = function move (oldPath, newPath, callback) {
fs.rename(oldPath, newPath, function (err) { //调用 fs.rename() 并希望它能用
if (err) {
if (err.code === 'EXDEV') { //如果出现EXDEV错误,用备用的复制技术
copy(); //执行复制操作
} else {
callback(err); //callback是自定义的回调函数
}
return;
}
callback();
});
function copy () {
var readStream = fs.createReadStream(oldPath);
var writeStream = fs.createWriteStream(newPath);
readStream.on('error', callback);
writeStream.on('error', callback);
readStream.on('close', function () {
fs.unlink(oldPath, callback);
});
readStream.pipe(writeStream);
}
}
这个 copy 函数只能用在文件上,目录不行。要支持目录复制,你必须先检查给定的
路径是否为目录,如果是,则调用 fs.readdir() ,必要时还要调用 fs.mkdir() 。
13.3.2.2 监测目录或文件的变化
fs.watchFile() 很早就出现了。因为它用轮询的方式检查文件是否发生了变化,所以在某
些平台上很耗资源。也就是说,它 stat() 文件,在短暂的等待之后再次 stat() ,就这样一直循
环,在文件发生变化时就调用监测者函数。
例子:监听system.log文件被修改时可以调用的函数:1
2
3
4
5
6var fs = require('fs');
fs.watchFile('/var/log/system.log', function (curr, prev) {
if (curr.mtime.getTime() !== prev.mtime.getTime()) {
console.log('"system.log" has been modified');
}
});
变量 curr 是当前的 fs.Stat 对象, prev 是前一个 fs.Stat 对象, 它俩应该有同一个文件上的不同时间戳。
这个例子中比较了 mtime 的值,因为你只想在文件被修改时收到通知,而不是在它被访问时。fs.watch() 是用平台本地的文件修改通知API监测文件,所以它比 fs.watchFile() 性能更优。
13.3.2.3 使用社区模块:fstream和filed
fstream模块(https://github.com/isaacs/fstream)是npm自身的一个核心组件。
让fstream脱颖而出的优秀特性之一是它对许可权限和符号链接的处理,在复制文件和目录时是默认维护的。
借助fstream,只需将 Reader 实例接到 Writer 实例上,就可以达到执行 cp -rp 源目录 目标目录(递归地复制一个目录及其中的内容,并传送所有权和授权许可)的效果。
在下面这个例子中,我们用fstream的过滤器功能基于回调函数按条件排除文件:1
2
3
4
5
6
7
8fstream
.Reader("path/to/dir") //读
.pipe(fstream.Writer({ path: "path/to/other/dir", filter: isValid ) //写
// 检查即将写入的文件并返回它是否应该被复制
function isValid () {
// 忽略TextMate之类的文本编辑器创建的临时文件
return this.path[this.path.length - 1] !== '~';
}
filed模块(https://github.com/mikeal/filed)
这些模块让一种新的流程控制变得比 Stream实例更流行:监听 pipe 事件,然后基于传给它的东西(或它传出去的东西)执行不同的动作。
为了演示这种方式的强大之处,我们来看一下filed如何将普通的HTTP服务器变成一个功能完备的静态文件服务器,只要一行代码:1
2
3http.createServer(function (req, res) {
req.pipe(filed('path/to/static/files')).pipe(res);
});
这段代码会跟着正确的缓存头发送 Content-Length 。
如果浏览器已经缓存了文件,field会用304未修改响应HTTP请求,不再从硬盘中打开文件读取它。
这些优化就是基于 pipe 事件才能做的,因为 filed 实例*能访问**HTTP请求的 req 和 res 对象。
13.3.3 繁衍外部进程
Node提供了child_process模块,在Node服务器或脚本内创建子进程。
这里有两个API:一个高层的 exec() 和一个底层的 spawn() 。
还有一种创建Node自身子进程的特殊办法,用内置的特殊IPC通道fork()。
cp.exec() ——在回调中繁衍命令并缓冲结果的高层API;
cp.spawn() ——将单例命令繁衍进Child-Process对象中的底层API;
cp.fork() ——用内置的IPC通道繁衍额外Node进程的特殊办法。
子进程的好与坏:
一个明显的缺点是需要执行装在用户机器上的程序,你的应用要依赖于它。
另一方面,使用外部程序让开发者可以借用由其他语言编写的丰富应用。
我只学习了fork(),因为其他的完全看不懂,啊哈哈哈哈
13.3.3.3 用 cp.fork() 分散工作负载
cp.fork()是用一种特殊的方式繁衍额外的Node进程,用特殊的内置IPC通道。
主要区别是这个API是用IPC通道添加的:子进程现在有一个 child.send(message) 函数,并且用 fork() 调用的脚本能够监听 process.on(‘message’) 事件。
cp.fork()提供了 child.send() 和 child.on('message') 来向子进程发送和接收消息。
在子进程中,你可以用 process.send() 和 process.on('message') 向父进程发送和接收消息。
代码:用Node.js实现的非最优斐波那契数列HTTP服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14var http = require('http');
function fib (n) {
if (n < 2) {
return 1;
} else {
return fib(n - 2) + fib(n - 1);
}
}
var server = http.createServer(function (req, res) {
var num = parseInt(req.url.substring(1), 10);
res.writeHead(200);
res.end(fib(num) + "\n");
});
server.listen(8000);
下边是通过子进程改进后的1
2
3
4
5
6
7
8
9var http = require('http');
var cp = require('child_process');
var server = http.createServer(function(req, res) {
var child = cp.fork(__filename, [ req.url.substring(1) ]);
child.on('message', function(m) { //向子进程接收
res.end(m.result + '\n');
});
});
server.listen(8000);
用 process.send() 向父进程返回报告1
2
3
4
5
6
7
8
9function fib(n) {
if (n < 2) {
return 1;
} else {
return fib(n - 2) + fib(n - 1);
}
}
var input = parseInt(process.argv[2], 10);
process.send({ result: fib(input) }); //向父进程发送
13.4 开发命令行工具
解析命令行参数,读取stdin,写入stdout和stderr。
13.4.1 解析命令行参数
process.argv 属性,解析命令行为一个字符串数组,第一项是可执行的Node,第二项是脚本的名称。
大部分情况下你都不会关心数组的前两项,所以可以在处理之前把它们 slice() 掉:1
2var args = process.argv.slice(2);
console.log(args);
按照UNIX的惯例,对于选项 -h 和 --help ,每个命令行程序都应该输出使用指南作为响应然后退出。
代码:用Array.forEach()和switch块解析process.argv1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var args = process.argv.slice(2); //切掉头两项, 你不会对 它们感兴趣的
args.forEach(function (arg) { //循环遍历参数,查找-h和--help
switch (arg) {
case '-h':
case '--help':
printHelp();
break; //在这里添加必要的选项开关
}
});
function printHelp () { //输出帮助信息,然后退出
console.log(' usage:');
console.log(' $ AwesomeProgram <options> <file-to-awesomeify>');
console.log(' example:');
console.log(' $ AwesomeProgram --make-awesome not-yet.awesome');
process.exit(0);
}
13.4.2 处理stdin和stdout
UNIX程序通常都是小型、自包含并专注于单一任务的。
然后通过管道组合起来,将前一个处理结果交给下一个,直到命令链的末端。
比如说,用标准的 UNIX命令从给定的Git库中获取唯一作者的清单,
可以将 git log 、 sort 和 uniq 命令像下面这样组合起来:1
$ git log --format='%aN' | sort | uniq //会依次执行
Node提供了两个 Stream 对象供你的命令行程序处理:
process.stdin ——读输入数据的 ReadStream ;
process.stdout ——写输出数据的 WriteStream 。
13.4.2.1. 用 process.stdout 写输出数据
你每次调用 console.log() 时已经隐含着对 process.stdout 可写流的使用了。
当你需要将结构化的数据写到stdout中时,可以直接调用 process.stdout.write() 。
假定你的程序连上一个HTTP URL,把响应写到stdout中。 Stream.pipe() 在这种情况下很好用,代码如下所示:1
2
3
4
5
6var http = require('http');
var url = require('url');
var target = url.parse(process.argv[2]);
var req = http.get(target, function (res) {
res.pipe(process.stdout); //写到stdout中
});
13.4.2.2用 process.in 读取输入数据
在从stdin中读取数据之前,你必须调用 process.stdin.resume() 表明你的脚本想从stdin中读取数据。
代码:一个提示用户输入年龄的限制年龄的程序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var requiredAge = 18; //设定年龄限制
process.stdout.write('Please enter your age: '); //指定用户要回答的问题
process.stdin.setEncoding('utf8'); //设置stdin, 以便输出UTF-8编 码的字符串, 而不是直接输出 缓冲区中的内容
process.stdin.on('data', function (data) { //监听传入事件
var age = parseInt(data, 10); //将数据解析为数值
if (isNaN(age)) { //如果用户输入的不是有效的数值,输出一条消息提示
console.log('%s is not a valid number!', data);
} else if (age < requiredAge) { //如果用户给出的年龄不到18,输出一条消息说几年之后再回来
console.log('You must be at least %d to enter, ' +
'come back in %d years',
requiredAge, requiredAge - age);
} else {
enterTheSecretDungeon(); //如果前面的条件满足了, 继续执行
}
process.stdin.pause(); //关闭stdin之前,等待一个data事件
});
process.stdin.resume(); //因为process.stdin开始处于暂停状态,所以调用resume()开始读取输入
function enterTheSecretDungeon () {
console.log('Welcome to The Program :)');
}
13.4.2.3 用 process.stderr 诊断日志
它的表现跟 process.stdout流一样,只是它是写到stderr中的。
一般都不会直接访问 process.stderr ,而是使用 console.error() 。
14 Node生态系统
14.3 为 npm 库做贡献
我将这部分放到了npm常用命令大全内
附录B 调试Node
B.1 用JSHint分析代码
1 | jshint my_app.js |
B.2 输出调试信息
B.2.1 用console模块调试
都写在高性能里了,这里就不赘述了
B.2.2 用debug模块管理调试输出
T. J. Holowaychuk的debug模块为此提供了一个便利的工具,允许你用环境变量 DEBUG 管理调试信息的输出。
B.3 Node内置的调试器
Node还自带了一个命令行的调试器。用debug 关键字启动程序可以启用这个调试器,比如:1
node debug server.js
B.3.1 调试器导览
输入 next (或只输入 n )执行下一行代码。
输入 cont (或只输入 c )让它一直执行,直到被中断。
输入 step ,调试器则会进入 当前 函数中,以便你可以跟踪这个函数中的任何问题。
输入 out (或 o )跳出这个函数。
也可以在代码中直接添加debugger
在调试器中也可以设定断点。
要把断点设定在调试器中的当前行,在调试器中输入 setBreakpoint() 或 sb() 。
在特定行设定断点也是可以的sb( 行号 )
把断点设定在执行特定函数时sb('fn()')。
取消断点时,可以用 clearBreakpoint() 或 cb() 。
B.3.2 调试器中状态的检查及处理
查看浏览器发出的请求类型是什么1
watch("req.headers['user-agent']")
查看观测器的列表-watchers1
watchers
移除观测器- unwatch1
unwatch("req .headers['user- agent']")
B.4 Node检查器
基于Webkit的浏览器,比如Chrome或Safari,而不是命令行作为界面。
B.4.1 Node检查器入门
注意:node最新版已经植入检查器,所以这个已经不再更新,推荐自带检查器
全局安装Node检查器1
npm install -g node-inspector
用命令行选项 --debug-brk 启动它:1
node --debug-brk server.js
--debug-brk 选项会让调试在程序的第一行代码前插入一个断点。
如果你不想这样,可以用 --debug 。
程序运行起来后,启动Node检查器:1
node-inspector
Node检查器运行起来后,在你的WebKit浏览器中转到 http://127.0.0.1:8080/debug?port=5858 中,你应该可以看到Node检查器了。
剩下的就是浏览器的调试界面了~
当红箭头出现在函数调用左边时,你可以点击那个有箭头向下指向小圆点的按钮跟到函数里面。要跳出这个函数,
报错解决:
Node版本过高,推荐7.9.0
未安装Python,推荐2.7,不支持3.01
2npm install --python=python2.7
npm config set python python2.7
B.5 新版Node自带debugger
不同版本使用方法不同,参考文档1
2
3node --inspect index.js
// 第一行就开始
node --inspect-brk ../index.js
访问:chrome-devtools://…开头的链接,控制台会展示具体链接
node 8.1.2
访问:chrome-devtools://devtools/bundled/inspector.html?experiments=true&v8only=true&ws=127.0.0.1:9229/88f081dd-3cb6-49cd-bb04-7ba7f9ba1bb2
chrome-devtools://devtools/bundled/inspector.html?experiments=true&127.0.0.1:8164/c6b5ae0d-78d2-48ac-8316-79a706f03fdd
提示:
最好都打上–inspect-brk,因为如果不打上这个。
如果你打开debug url比较慢的话 程序已经运行完了,是无法在debugger出停止的
Express的扩展及配置
C.1 扩展Express
C.1.1 注册模板引擎
app.engine() 方法将文件扩展名对应到回调函数上,以便Express知道如何使用它。
代码:小型的markdown模板引擎,并且可以用变量替换动态内容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var express = require('express');
var http = require('http');
var md = require('github-flavored-markdown').parse; //引入一个markdown实现
var fs = require('fs');
var app = express();
app.engine('md', function(path, options, fn){ //将这个回调函数对应到.md 文件上
fs.readFile(path, 'utf8', function(err, str){ //读取文件中的内容, 作为字符串变量
if (err) return fn(err); //将错误转给Express
try {
var html = md(str); //将markdown字符串转换成HTML
html = html.replace(/\{([^}]+)\}/g, function(_, name){ //执行大括号替换
return options[name] || ''; //默认值为''(空字符串)
});
fn(null, html); //将渲染好的HTML传给Express
} catch (err) {
fn(err); //捕获所有抛出来的错误
}
});
});
C.1.2 consolidate.js模板
它为很多Node模板引擎提供了一个统一API
你可能想让HTML风格的引擎使用 .html 作模板的扩展名,而不是使用引擎的名称,比如 .swig 。1
2var cons = require('consolidate');
app.engine('html', cons.swig);
EJS模板引擎很可能也会被对应到.html上1
2var cons = require('consolidate');
app.engine('html', cons.ejs);
Jade可能会用下面这些调用做对应:1
2var cons = require('consolidate');
app.engine('jade', cons.jade);
C.1.3 Express的扩展及框架
EXPRESS-EXPOSE
用express-expose插件可以把服务器端的JavaScript对象导到客户端。1
res.expose(req.user, 'express.user');
EXPRESS-RESOURCE
用来对路由做结构化处理的、资源丰富的路由插件。
C.2 高级配置
C.2.1 操作JSON响应
配置项 json replacer 会让Express在调用 res.send() 和 res.json() 的过程中传给 JSON.stringify() 一个函数。
代码:用这个函数在JSON响应中忽略以 “_”开头的属性。1
2
3
4
5
6
7
8
9
10
11var express = require('express');
var app = express();
app.set('json replacer', function(key, value){
if ('_' == key[0]) return;
return value;
});
var user = { _id: 123, name: 'Tobi' };
app.get('/user', function(req, res){
res.send(user);
});
app.listen(3000);
JSON.stringify() 在将对象转换成JSON字符串时使用这个方法。
C.2.2 JSON响应格式
配置项 json spaces 会影响Express中的 JSON.stringify() 调用。
这个设定表明在将JSON格式化为字符串时用多少空格。
配置项 json spaces 在生产环境中会自动设为0。在开发环境中设为2,会产生下面这种输出:1
2
3
4
5{
"name": "Tobi",
"age": 2,
"species": "ferret"
}
C.2.3 信任反向代理头域
默认情况下, Express内部在任何环境中都不会信任反向代理头域。
如果你的程序运行在反向代理后面,比如Nginx、HAProxy或Varnish,
你就需要启用trust proxy ,这样Express才知道查询这些域是安全的。
补充:
dirname: 获得当前执行文件所在目录的完整目录名
filename: 获得当前执行文件的带有完整绝对路径的文件名
process.cwd():获得当前执行node命令时候的文件夹目录名
./: 文件所在目录1
2
3
4
5
6
7
8
9
10const path = require('path')
console.log('__dirname:', __dirname)
console.log('__filename:', __filename)
console.log('process.cwd():', process.cwd())
console.log('./:', path.resolve('./'))
// 结果
__dirname: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
__filename: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs/2.path.js
process.cwd(): /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
./: /Users/jawil/Desktop/nodejs/demo/ES6-lottery/syntax/nodejs
性能分析监控
Easy-Monitor
杀node进程
1 | sudo lsof -i:8081 #查看端口为8081的pid |